







【ICLR 2023】DiGress + Discrete Denoising diffusion for graph generation
code:https://github.com/cvignac/DiGress
预备知识:
其中v1表示老师,v2表示学生1,v3表示校长,v4表示学生2
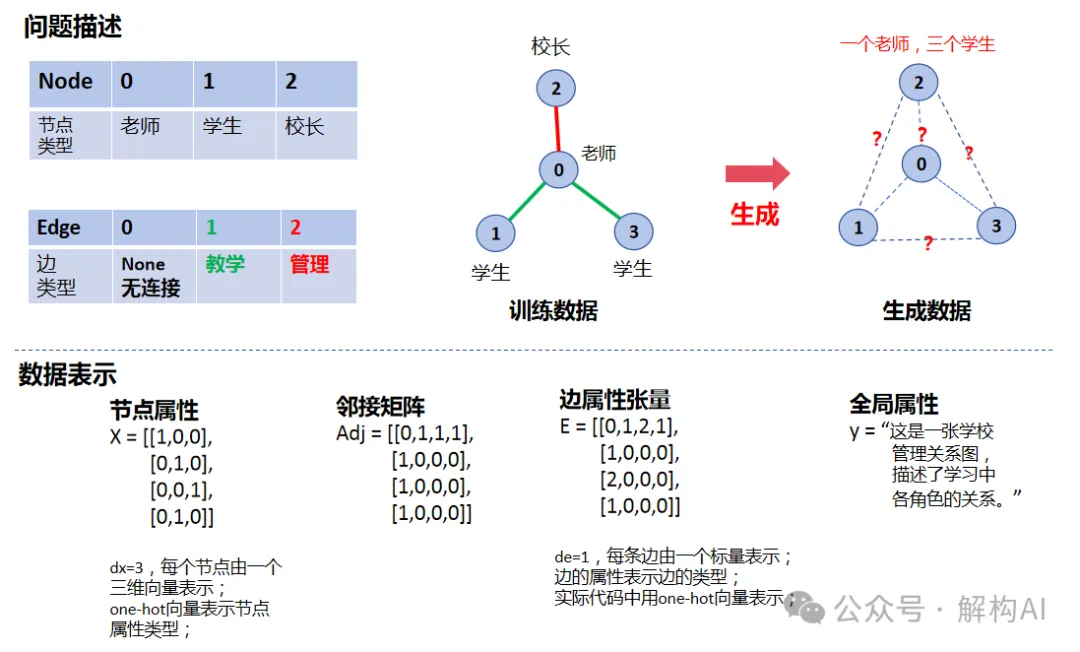
一张Graph,假设其有N个节点,N*N条边。则它具有三类属性:节点属性、边属性、全局属性。
第一、节点属性
这是一个N*dx的张量。dx表示每一个节点的属性维度。在上图中,dx=3,每个节点由一个三维向量表示,这是一个one-hot向量,表示节点所属的类型。dx等于节点类型的总数,dx=|节点类型|。
相同类型的边用一样的one-hot表示,组成节点属性矩阵的某一行,例如第2行和第4行是一样的,它们分别表示两个学生
第二、边属性
这是一个N*N*de的张量。de表示每一条边的属性维度。在上图中,为了简单,设置de=1,它表示每条边的类型。N*N表示任意两个节点之间都有边,对于没有边的节点,则认为其边的类型为0。在实现中,边的属性也是one-hot向量,用以表示边的类型,所以de等于边类型的总数,de=|边类型|。
相同类型的边用一样的one-hot表示,组成表属性矩阵的某一行,例如第2行和第4行是一样的,它们分别表示两个学生
第三、全局属性
这是一个K*dg 维度的张量。K表示全局信息类型,如“Graph的描述”、“Graph的类型”等;dg表示每一类信息的维度。Diffusion模型中,步数t也被映射到全局属性的空间中统一表达。
整体架构
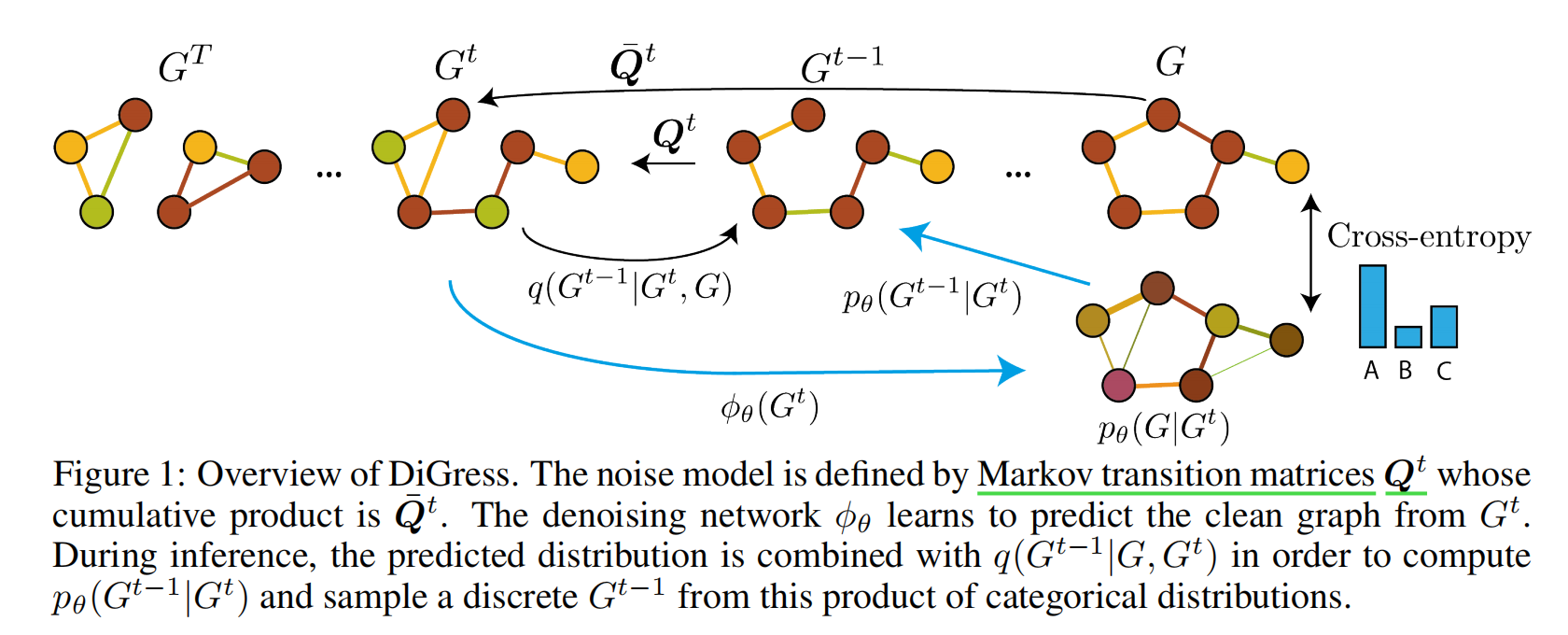
加噪过程(扩散过程):对于一张原始图G,逐步增加噪声,经过T步后,得到与G无关的噪声图GT。
去噪过程:从Gt中去除噪声,得到Gt-1,依次类推。依次类推,直到最后一步,生成最终的结果G。去噪过程中本质就是要得到后向转移分布,得到后向转移分布,便可以一步一步生成最终的目标对象。
高效Graph Diffusion的三要素
对于一个高效的Diffusion模型,需要满足以下三个要素:
1)要素一:可以推断出x[t]
是已知的。即在扩散过程中,可以从初始数据推断出任一step的分布;这一过程通常根据假设直接计算出来。
任意扩散步骤的计算---如何设计噪声?
在连续的场景(如Image与Video)中,噪声通常使用高斯噪声。因为像素点的取值是一个连续变量,连续的高斯噪声可以很好地表达像素值。但在Graph中,节点与边的类型是离散变量,高斯噪声直接加在原始Graph上是不合适的。因为它会破坏Graph的稀疏性和连通性。当然,高斯噪声可以加在隐空间上,这是另一类大的方法,这里先不讨论。
在Graph场景中,离散Diffusion的噪声是一系列转移矩阵:(Q1,Q2, ... , QT)。Q中每一个元素表示从一种状态到另一种状态的转移概率。也就是说,任何一步的隐态Graph,可以根据转移矩阵与初始Graph相乘得到。如下图所示。
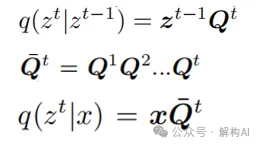
至此,我们满足了高效Diffusion三要素中的第一个:根据我们设计的噪声,可以从原始数据求得任一step的隐层分布。
2)要素二:从噪声中逐步生成目标数据
是已知的。即在去噪过程中,可以从噪声中逐步生成目标数据;这一步通常需要模型参与。
Diffusion有三种理论实现:分别是【预测噪声】、【预测原始数据】、【预测分数函数】。DDPM属于预测噪声,而DIGRESS属于预测原始数据。
3)要素三:当步数T趋向于无穷大时,最后一步的隐层表示与初始数据无关。
如此,我们就可以从已知的先验噪声中采样,用于生成目标数据。这一步通常在设计时就默认成立,通过取较大的T值和设计合理的噪声进行约束。
训练与推理过程
损失:
损失函数就是【预测出来的Graph】与【原始真实Graph】的交叉熵。
根据问题建模的图1可以知道,【原始真实Graph】中边和节点的属性都是one-hot向量,表示的是节点类型和边类型的概率分布。所以,损失函数表示的是Graph中节点与边的【分类过程】。
预测出来的Graph其实就是两个属性矩阵:节点属性矩阵N*N*dx;边属性矩阵N*N*de。这两个矩阵中就是节点与边的各相应类型的概率分布,这与常见的分类问题是一样的。
训练:
训练的过程就是标准的Diffusion训练过程:首先,随机选择一个步数t,直接计算出第t步的噪声Graph:Gt;然后,让网络根据Gt预测出其原始Graph;紧接着,根据损失函数,求得损失大小;最后,进行反向传播,优化网络参数。
推理(生成)

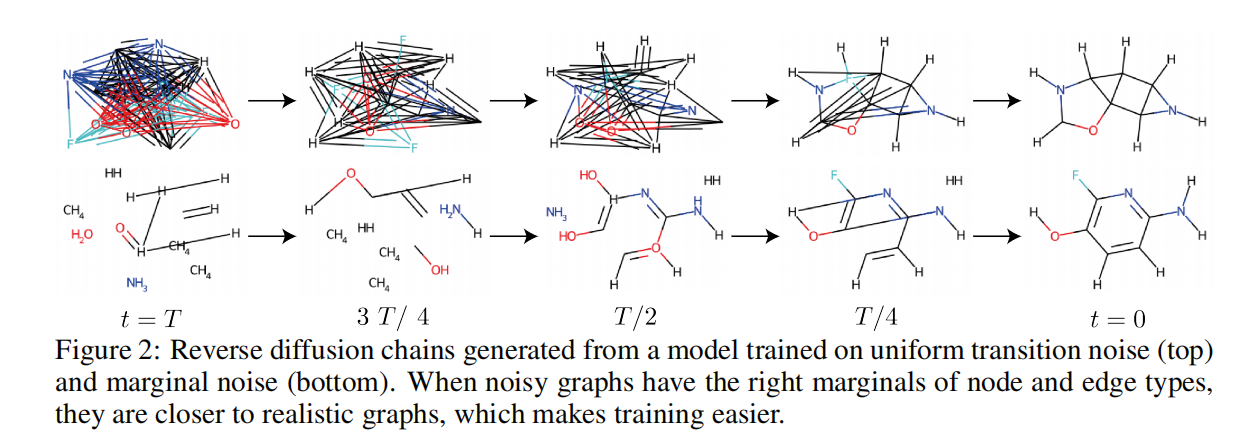
生成过程需要T步,这是比较慢的。生成Graph时,需要先根据训练集中数据的边缘分布,采样得到GT。这能极大增强生成数据的效果,使得训练过程更容易收敛。
优点与不足
优点
- 作为发表于顶会ICLR的文章,DIGRESS是第一个把Diffusion直接应用在原始离散数据图(Graph)上的算法,并取得了State-of-the-art的效果。它考虑了在离散场景下,噪声的特殊性,设计出了针对性的噪声。
- DIGRESS创造性地提出了根据边缘分布进行噪声采样的方式,极大地提高了模型的训练速度,保证了模型的收敛。
- 训练过程中,DIGRESS把图(Graph)生成的问题,十分巧妙地转换成了边与节点的分类问题。
不足
DIGRESS最大的问题就是效率低。这个效率低体现在三个方面:
- 生成Graph时,需要进行T步的去噪过程;
- 边属性是一个N*N*de维度的张量。当Graph的节点数N变大时,这个张量的大小会指数增长,从而导致效率低;
- 在使用过程中,需要计算Graph的谱信息。这涉及到了矩阵的特征分解,这个过程计算量也是很大的;
综上,DIGRESS提出了在离散数据Graph上的Diffusion过程,但它并不适用于Graph规模比较大的场景。



















 1139
1139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











