







代码地址:https://github.com/heykeetae/Self-Attention-GAN
目录
1.背景+整体介绍
SAGAN:将self-attention机制引入到GANs的图像生成当中,来建模像素间的远距离关系,用于图像生成任务
CGAN的缺点:
1、依赖卷积建模图像不同区域的依赖关系,由于卷积核比较小一般都是1*1,3*3,5*5...==>卷积感受野太小,需要进行多层卷积才能获取远距离的依赖关系
2、多层卷积,优化算法优化参数困难
所以我们想要获取全局的依赖关系,又想小的计算量,所以引入attention机制,在一层获取远距离的依赖关系而非多层卷积操作获得依赖关系
对于CGAN来说:
擅长合成有很少结构约束的目标,例如天空、海洋等,不能很好地捕捉某些目标固有的几何或结构模式,例如狗(比如生成了一条腿以后,由于它对于全局的依赖关系没有把控,所以有可能还生成好几条腿,总共生成五条腿,三条腿等)
2.算法详解
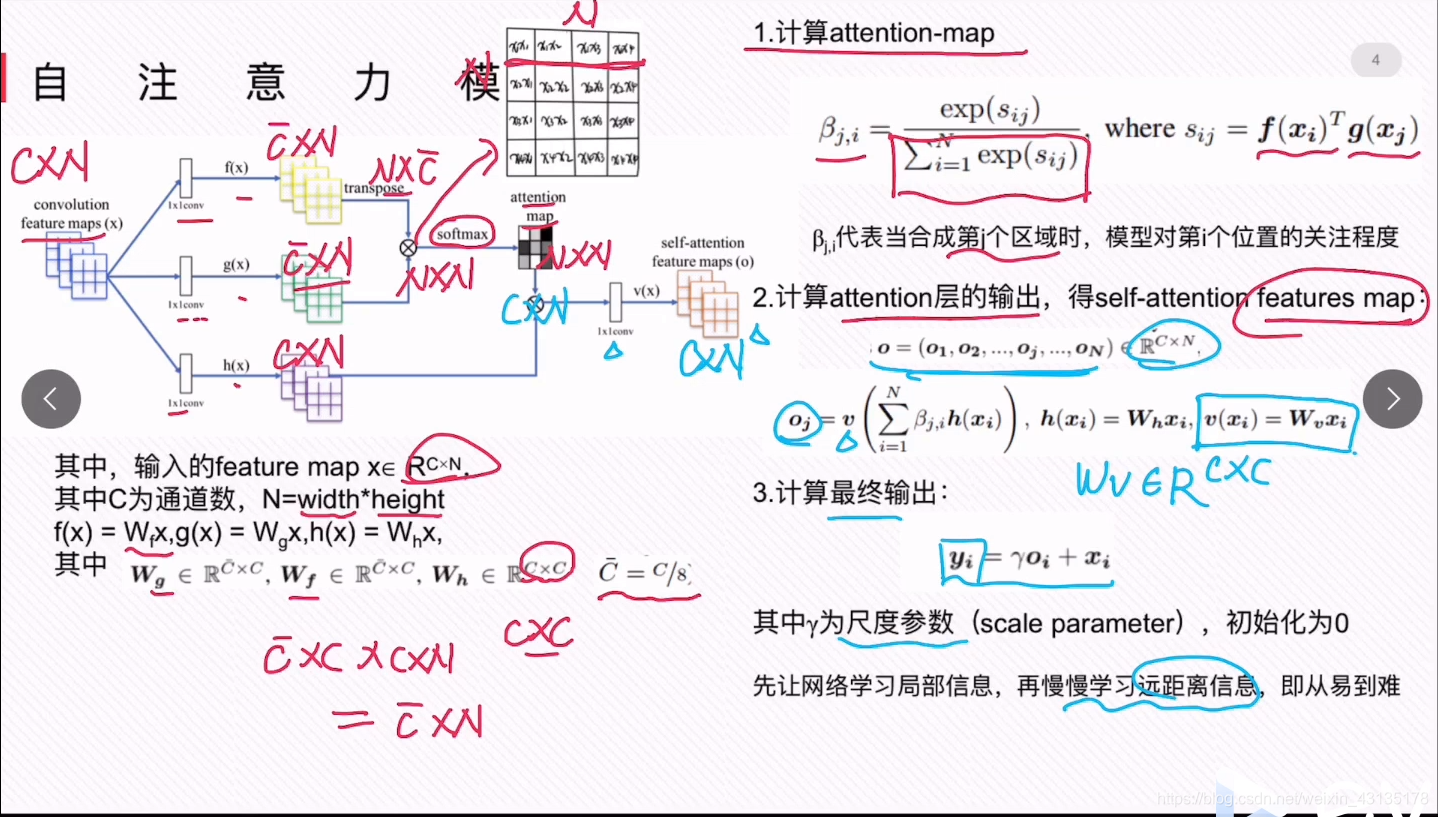
N=width*height,即一共有多少个像素点
f(x)=Wfx,即c^*c*c*n=c^*c,g(x)=Wgx,即c^*c*c*n=c^*c,h(x)=Whx,即c*c*c*n=c*c
![]() 代表的是点乘运算,
代表的是点乘运算,
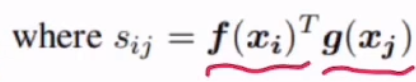 即对应
即对应 这里的点乘后的结果。
这里的点乘后的结果。
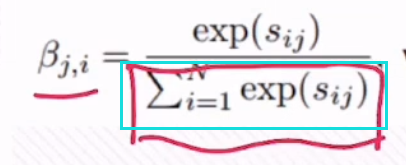 即对应softmax进行归一化操作
即对应softmax进行归一化操作
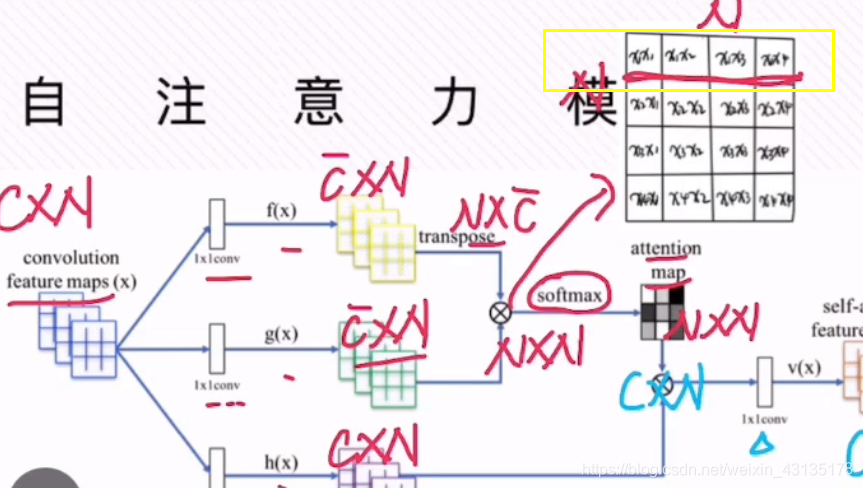 点乘后得到N*N的第一行代表1个pixel和其他像素的依赖关系,总共N行
点乘后得到N*N的第一行代表1个pixel和其他像素的依赖关系,总共N行
3.损失函数
hinge loss:铰链损失

L(y)=max(0,1-y*y^)的含义:
假如y^=1.5,那么此时说明判别器确定分类结果为真实的样本,那么1-1*1.5=-0.5,取max。则L(y)=0,那么损失函数为0,即验证了下面这句话
对于如下的证明一样的道理
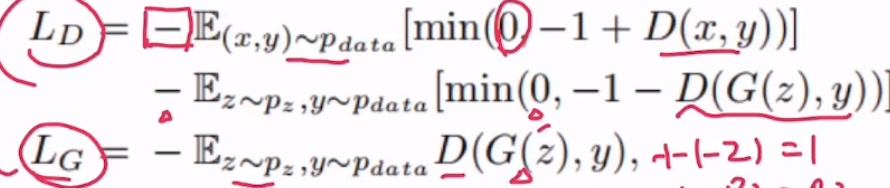
4.稳定模型的训练方法:
谱范数归一化

Lipschitz constant:拉普西斯常数,即寻找一个最小的K,使得对于所有的a,b∈D满足上式
在训练过程中,对D进行K次更新,然后再对G进行一次更新,原因是有了一个好的D,才可以区分real和fake,才能对G进行一个好的调整
5.代码讲解
import torch
import torch.nn as nn
from spectral import SpectralNorm
import numpy as np
class Self_Attn(nn.Module):
""" Self attention Layer"""
def __init__(self,in_dim,activation):
super(Self_Attn,self).__init__()
self.chanel_in = in_dim
self.activation = activation
## 下面的query_conv,key_conv,value_conv即对应Wg,Wf,Wh
self.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)#即得到C^ X C
self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)#即得到C^ X C
self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim , kernel_size= 1)#即得到C X C
self.gamma = nn.Parameter(torch.zeros(1)) #这里即是计算最终输出的时候的伽马值,初始化为0
self.softmax = nn.Softmax(dim=-1)
def forward(self,x):
"""
inputs :
x : input feature maps( B X C X W X H)
returns :
out : self attention value + input feature
attention: B X N X N (N is Width*Height)
"""
m_batchsize,C,width ,height = x.size()
## 下面的proj_query,proj_key都是C^ X C X C X N= C^ X N
proj_query = self.query_conv(x).view(m_batchsize,-1,width*height).permute(0,2,1) # B X CX(N),permute即为转置
proj_key = self.key_conv(x).view(m_batchsize,-1,width*height) # B X C x (*W*H)
energy = torch.bmm(proj_query,proj_key) # transpose check,进行点乘操作
attention = self.softmax(energy) # BX (N) X (N)
proj_value = self.value_conv(x).view(m_batchsize,-1,width*height) # B X C X N
out = torch.bmm(proj_value,attention.permute(0,2,1) )
out = out.view(m_batchsize,C,width,height)
out = self.gamma*out + x
return out,attention
class Generator(nn.Module):
"""Generator."""
def __init__(self, batch_size, image_size=64, z_dim=100, conv_dim=64):
super(Generator, self).__init__()
self.imsize = image_size
layer1 = []
layer2 = []
layer3 = []
last = []
repeat_num = int(np.log2(self.imsize)) - 3
mult = 2 ** repeat_num # 8
layer1.append(SpectralNorm(nn.ConvTranspose2d(z_dim, conv_dim * mult, 4)))
layer1.append(nn.BatchNorm2d(conv_dim * mult))
layer1.append(nn.ReLU())
curr_dim = conv_dim * mult
layer2.append(SpectralNorm(nn.ConvTranspose2d(curr_dim, int(curr_dim / 2), 4, 2, 1)))
layer2.append(nn.BatchNorm2d(int(curr_dim / 2)))
layer2.append(nn.ReLU())
curr_dim = int(curr_dim / 2)
layer3.append(SpectralNorm(nn.ConvTranspose2d(curr_dim, int(curr_dim / 2), 4, 2, 1)))
layer3.append(nn.BatchNorm2d(int(curr_dim / 2)))
layer3.append(nn.ReLU())
if self.imsize == 64:
layer4 = []
curr_dim = int(curr_dim / 2)
layer4.append(SpectralNorm(nn.ConvTranspose2d(curr_dim, int(curr_dim / 2), 4, 2, 1)))
layer4.append(nn.BatchNorm2d(int(curr_dim / 2)))
layer4.append(nn.ReLU())
self.l4 = nn.Sequential(*layer4)
curr_dim = int(curr_dim / 2)
self.l1 = nn.Sequential(*layer1)
self.l2 = nn.Sequential(*layer2)
self.l3 = nn.Sequential(*layer3)
last.append(nn.ConvTranspose2d(curr_dim, 3, 4, 2, 1))
last.append(nn.Tanh())
self.last = nn.Sequential(*last)
self.attn1 = Self_Attn( 128, 'relu')
self.attn2 = Self_Attn( 64, 'relu')
def forward(self, z):
z = z.view(z.size(0), z.size(1), 1, 1)
out=self.l1(z)
out=self.l2(out)
out=self.l3(out)
out,p1 = self.attn1(out)
out=self.l4(out)
out,p2 = self.attn2(out)
out=self.last(out)
return out, p1, p2
class Discriminator(nn.Module):
"""Discriminator, Auxiliary Classifier."""
def __init__(self, batch_size=64, image_size=64, conv_dim=64):
super(Discriminator, self).__init__()
self.imsize = image_size
layer1 = []
layer2 = []
layer3 = []
last = []
layer1.append(SpectralNorm(nn.Conv2d(3, conv_dim, 4, 2, 1)))
layer1.append(nn.LeakyReLU(0.1))
curr_dim = conv_dim
layer2.append(SpectralNorm(nn.Conv2d(curr_dim, curr_dim * 2, 4, 2, 1)))
layer2.append(nn.LeakyReLU(0.1))
curr_dim = curr_dim * 2
layer3.append(SpectralNorm(nn.Conv2d(curr_dim, curr_dim * 2, 4, 2, 1)))
layer3.append(nn.LeakyReLU(0.1))
curr_dim = curr_dim * 2
if self.imsize == 64:
layer4 = []
layer4.append(SpectralNorm(nn.Conv2d(curr_dim, curr_dim * 2, 4, 2, 1)))
layer4.append(nn.LeakyReLU(0.1))
self.l4 = nn.Sequential(*layer4)
curr_dim = curr_dim*2
self.l1 = nn.Sequential(*layer1)
self.l2 = nn.Sequential(*layer2)
self.l3 = nn.Sequential(*layer3)
last.append(nn.Conv2d(curr_dim, 1, 4))
self.last = nn.Sequential(*last)
self.attn1 = Self_Attn(256, 'relu')
self.attn2 = Self_Attn(512, 'relu')
def forward(self, x):
out = self.l1(x)
out = self.l2(out)
out = self.l3(out)
out,p1 = self.attn1(out)
out=self.l4(out)
out,p2 = self.attn2(out)
out=self.last(out)
return out.squeeze(), p1, p2



















 3572
3572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











