







 本文介绍SAGAN,一种利用自我注意力机制的生成对抗网络,解决了传统GAN在处理多类数据尤其是几何结构依赖时的挑战。SAGAN结合了自注意力模块与DCGAN,通过全局依赖建模提高生成图像质量。文章探讨了谱归一化在GAN中的应用,以及TTUR策略对训练稳定性的影响。
本文介绍SAGAN,一种利用自我注意力机制的生成对抗网络,解决了传统GAN在处理多类数据尤其是几何结构依赖时的挑战。SAGAN结合了自注意力模块与DCGAN,通过全局依赖建模提高生成图像质量。文章探讨了谱归一化在GAN中的应用,以及TTUR策略对训练稳定性的影响。
SAGAN
摘要
提出了一种基于自我注意力生成的对抗性网络(the Self-Attention Generative Adversarial Network), 可以注意力驱动、远距离依赖(long-range dependency)来完成生成图片的任务。传统的卷积GAN网络,是通过低分辨率图像中的空间局部点来生成高分辨率细节特征。
SAGAN:
- 可以使用来自所有特征位置的线索来生成详细信息;
- 此外,鉴别器还可以检查图像中遥远部分的高度细节特征是否相互一致;
- 对GAN生成器应用光谱归一化来提升性能。
introduction
problems
一些papers问题
问题1:在多类数据集上训练时,对某些图像类的建模难度要困难得多(DCGAN、CGAN),擅长合成具有很少结构约束的图像类(比如说海洋、天空和景观类,它们更多的是纹理而不是几何),它无法捕获在某些类中一致发生的几何模式或结构模式(比如说狗有四条腿,不能多也不能少)。
可能的原因:以前的模型严重依赖于卷积来建模不同图像区域之间的依赖关系。由于卷积运算符具有局部感受域,因此只能在经过多个卷积层之后处理长距离依赖性(long-range dependency)。因各种原因阻止了解长期依赖关系:
- 一个小模型可能无法表示它们,
- 优化算法可能很难发现仔细协调多层来捕获这些依赖关系的参数值,
- 而且这些参数化在应用于以前看不见的输入时,可能在统计上很脆弱,很容易失败。
还用到了 Spectral Normalization for GANs (SNGAN)提出的谱归一化,该文代码中的谱归一化和原始的谱归一化运用方式略有差别:
-
原始的谱归一化基于 W-GAN 的理论,只用在 Discriminator 中,用以约束 Discriminator 函数为 1-Lipschitz 连续。而在 Self-Attention GAN 中,Spectral Normalization 同时出现在了 Discriminator 和 Generator 中,用于使梯度更稳定。除了生成器和判别器的最后一层外,每个卷积/反卷积单元都会上一个 SpectralNorm。
-
当把谱归一化用在 Generator 上时,同时还保留了 BatchNorm。Discriminator 上则没有 BatchNorm,只有 SpectralNorm。
-
谱归一化用在 Discriminator 上时最后一层不加 Spectral Norm
self-attention:计算一个位置的响应作为所有位置特征的加权和,其中权重或注意力向量只计算一个小的计算成本。解决处理不了全局性的问题。
SAGAN的优点
SAGAN = self-attention + DCGAN
好处:
- 自我注意模块是对卷积的补充,并有助于建模跨图像区域的远程、多层次的依赖关系。
- 通过自我关注,生成器可以绘制图像,其中每个位置的细节与图像的遥远部分的细节精心协调。
- 判别器还可以更准确地对全局图像结构实施复杂的几何约束
SAGAN理论
Self-attention架构
用带有自注意力的特征图去代替传统的卷积特征图:
- 首先,f(x),g(x)和 h(x)都是普通的 1x1 卷积,差别只在于输出通道大小不同;
- 将 f(x)的输出转置,并和 g(x)的输出相乘,再经过 softmax 归一化得到一个 attention map;
- 将得到的 attention map 和 h(x)逐像素点相乘,得到自适应注意力的特征图。
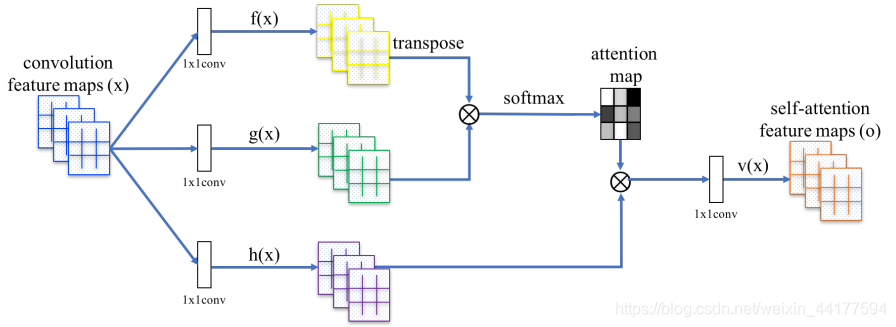
在卷积神经网络中,每个卷积核的尺寸都是很有限的(基本上不会大于 5),因此每次卷积操作只能覆盖像素点周围很小一块邻域。
对于距离较远的特征,例如狗有四条腿这类特征,就不容易捕获到了(也不是完全捕获不到,因为多层的卷积、池化操作会把 feature map 的高和宽变得越来越小,越靠后的层,其卷积核覆盖的区域映射回原图对应的面积越大。但总而言之,毕竟还得需要经过多层映射,不够直接)。
Self-Attention 通过直接计算图像中任意两个像素点之间的关系,一步到位地获取图像的全局几何特征。
代码
class Self_Attn(nn.Module):
""" Self attention Layer"""
def __init__(self,in_dim,activation):
super(Self_Attn,self).__init__()
self.chanel_in = in_dim
self.activation = activation
self.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim , kernel_size= 1)
self.gamma = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1) #
def forward(self,x):
"""
inputs :
x : input feature maps( B X C X W X H)
returns :
out : self attention value + input feature
attention: B X N X N (N is Width*Height)
"""
m_batchsize,C,width ,height = x.size()
proj_query = self.query_conv(x).view(m_batchsize,-1,width*height).permute(0,2,1) # B X CX(N)
proj_key = self.key_conv(x).view(m_batchsize,-1,width*height) # B X C x (*W*H)
energy = torch.bmm(proj_query,proj_key) # transpose check
attention = self.softmax(energy) # BX (N) X (N)
proj_value = self.value_conv(x).view(m_batchsize,-1,width*height) # B X C X N
out = torch.bmm(proj_value,attention.permute(0,2,1) )
out = out.view(m_batchsize,C,width,height)
out = self.gamma*out + x
return out,attention
三个卷积核
构造函数中定义了三个 1 × 1 的卷积核,分别被命名为 query_conv , key_conv 和 value_conv 。
-
query——查询,希望输入一个像素点,查询(计算)到feature map上所有像素点对这一个点的影响。
-
key——字典中的键,相当于所查询的数据库。
-
value_conv ——可以看成对原 feature map 多加了一层卷积映射,这样可以学习到的参数就更多了,否则 query_conv 和 key_conv 的参数太少,按代码中只有 in_dims × in_dims//8 个。
-
query,key都是输入的feature map。可以看成把 feature map 复制了两份,一份作为 query 一份作为 key。
需要用一个什么样的函数,才能针对 query 的 feature map 中的某一个位置,计算出 key 的 feature map 中所有位置对它的影响呢?作者认为这个函数应该是可以通过“学习”得到的。那么,自然而然就想到要对这两个 feature map 分别做卷积核为 1 × 1 的卷积了,因为卷积核的权重是可以学习得到的。
三个映射
- proj_query (B × C × N) C—in_dim//8
- proj_key (B × N × C) C—in_dim//8
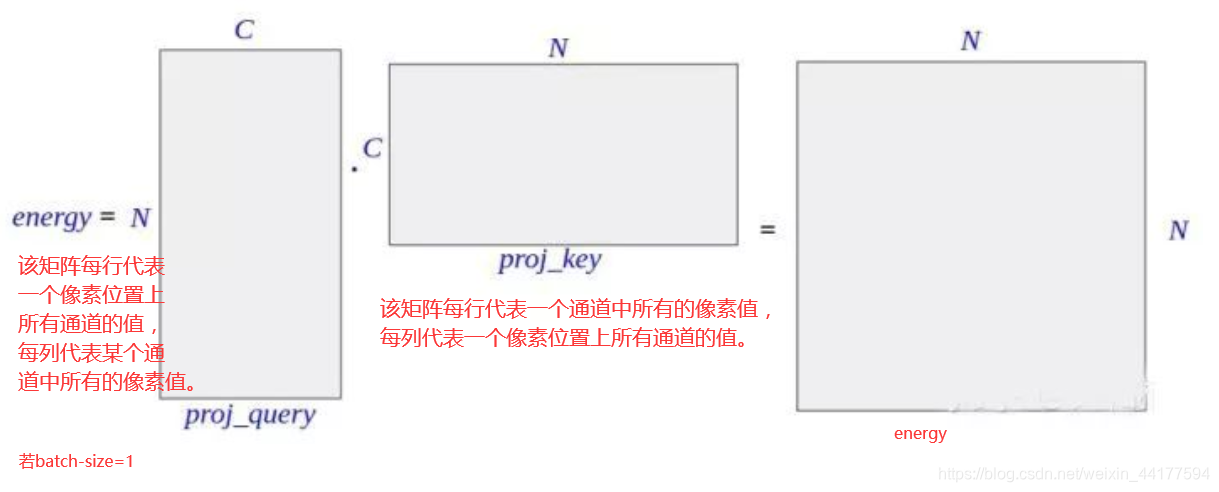
- energy 中第 i 行 j 列的元素值,表示第 j 个像素点对第 i 个像素点的影响。
# 按“行”归一化,这个操作之后的矩阵,各行元素之和为 1
attention = self.softmax(energy)
# attention的维度也是N*N
- proj_value (B x C x N) C — in_dim
对原 feature map 作一次卷积映射,然后把得到的新 feature map 改变形状,维度变为 C × N ,其中 C 为通道数
out
out = torch.bmm(proj_value,attention.permute(0,2,1) )
out = out.view(m_batchsize,C,width,height)
- 把 proj_value (C × N)矩阵同 attention 矩阵的转置(N × N)相乘,得到 out (C × N)。
之所以转置,是因为 attention 中每行的和为 1,其意义是权重,需要转置后变为每列的和为 1,施加于 proj_value 的行上,作为该行的加权平均。

- out 中第 i 行包含了输出的第 i 个通道中的所有像素,
- 第 j 列表示所有像素中的第 j 个像素,
- out 中的第 i 行第 j 列的元素,表示被 attention 加权之后的 feature map 的第 i 个通道的第 j 个像素的像素值。
方法:


SAGAN 优化
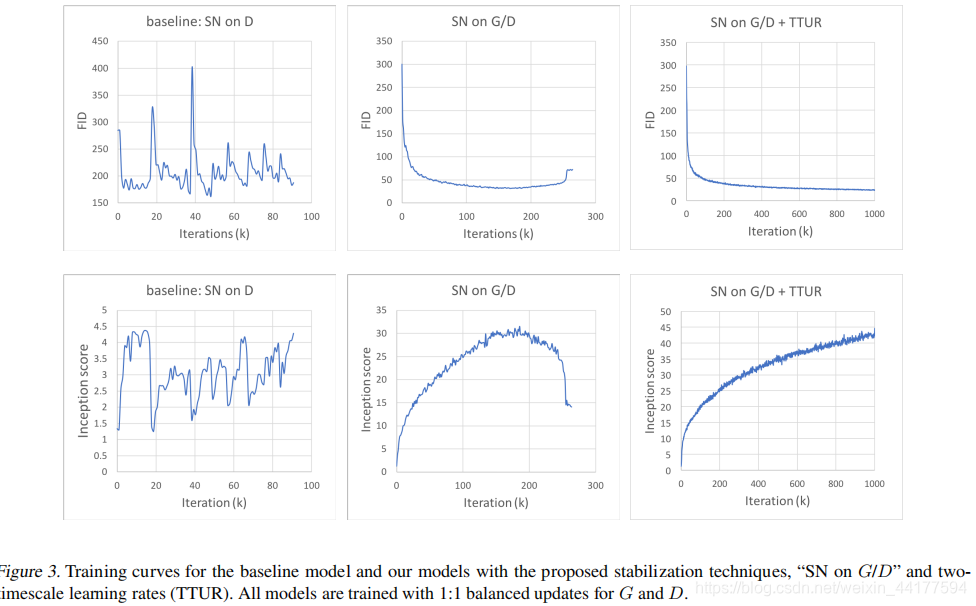
为了稳定训练:
1. Spectral Normalization
SAGAN 为 D 和 G 加入了谱范数归一化的方式,让 D 满足了 1-lipschitz 限制,同时也避免了 G 的参数过多导致梯度异常,使得整套训练较为平稳和高效。
2. TTUR
在以前的工作中,判别器的正则化通常会减慢 GAN 学习过程。 实际上,使用正则化判别器的方法通常在训练期间每个生成器需要多个更新步骤。对生成器和判别器使用单独的学习率(TTUR)。
more details
- 所有SAGAN都被设计为生成128×128图像。
- spectral normalization运用在G和D上
- uses conditional batch normalization in the generator and projection in the discriminator.
- Adam optimizer with β1 = 0 and β2 = 0.9 for training
- the learning rate for the discriminator is 0.0004 and the learning rate for the generator is 0.0001.
结果展示
评估两个技巧
self-attention机制


















 2055
2055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









