






Vector Quantized Diffusion Model for Text-to-Image Synthesis
公和众与号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
我们提出了基于矢量量化扩散(VQ-Diffusion)的文本到图像生成模型。这种方法基于矢量量化变分自动编码器(VQ-VAE),其潜在空间由最近开发的去噪扩散概率模型(DDPM)的条件变体建模。我们发现,这种潜在空间方法非常适用于文本到图像生成任务,因为它不仅消除了现有方法的单向偏差,还允许我们采用掩码替换扩散策略来避免错误的积累,这是现有方法的一个严重问题。我们的实验表明,与具有相似参数数量的传统自回归(AR)模型相比,VQ-Diffusion 在文本到图像生成方面产生了显着更好的结果。与先前基于 GAN 的文本到图像方法相比,我们的 VQ-Diffusion 可以处理更复杂的场景,并大幅提高合成图像的质量。最后,我们展示了我们方法中的图像生成计算可以通过重新参数化而变得非常高效。使用传统的 AR 方法,文本到图像生成时间随着输出图像分辨率的增加而线性增加,因此即使对于普通大小的图像来说也非常耗时。VQ-Diffusion 允许我们在质量和速度之间取得更好的平衡。我们的实验表明,具有重新参数化的 VQ-Diffusion 模型比传统的 AR 方法快 15 倍,同时实现更好的图像质量。代码和模型可在 https://github.com/cientgu/VQ-Diffusion 获取。
4. 矢量量化扩散模型
给定文本-图像对,我们使用预训练的 VQ-VAE 获取离散图像标记 x ∈ Z^N,其中 N = h·w 表示标记序列的长度。假设 VQ-VAE 码书的大小为 K,位于位置 i 处的图像标记 x_i 取得指定码书条目的索引,即 x_i ∈ {1, 2, ..., K}。另一方面,文本标记 y ∈ Z^M 可以通过 BPE 编码 [56] 获得。 整体的文本到图像框架可以看作是最大化条件转移分布 q(x|y)。
先前的自回归模型,例如 DALL-E [48] 和 CogView [13],依次预测每个图像标记,取决于文本标记以及先前预测的图像标记,即
![]()
虽然在文本到图像合成中取得了显著的质量,但自回归建模存在一些限制。首先,图像标记按照单向顺序(例如,光栅扫描)进行预测,这忽略了 2D 数据的结构并限制了图像建模的表现力,因为特定位置的预测不应仅关注左侧或上方的上下文。其次,存在训练-测试差异,因为训练使用 ground truth,而推断依赖于先前标记的预测。所谓的 “教师强迫(teacher-forcing)” 实践 [15] 或曝光偏差(exposure bias) [54] 导致由于先前采样中的错误而积累错误。此外,它需要网络进行前向传递以预测每个标记,即使对于低分辨率(即 32 × 32)潜在空间的采样,这也消耗了大量时间,使得自回归模型在实际使用中不切实际。
我们的目标是以非自回归的方式对 VQ-VAE 潜在空间进行建模。提出的 VQ-Diffusion 方法通过扩散模型 [23, 59] 最大化概率 q(x|y),这是一种新兴方法,对图像合成产生了引人注目的质量 [12]。尽管大多数最近的工作都集中在连续扩散模型上,但将它们用于分类分布的研究要少得多 [1, 26]。在这项工作中,我们建议使用其条件变体离散扩散过程进行文本到图像生成。接下来,我们将介绍受到掩码语言建模(masked language modeling,MLM)[11] 启发的离散扩散过程,然后讨论如何训练神经网络来反转这个过程。
4.1 离散扩散过程
在高层次上,前向扩散过程通过固定的马尔可夫链 q(x_t | x_(t-1)) 逐渐破坏图像数据 x_0,例如,随机替换 x_(t-1) 的一些标记。经过固定数量的 T 个时间步之后,前向过程产生一系列逐渐变噪的潜在变量 z_1; ...; z_T,其维度与 z_0 相同,而 z_T 成为纯噪声标记。从噪声 z_T 开始,反向过程逐渐去噪潜在变量并通过从逆向分布 q(x_(t-1) | x_t, x_0) 中顺序采样来恢复真实数据 x_0。然而,由于在推理阶段 x_0 是未知的,我们训练一个 transformer 网络来近似,获得取决于整个数据分布的条件转移分布 p_θ(x_(t-1) | x_t, y) 。
具体来说,考虑 x_0 中位置 i 处的单个图像标记 x^i_0,它取得指定码书条目的索引,即,x_i ∈ {1; 2; ...; K}。在以下描述中,为避免混淆,我们省略上标 i。我们使用矩阵
![]()
![]()
定义 x_(t-1) 转移到 x_t 的概率。然后,整个标记序列的前向马尔可夫扩散过程可以写成:
![]()
其中 v(x) 是一个长度为 K 的 one-hot 列向量,仅在 x 处的条目为 1。对于 x_t 的分类分布由向量 Q_t·v(x_(t-1)) 给出。
重要的是,由于马尔可夫链的性质,可以边际化中间步骤并直接从 x_0 推导出任意时间步上 x_t 的概率,如下:
![]()
此外,另一个显著的表征是以 x_0 为条件,这个扩散过程的后验是可计算的,即,
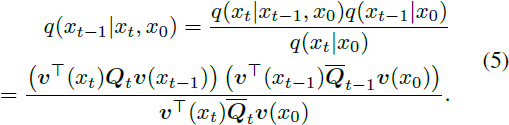
转移矩阵 Q_t 对于离散扩散模型至关重要,应该经过精心设计,使得反向网络不太难以从噪声中恢复信号。
先前的研究 [1, 26] 建议在分类分布中引入一小部分均匀噪声,过渡矩阵可以被表达为,
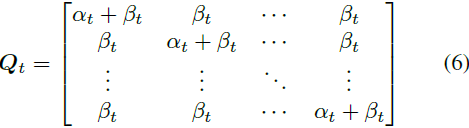
![]()
每个标记有概率 (α_t + β_t) 保持当前步骤的先前值,同时有概率 K _t 被均匀重新抽样到所有 K 个类别中。
然而,使用均匀扩散进行数据破坏是一个相当激进的过程,可能对反向估计构成挑战。首先,与用于有序数据的高斯扩散过程相反,图像标记可能被替换为一个完全不相关的类别,从而导致该标记的语义突变。其次,网络必须额外努力来找出在修复之前已被替换的标记。实际上,由于局部上下文中存在的语义冲突,不同图像标记的反向估计可能形成竞争,并陷入识别可靠标记的困境。
掩码替换扩散策略。为了解决均匀扩散的上述问题,我们从掩码语言建模 [11] 中汲取灵感,并建议通过随机掩蔽其中一些标记来破坏它们,以便反向网络可以明确知道破坏的位置。具体而言,我们引入一个额外的特殊标记,[MASK] 标记,因此现在每个标记都有 (K + 1) 个离散状态。我们定义掩码扩散如下:每个普通标记有概率 γ_t 被 [MASK] 标记替换,并有概率 K·γ_t 被均匀扩散,有概率
![]()
保持不变,而 [MASK] 标记始终保持其自己的状态。因此,我们可以将转移矩阵 Q_t 形式化为:
![]()
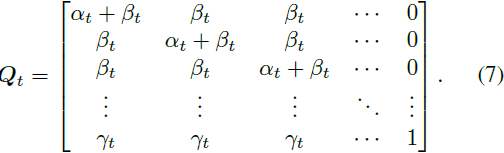
这种掩码-替换的转移矩阵的好处是:
- 损坏的标记对于网络是可区分的,这简化了反向过程。
- 与 [1] 中的仅使用掩码的方法相比,我们在理论上证明了除了标记掩蔽之外,还有必要包括一小部分均匀噪声,否则在 x_t ≠ x_0 时我们将得到一个微不足道的后验。
- 随机标记替换迫使网络理解上下文,而不仅仅关注 [MASK] 标记
- 方程 4 中的累积转移矩阵 Q_t 和概率 q(x_t | x_0) 可以通过以下公式进行封闭形式计算:
![]()
![]()
![]()
其中,-β_t 可以预先计算并存储。因此,计算 q(x_t | x_0) 的计算成本从 O(t·K^2) 减少到 O(K)。证明详见补充材料。
4.2 学习反向过程
为了反转扩散过程,我们训练一个去噪网络 p_θ(x_(t-1) | x_t; y) 来估计后验转移分布 q(x_(t-1) | x_t, x_0)。该网络被训练以最小化变分下界(VLB)[59]:

其中,p(x_T) 是时间步 T 的先验分布。对于提出的掩码替换扩散,先验分布为:
![]()
请注意,由于训练中转移矩阵 Q_t 是固定的,因此 L_T 是一个常数,用于衡量训练和推断之间的差距,在训练中可以忽略。
离散阶段的重新参数化技巧。网络参数化显著影响合成质量。与直接预测后验 q(x_(t-1) | x_t, x_0) 不同,最近的研究 [1, 23, 26] 发现近似一些替代变量,例如无噪声的目标数据 q(x_0),可以提供更好的质量。在离散设置中,我们让网络在每个反向步骤预测无噪声标记分布 p(x̃_0 | x_t, y)。因此,我们可以根据以下计算反向转移分布:
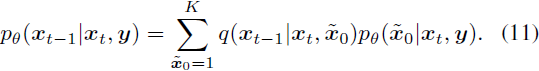
基于重新参数化技巧,我们可以引入一个辅助的去噪目标,鼓励网络预测无噪声的标记 x_0:
![]()
我们发现将这个损失与 L_VLB 结合起来可以提高图像质量。
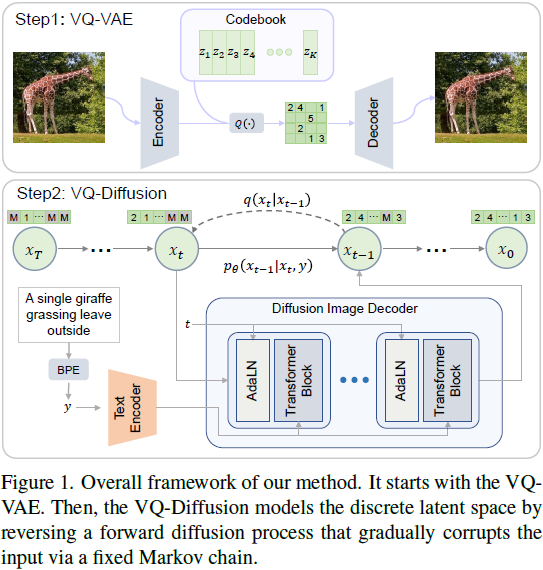
模型架构。我们提出了一个编码器-解码器 transformer 来估计分布 p(x̃_0 | x_t; y)。如图 1 所示,该框架包含两个部分:文本编码器和扩散图像解码器。我们的文本编码器接受文本标记 y 并生成一个条件特征序列。扩散图像解码器接受图像标记 x_t 和时间步 t,并输出无噪声标记分布 p(x̃_0 | x_t, y)。解码器包含多个 transformer 块和一个 softmax 层。每个 transformer 块包含一个完整注意力层,一个用于合并文本信息的交叉注意力层以及一个前馈网络块。 当前时间步 t 被注入到网络中,使用自适应层归一化[2](AdaLN)运算符,即
![]()
其中 h 是中间激活,a_t 和 b_t 是从时间步嵌入的线性投影得到的。
快速推理策略。在推理阶段,通过利用重新参数化技巧,我们可以跳过扩散模型中的一些步骤以实现更快的推理。
具体而言,假设时间步长为 △_t,我们不是在 x_T; x_(T-1); x_(T-2), ..., x_0 的链中采样图像,而是在 x_T; x_(T - △_t); x_(T - 2 △_t), ..., x_0 的链中使用反向转移分布采样图像:
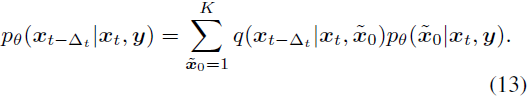
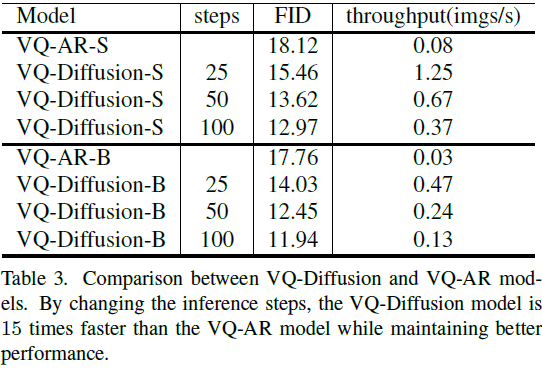
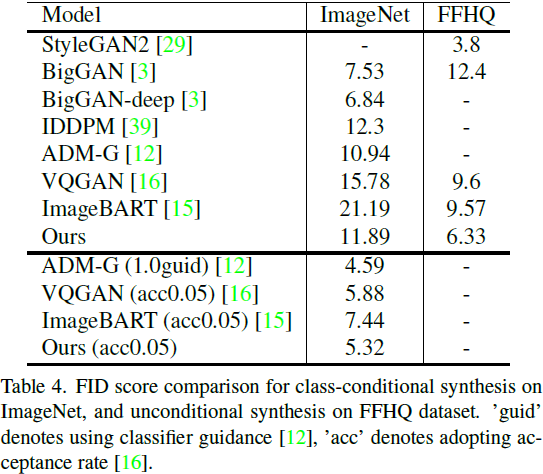
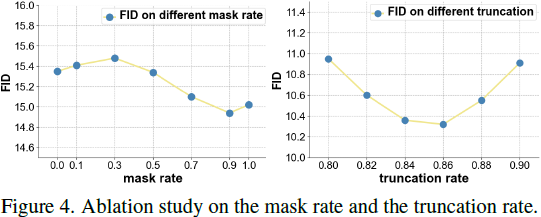
我们发现这使得采样更加高效,对质量的影响很小。整个训练和推理算法如算法 1 和 2 所示。


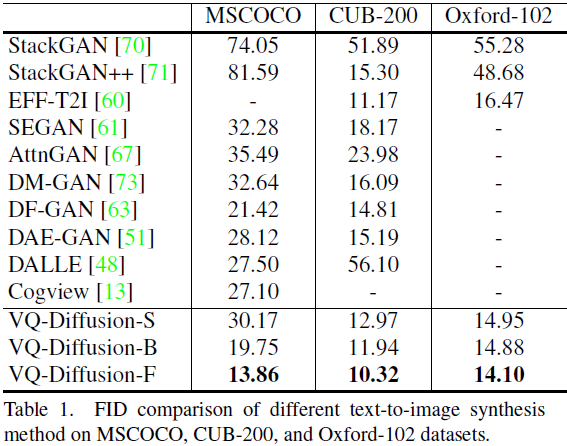
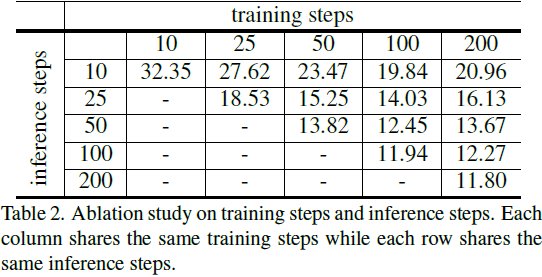
5. 实验


















 2693
2693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









