






1.Bn层详解
https://blog.csdn.net/qq_37100442/article/details/81776191
1)BN层在网络中的作用

BN层是一种批规范化操作,公式为减均值除标准差,然后乘γ加β。将输入分布归一化到0,1分布,使得激活函数更好的作用,因此解决了梯度消失的问题。同时由于数据被归一化,使得网络可以有更好的收敛速度。但是似乎没有证据表明它可以解决高层的网络输入分布变化剧烈的问题(Internal Covariate Shift).
2)BN层为何要变换重构
尽可能还原出之前的分布,让下层神经元学习到的分布不会被破坏。
3)bn层如何解决梯度消失问题,保证网络的稳定性 https://zhuanlan.zhihu.com/p/33006526
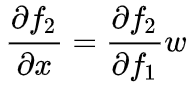反向传播式子中有w的存在,所以 w的大小影响了梯度的消失和爆炸,batchnorm就是通过对每一层的输出做scale和shift的方法,通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到接近均值为0方差为1的标准正太分布,即严重偏离的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,使得让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。](https://i-blog.csdnimg.cn/blog_migrate/5646976e8169bd80dd8d95f3ec7ec726.png)
4)BN训练和测试时的区别?
训练时用当前batch计算均值方差 测试时用所有batch累积的。
5)BN层有哪些超参数?
momentum、affine、track_running_stats 。
6)BN层优点
- 加快训练速度,增大学习率、即使小的学习率也能用快速的学习速率。
- 不用理会拟合中的dropout l2参数 只需要小的L2正则项约束 :
BN算法后,参数进行了归一化,原本经过激活函数没有太大影响的神经元,分布变得明显。经过一个激活函数后,神经元会自动削弱或者减去一些神经元,就不用再对其进行dropout. - 对于L2,由于每次训练都进行了归一化,就很少发生由于数据分布不同导致的参数变动过大,带来的参数不断增大。
- 可以把训练数据集打乱,防止训练发生偏移
2.卷积神经网络相关
1)卷积层的参数量计算:

2)卷积层的计算量

- LeNet5:最早的卷积神经网络,卷积层+AveragePooling+全连接
- AlexNet :ReLU增强非线性,DropOut避免过拟合,MaxPooling,GPU
- VGG: 更小的卷积核(3 * 3)
NIN,1 * 1卷积核 - Inception v1:通过1*1的卷积核,减少特征的数量;通过不同大小的卷积核,增大了网络的宽度和尺度适应性。

激活函数
1.常用激活函数的比较
https://zhuanlan.zhihu.com/p/32610035
激活函数给神经元引入了非线性因素,如果不用激活函数的话,无论神经网络有多少层,输出都是输入的线性组合。

2.激活函数以0为中心
https://liam.page/2018/04/17/zero-centered-active-function/
Sigmoid函数的输出不是以零为中心,会导致神经网络收敛较慢。

参数更新
因此各个 更新方向之间的差异,完全由对应的输入值 的符号决定。

以零为中心的影响
“ Z 字形更新”

过拟合
https://zhuanlan.zhihu.com/p/68488202
- L1正则化是指权重矩阵中各个元素的绝对值之和。
为了优化正则项,会减少参数的绝对值总和,所以L1正则化倾向于选择稀疏(sparse)权重矩阵(稀疏矩阵指的是很多元素都为0,只有少数元素为非零值的矩阵)。L1正则化主要用于挑选出重要的特征,并舍弃不重要的特征。(相当于进行了特征筛选) - L2正则化是指权重矩阵中各个元素的平方和。
为了优化正则项,会减少参数平方的总和,所以L2正则化倾向于选择值很小的权重参数(即权重衰减),主要用于防止模型过拟合。是最常用的正则化方法。
- 为何引入正则化项就能防止过拟合呢?
- 通过引入权重参数来限制模型的复杂度,从而提高模型的泛化能力。
- L2正则化可以对大数值权重进行惩罚,这使得没有哪个特征能够单独对整个模型有过大的影响,即每个维度对最终结果的影响都不是很大,使模型把大多数维度上的特征都利用起来,而不是只依赖其中少数几个特征。(选择值很小的权重参数)。
- 过拟合的时候,拟合函数的系数往往非常大(顾及每个点,形成的拟合函数波动大:系数大 后验概率)
- 增加数据
数据增强 - 提前停止(early stopping)
在模型开始过拟合之前就中断学习过程















 1103
1103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









