









 文章探讨了LatentDiffusionModels中的不同VAE变种,如kl-f8-VAE在ImageNet预训练,以及f8-ft-EMA和f8-ft-MSE针对stablediffusion人脸训练的改进方法。f8-ft-EMA采用EMA权重,输出锐利;f8-ft-MSE侧重MSE重建,输出更平滑。
文章探讨了LatentDiffusionModels中的不同VAE变种,如kl-f8-VAE在ImageNet预训练,以及f8-ft-EMA和f8-ft-MSE针对stablediffusion人脸训练的改进方法。f8-ft-EMA采用EMA权重,输出锐利;f8-ft-MSE侧重MSE重建,输出更平滑。
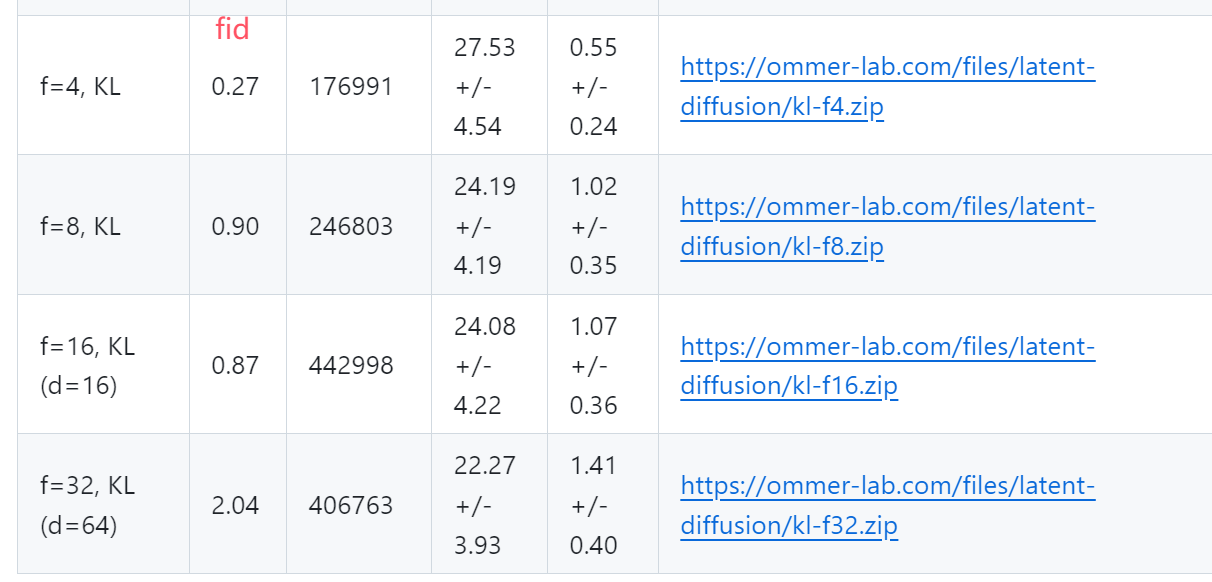
kl-f4-VAE / kl-f8-VAE / kl-f16-VAE / kl-f32-VAE 的区别
GitHub - CompVis/latent-diffusion: High-Resolution Image Synthesis with Latent Diffusion Models
f 是下采样因子的意思,
- f=4: 意味着输入图像在潜在空间中被下采样4倍。例如,256x256的输入图像会被编码为64x64的latent。
- f=8: 输入图像在潜在空间中被下采样8倍。同样的256x256输入图像会被编码为32x32的latent。
- ......
可以看到f越低,那么生成的图像的FID就会越低,就意味着在diffusion中使用的加噪去噪的分辨率较高,这样其实很自然的就可以知道最后生成的图像的FID会低一些,如果你使用256的图像而不进行encoder和decoder,那么会更低,只是计算量会大很多。究其原因是因为在高分辨率降低到低分辨率以及低分辨率到高分辨率的时候会出现信息损失,降低的分辨率越少,那么损失越小
kl-f8-VAE(最常用的VAE)
Latent Diffusion Models 包含很多Kl8/4...的VAE,这些VAE可以使用自己的数据集进行预训练:
所用损失函数: 重构损失 (Reconstruction Loss) + 感知损失 (Perceptual Loss) + 负对数似然损失 (Negative Log-Likelihood Loss, NLL Loss) + KL散度损失 (KL Divergence Loss)
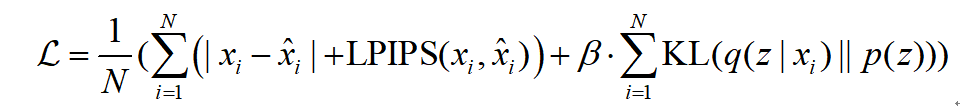
网址:GitHub - CompVis/latent-diffusion: High-Resolution Image Synthesis with Latent Diffusion Models
他的loss很复杂:
def forward(self, inputs, reconstructions, posteriors, optimizer_idx,
global_step, last_layer=None, cond=None, split="train",
weights=None):
rec_loss = torch.abs(inputs.contiguous() - reconstructions.contiguous())
if self.perceptual_weight > 0:
p_loss = self.perceptual_loss(inputs.contiguous(), reconstructions.contiguous())
rec_loss = rec_loss + self.perceptual_weight * p_loss
nll_loss = rec_loss / torch.exp(self.logvar) + self.logvar
weighted_nll_loss = nll_loss
if weights is not None:
weighted_nll_loss = weights*nll_loss
weighted_nll_loss = torch.sum(weighted_nll_loss) / weighted_nll_loss.shape[0]
nll_loss = torch.sum(nll_loss) / nll_loss.shape[0]
kl_loss = posteriors.kl()
kl_loss = torch.sum(kl_loss) / kl_loss.shape[0]
# now the GAN part
if optimizer_idx == 0:
# generator update
if cond is None:
assert not self.disc_conditional
logits_fake = self.discriminator(reconstructions.contiguous())
else:
assert self.disc_conditional
logits_fake = self.discriminator(torch.cat((reconstructions.contiguous(), cond), dim=1))
g_loss = -torch.mean(logits_fake)
if self.disc_factor > 0.0:
try:
d_weight = self.calculate_adaptive_weight(nll_loss, g_loss, last_layer=last_layer)
except RuntimeError:
assert not self.training
d_weight = torch.tensor(0.0)
else:
d_weight = torch.tensor(0.0)
disc_factor = adopt_weight(self.disc_factor, global_step, threshold=self.discriminator_iter_start)
loss = weighted_nll_loss + self.kl_weight * kl_loss + d_weight * disc_factor * g_loss
log = {"{}/total_loss".format(split): loss.clone().detach().mean(), "{}/logvar".format(split): self.logvar.detach(),
"{}/kl_loss".format(split): kl_loss.detach().mean(), "{}/nll_loss".format(split): nll_loss.detach().mean(),
"{}/rec_loss".format(split): rec_loss.detach().mean(),
"{}/d_weight".format(split): d_weight.detach(),
"{}/disc_factor".format(split): torch.tensor(disc_factor),
"{}/g_loss".format(split): g_loss.detach().mean(),
}
return loss, logf8-ft-EMA 、f8-ft-MSE
没有发现训练代码...
他俩与“kl-f8-VAE”的区别:
kl-f8-VAE是在“ImageNet”进行训练的,而f8-ft-EMA /f8-ft-MSE它们是为了增强stable diffusion人脸的训练
1). sd-vae-ft-ema
- trained on LAION-aesthetics+human:The first, ft-EMA, was resumed from the original checkpoint, trained for 313k steps and uses EMA weights. It uses the same loss configuration as the original checkpoint (L1 + LPIPS).
stabilityai/sd-vae-ft-ema(https://huggingface.co/stabilityai/sd-vae-ft-ema)
2). sd-vae-ft-mse
- continue training on same dataset but in such a way to make the outputs more smooth:The second, ft-MSE, was resumed from ft-EMA and uses EMA weights and was trained for another 280k steps using a different loss, with more emphasis on MSE reconstruction (MSE + 0.1 * LPIPS). It produces somewhat ``smoother'' outputs. The batch size for both versions was 192 (16 A100s, batch size 12 per GPU).
stabilityai/sd-vae-ft-mse(https://huggingface.co/stabilityai/sd-vae-ft-mse)
在上面的链接中有这两个模型在辅助生成图片时的效果对比。就使用经验而言,EMA 会更锐利、MSE 会更平滑。



















 910
910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











