







目录
中心:
提出目的: SAGAN 既在每一层都考虑了全局信息,也没有引入过多的参数量,在提高感受野和减小参数量之间找到了一个很好的平衡。
因此,如果我们的生成任务是全局相关性比较高的图片,就可以考虑使用SAGAN。
方法:通过用带有自注意力的特征图去代替传统的卷积特征图,得到自适应注意力的特征图
两种优化:
①、Spectral Normalization : 稳定了训练和生成过程,
②、TTUR:平衡了 D 与 G 的训练速度,在相同的单位时间内产生更好的结果
1.SAGAN解决的问题
用深度卷积网络能够提升 GANs 生成高分辨率图片的细节,但是由于卷积网络的局部感受野的限制,如果要生成大范围相关(Long-range dependency)的区域,卷积网络就会出现问题。譬如说在生成人脸图片时,是非常注重细节的,以左右眼举例,只要左右眼有一点点不对称,就会显得生成的人脸特别不真实。但是因为一般的卷积核很难覆盖很大的区域,在对左眼区域做卷积时它看不到右眼对左眼的影响,这样产生的图片就会缺乏人脸结构特征的完整性。因此,现在我们需要解决的问题是,如何找到一种能够利用全局信息的方法?
传统的一些做法(参数量太大计算量太大):
1、比如用更深的卷积网络,
2、或者直接采用全连接层获取全局信息;
直到 SAGAN 的提出,把 Attention 机制引入了 GANs 的图像生成当中,才找到一种比较简约且高效的方法解决了这一问题。
2.SAGAN的模型架构

上述结构就是用带有自注意力的特征图去代替传统的卷积特征图。方法如下:
首先,f(x),g(x)和 h(x)都是普通的 1x1 卷积,差别只在于输出通道大小不同(这是1x1 卷积的特性,可以通过控制1x1 卷积的通道数来实现特征通道的升维和降维,详细看“https://blog.csdn.net/weixin_43135178/article/details/116143769”);将 f(x)的输出转置,并和 g(x)的输出相乘,再经过 softmax 归一化得到一个 attention map;
将得到的 attention map 和 h(x)逐像素点相乘,得到自适应注意力的特征图。
具体的计算方法如下:

![]()
其中γ被初始化为 0,然后逐渐学会为非本地特征分配更多权重。 为什么要这样做呢? 理由很简单:我们希望先学习简单的任务,然后逐步增加任务的复杂性。 在 SAGAN 中,所提出的自注意力模块已经应用于生成器和判别器,它们通过最小化对抗性损失的铰链形式以交替方式进行训练,SAGAN 采用的 loss 表达式如下:
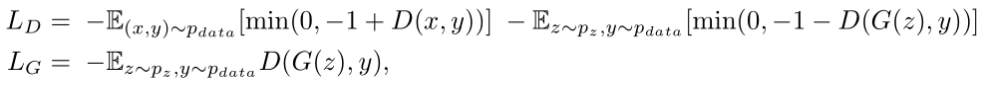
3.SAGAN的优化
SAGAN 当中提出了两种优化,分别是 Spectral Normalization 与 TTUR,前者稳定了训练和生成过程,后者平衡了 D 与 G 的训练速度,简要地介绍如下:
Spectral Normalization(光谱归一化)
SAGAN 为 D 和 G 加入了谱范数归一化的方式,让 D 满足了 1-lipschitz 限制,同时也避免了 G 的参数过多导致梯度异常,使得整套训练较为平稳和高效。关于 Spectral Normalization 的具体过程请参阅 Part1 中的 SNGAN。
TTUR(生成器和判别器使用单独的学习率)
在以前的工作中,判别器的正则化通常会减慢 GAN 学习过程。 实际上,使用正则化判别器的方法通常在训练期间每个生成器需要多个更新步骤(例如,5 个)。 独立地,Heusel等人主张对生成器和判别器使用单独的学习率(TTUR)。 我们建议专门使用 TTUR 来补偿正则化判别器中慢学习的问题,使得对于每个判别器步骤使用更少的生成器步骤成为可能。 使用这种方法,我们能够在相同的单位时间内产生更好的结果。
综上,便是 SAGAN 提出来的用自注意力机制去解决全局信息获取的问题,它既在每一层都考虑了全局信息,也没有引入过多的参数量,在提高感受野和减小参数量之间找到了一个很好的平衡。因此,如果我们的生成任务是全局相关性比较高的图片,就可以考虑使用SAGAN。
G-lab网址:G-Lab人脸生成实验



















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











