






机器学习理论知识要点总结-线性回归和逻辑回归
作者本是一个转行机器学习的小白,在七月在线学习,接触了一系列机器学习中的模型、参数、算法等内容,现在还不是拎得很清楚,所以收集资料写此博客。旨在加深对算法及优化方法,损失函数及参数的理解。
线性模型:
线性模型形式简单,易于建模,但却蕴含着机器学习中一些重要的基本思想。许多功能更为强大的非线性模型(nonlinear model)可在线性模型的基础上通过引入层级结构或高维映射而得。
线性回归(linear regression):连续值预测问题。
线性回归试图学得一个线性模型以尽可能准确地预测实值输出标记。
线性回归试图学得:
f
(
x
i
)
=
w
x
i
+
b
,
使
得
f
(
x
i
)
≃
y
i
f(x_i)=wx_i+b,使得 f(x_i)\simeq y_i
f(xi)=wxi+b,使得f(xi)≃yi
函数模型:
考虑两个变量:
h
θ
(
x
)
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
h_\theta(x) =\theta_0+\theta_1x_1+\theta_2x_2
hθ(x)=θ0+θ1x1+θ2x2
h θ ( x ) = ∑ i = 1 n θ i x i = θ T x h_\theta(x) =\sum_{i=1}^{n}\theta_ix_i=\theta^Tx hθ(x)=i=1∑nθixi=θTx
假设函数
f
f
f为输入
x
x
x的线性函数:
f
(
x
)
=
θ
0
x
0
+
θ
1
x
1
+
θ
2
x
2
+
.
.
.
+
θ
n
x
n
f(x)=\theta_0x_0+\theta_1x_1+\theta_2x_2+...+\theta_nx_n
f(x)=θ0x0+θ1x1+θ2x2+...+θnxn
写成向量形式(在特征x中增加一维
x
0
=
1
x_0=1
x0=1,表示截距项):
f
(
x
)
=
θ
T
x
f(x)=\theta^Tx
f(x)=θTx
线性回归损失函数:平方损失(Quadratic loss function)
损失函数是修正最后的目标,在线性回归问题中,平方损失是凸函数,可以很好地用梯度下降法求得全局最小值点。
我们需要找到最好的权重/参数
[
θ
0
,
θ
1
,
θ
2
,
.
.
.
,
θ
n
]
=
θ
[\theta_0,\theta_1,\theta_2,...,\theta_n]=\theta
[θ0,θ1,θ2,...,θn]=θ
我们需要定义损失函数为:
J
(
θ
0
,
θ
1
,
θ
2
,
.
.
.
,
θ
n
)
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
J(\theta_0,\theta_1,\theta_2,...,\theta_n)=\frac {1}{2m}\sum_{i=1}^{m}(h_\theta({x}^{(i)})-y^{(i)})^2
J(θ0,θ1,θ2,...,θn)=2m1i=1∑m(hθ(x(i))−y(i))2
我们现在需要做的就是让损失函数最小,即最小化损失函数。
梯度下降GD(Gradient Descent)
梯度下降是优化算法的一种,是逐步最小化损失函数的过程。
θ
1
:
=
θ
1
−
α
d
d
θ
1
J
(
θ
1
)
\theta_1:=\theta_1-\alpha\frac{d}{d\theta_1}J(\theta_1)
θ1:=θ1−αdθ1dJ(θ1)
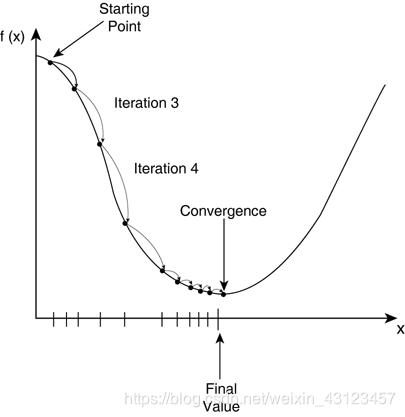
对于多元化情况的梯度下降:
h
θ
(
x
)
=
θ
0
+
θ
1
x
h_\theta(x) = \theta_0+\theta_1x
hθ(x)=θ0+θ1x
损失函数为:
j
(
θ
0
,
θ
1
)
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
j(\theta_0,\theta_1) = \frac {1}{2m}\sum_{i=1}^{m}(h_\theta({x}^{(i)})-y^{(i)})^2
j(θ0,θ1)=2m1i=1∑m(hθ(x(i))−y(i))2
对损失函数求导,沿着负梯度方向进行迭代,得出:
θ
0
,
θ
1
\theta_0,\theta_1
θ0,θ1
θ
0
:
=
θ
0
−
α
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
\theta_0:=\theta_0-\alpha\frac {1}{m}\sum_{i=1}^{m}(h_\theta({x}^{(i)})-y^{(i)})
θ0:=θ0−αm1i=1∑m(hθ(x(i))−y(i))
θ 1 : = θ 1 − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) ⋅ x ( i ) \theta_1:=\theta_1-\alpha\frac {1}{m}\sum_{i=1}^{m}(h_\theta({x}^{(i)})-y^{(i)})·x^{(i)} θ1:=θ1−αm1i=1∑m(hθ(x(i))−y(i))⋅x(i)
假如有n个特征/变量
x
j
x_j
xj(j=1···n):
θ
j
:
=
θ
j
−
α
d
d
θ
j
J
(
θ
0
,
θ
1
)
\theta_j:=\theta_j-\alpha\frac{d}{d\theta_j}J(\theta_0,\theta_1)
θj:=θj−αdθjdJ(θ0,θ1)
梯度下降中的学习率
其中
α
\alpha
α为学习率:在梯度下降中为“步长”。在上图中,我们我们找准方向,迈出一步,直至山底。
α
\alpha
α学习率太大,可能导致算法震荡甚至不收敛。
α
\alpha
α学习率太小,可能导致算法收敛过慢,迭代很多次。
工业界中,我们只需要找一个差不多的
α
\alpha
α即可。
α
\alpha
α不需要设定逐步变小或者衰减,因为点沿着负梯度方向迈一小步的同事,斜率会的绝对值越来越小,趋于0。所以
α
\alpha
α不变的情况下, 步子会越来越小。
逻辑回归(logistic regression)也称对数几率回归(西瓜书):分类问题。
逻辑回归在工业界中也常用作排序,因为其输出为每一类的概率大小。
线性回归在分类问题上健壮性很差,容易受噪声影响。
为什么逻辑回归叫回归,却可以做对离散值预测等分类问题。因为逻辑回归回归的是概率。
这也归功于sigmoid函数(也叫S型函数、压缩函数)
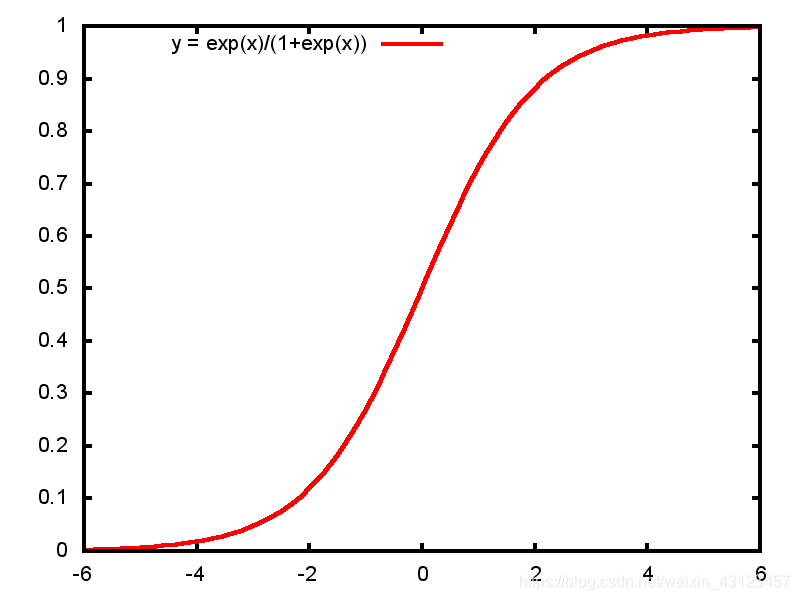
让我们一起认识一下sigmoid函数:
g
(
x
)
=
1
1
+
e
−
x
g(x)=\frac{1}{1+e^{-x}}
g(x)=1+e−x1
sigmoid函数拥有良好的数学特性:
比如求导时:
g
′
(
x
)
=
g
(
x
)
(
1
−
g
(
x
)
)
g'(x)=g(x)(1-g(x))
g′(x)=g(x)(1−g(x))
函数图像为:
逻辑回归:寻找判定边界/决策边界
决策边界在二维空间中可能是一个曲线,在高维空间中也可能是一个曲面。
逻辑回归表达式:
h
θ
(
x
)
=
g
(
−
θ
T
x
)
=
1
1
+
e
−
θ
T
x
h_\theta(x)=g(-\theta^Tx)=\frac{1}{1+e^{-\theta^Tx}}
hθ(x)=g(−θTx)=1+e−θTx1
当
x
0
=
1
x_0=1
x0=1时,表达式就转化为:
θ
T
x
=
θ
0
+
∑
j
=
1
n
θ
j
x
j
\theta^Tx=\theta_0+\sum_{j=1}^{n}\theta_jx_j
θTx=θ0+j=1∑nθjxj
逻辑回归损失函数:对数损失(log loss)
如果我们用线性回归的损失函数(平方损失),我们会拿到一个非凸的函数,非凸函数除去全局最低点,还有很多局部最低点,我们用梯度下降拿到的可能是局部最低点。这不是我们想要的结果。所以我们希望损失函数是凸函数。
对数损失函数:和标准的差异度有多高,是凸函数。每个样本都计算出一个损失,m个样本求出m个损失,求和再做平均
J
(
θ
)
=
1
m
∑
i
=
1
m
C
o
s
t
(
h
θ
(
x
(
i
)
)
,
y
(
i
)
)
J(\theta)=\frac{1}{m}\sum_{i=1}^{m}Cost(h_\theta (x^{(i)}),y^{(i)})
J(θ)=m1i=1∑mCost(hθ(x(i)),y(i))
J ( θ ) = − 1 m [ ∑ i = 1 m y ( i ) l o g ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − h θ ( x ( i ) ) ) ] J(\theta)=-\frac{1}{m}[\sum_{i=1}^{m}y^{(i)}log(h_\theta(x^{(i)}))+(1-y^{(i)})log(1-h_\theta(x^{(i)}))] J(θ)=−m1[i=1∑my(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]
加入正则化项:
λ
2
m
∑
j
=
1
n
θ
j
2
\frac{\lambda}{2m}\sum_{j=1}^{n}\theta_j^2
2mλ∑j=1nθj2
J
(
θ
)
=
[
−
1
m
[
∑
i
=
1
m
y
(
i
)
l
o
g
(
h
θ
(
x
(
i
)
)
)
+
(
1
−
y
(
i
)
)
l
o
g
1
−
h
θ
(
x
(
i
)
)
]
]
+
λ
2
m
∑
j
=
1
n
θ
j
2
J(\theta)=[-\frac{1}{m}[\sum_{i=1}^{m}y^{(i)}log(h_\theta(x^{(i)}))+(1-y^{(i)})log1-h_\theta(x^{(i)})]]+\frac{\lambda}{2m}\sum_{j=1}^{n}\theta_j^2
J(θ)=[−m1[i=1∑my(i)log(hθ(x(i)))+(1−y(i))log1−hθ(x(i))]]+2mλj=1∑nθj2
梯度下降求梯度: α \alpha α同为 learning rata “步长”
θ j : = θ j − α δ δ θ j J ( θ ) \theta_j:=\theta_j-\alpha\frac{\delta}{\delta \theta_j}J(\theta) θj:=θj−αδθjδJ(θ)
总结
1.模型本身并无好坏之分。
2.LR可以概率的形式输出结果,而非只是0,1判断。
3.LR可解释性强,可控度高。
4.训练快,特征处理之后更快。
5.输出的结果可以排序。














 3308
3308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









