







论文:mixup: Beyond Empirical Risk Minimization
混合样本数据增强(Mixed Sample Data Augmentation,MSDA)是一种数据增强技术,旨在让模型更好地泛化到未见过的样本,提高模型的鲁棒性。MSDA通过将不同的样本混合在一起进行训练【将同一数据集中的不同样本进行混合,得到新的训练批次,如果想要混合来自不同数据集的样本进行训练,则需要进行跨数据集混合(Cross-dataset Mixed Sample Data Augmentation,CDMSDA),这是一种更为复杂的数据增强技术,需要解决数据标签不同、数据分布不同等问题。】,生成新的、更丰富的训练数据。
具体来说,MSDA可以分为以下几个步骤:
-
随机选择两个或多个不同的数据样本。
-
对于每个样本,随机应用一个或多个数据增强操作(如随机裁剪、随机旋转、颜色扰动等),得到增强后的样本。
-
将增强后的样本按照不同的比例混合在一起,形成一个新的训练批次。混合的比例可以根据不同的任务和数据集进行调整。
-
使用混合数据进行训练,并更新模型参数。
MSDA的核心思想是通过将不同的数据样本混合在一起训练,使得模型对于不同的输入有更好的适应能力。实际上,MSDA也可以看作是一种类似于Mixup的正则化方法,可以有效减少模型的过拟合问题。此外,MSDA还可以提高数据集的多样性,进一步提升模型的泛化能力和鲁棒性。
需要注意的是,MSDA也存在一些潜在的问题,如混合数据时可能会存在不合理的样本组合,从而导致训练偏差或性能下降。因此,在实践中,需要根据具体情况选择合适的MSDA策略,并进行有效监测和调整。
Formulation
In mixup, the virtual training feature-target samples are produced as,
x˜ = λxi + (1 − λ)xj
y˜ = λyi + (1 − λ)yj
where (xi, yi) and (xj, yj) are two feature-target samples drawn at random from the training data, λ∈[0, 1].
The mixup hyper-parameter α controls the strength of interpolation between feature-target pairs and λ∼Beta(α, α).
其中(xi,yi)和(xj,yj)是从训练数据中随机抽取的两个特征目标样本,λ∈[0,1]。
混合超参数α控制特征-目标对和λ∞β(α,α)之间的插值强度。
github地址以及论文地址:GitHub - JasonZhang156/awesome-mixed-sample-data-augmentation: A collection of awesome things about mixed sample data augmentation
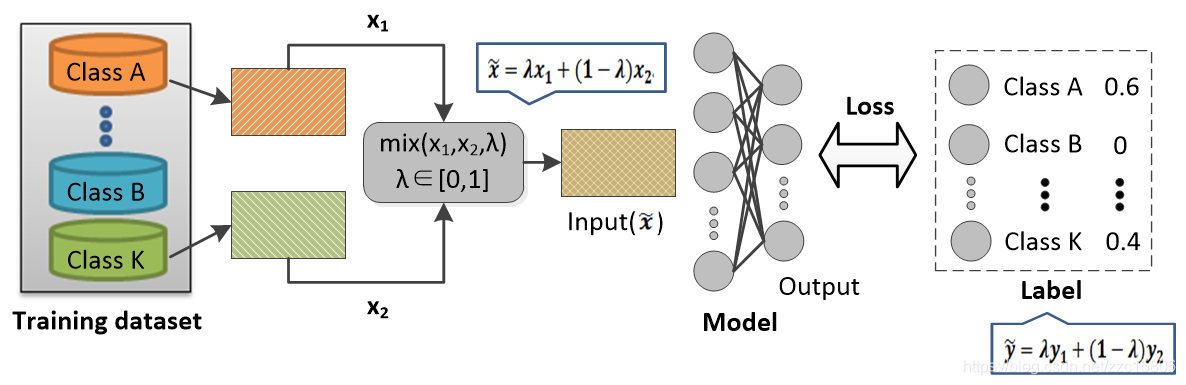
Mixup算法的核心思想是按一定的比例随机混合两个训练样本及其标签。这种混合方式不仅能够增加样本的多样性,并且能够使不同类别的决策边界过渡更加平滑,减少了一些难例样本的误识别,模型的鲁棒性得到提升,训练时也比较稳定。下图展示了基于Mixup算法的training pipeline,
受Mixup算法思想的启发,大量MSDA算法涌现出来,包括结合Mixup和mask,对Mixup方法进行Adaptive学习等。目前,MSDA相关算法主要应用在分类任务中,其中图像分类相关论文居多。但是,不同领域的研究者也在尝试mixup方法和本领域任务的结合,比如NLP、Semi-supervised Learning、GAN等领域。
代码:
### mix two images
class MixUp_AUG:
def __init__(self):
self.dist = torch.distributions.beta.Beta(torch.tensor([1.2]), torch.tensor([1.2]))
def aug(self, rgb_gt, rgb_noisy):
bs = rgb_gt.size(0)
indices = torch.randperm(bs) # 返回bs个(0,bs-1)的随机整数组成序列
rgb_gt2 = rgb_gt[indices]
rgb_noisy2 = rgb_noisy[indices]
lam = self.dist.rsample((bs,1)).view(-1,1,1,1).cuda() # ([bs, 1, 1, 1])
rgb_gt = lam * rgb_gt + (1-lam) * rgb_gt2
rgb_noisy = lam * rgb_noisy + (1-lam) * rgb_noisy2
return rgb_gt, rgb_noisy
参考:混合样本数据增强(Mixed Sample Data Augmentation)_z小白的博客-CSDN博客_混合样本数据增强



















 1221
1221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











