







LoRA
前面提到, Adapter Tuning 存在训练和推理延迟, Prefix Tuning 难训且会减少原始训练数据中的有效文 字长度, 那是否有一种微调办法, 能改善这些不足呢, 在这样的动机驱动下, 有研究者提出了 LoRA(论文:LoRA: Low-Rank Adaptation of Large Language Models) ,LoRA 是 Low-Rank Adaptation 的简写, 它冻结了预先训练好的 模型权重, 通过低秩分解来模拟参数的改变量, 大大减少了下游任务的可训练参数的数量, 对于使用 LoRA 的 模型来说, 由于可以将原权重与训练后权重合并, 因此在推理时不存在额外的开销。与用 Adam 微调的 GPT-3 175B 相比, LoRA 可以将可训练参数的数量减少 10,000 倍,对 GPU 内存的要求减少 3 倍。
有研究表明, 训练得到的过度参数化模型实际上位于一个低的内在维度上。假设模型适应过程中权重的变 化也具有较低的” 内在秩”,从而提出的低秩适应(LoRA) 方法。LoRA 通过优化密集层在适应过程中的变化的 秩分解矩阵来间接地训练神经网络中的一些密集层, 而保持预训练的权重冻结, 在涉及到矩阵相乘的模块, 在 原始的预训练权重旁边增加一个新的通路,通过前后两个矩阵 A,B 相乘,第一个矩阵 A 负责降维,第二个矩阵 B 负责升维,中间层维度为 r ,从而来模拟所谓的本征秩(intrinsic rank),如下图所示。
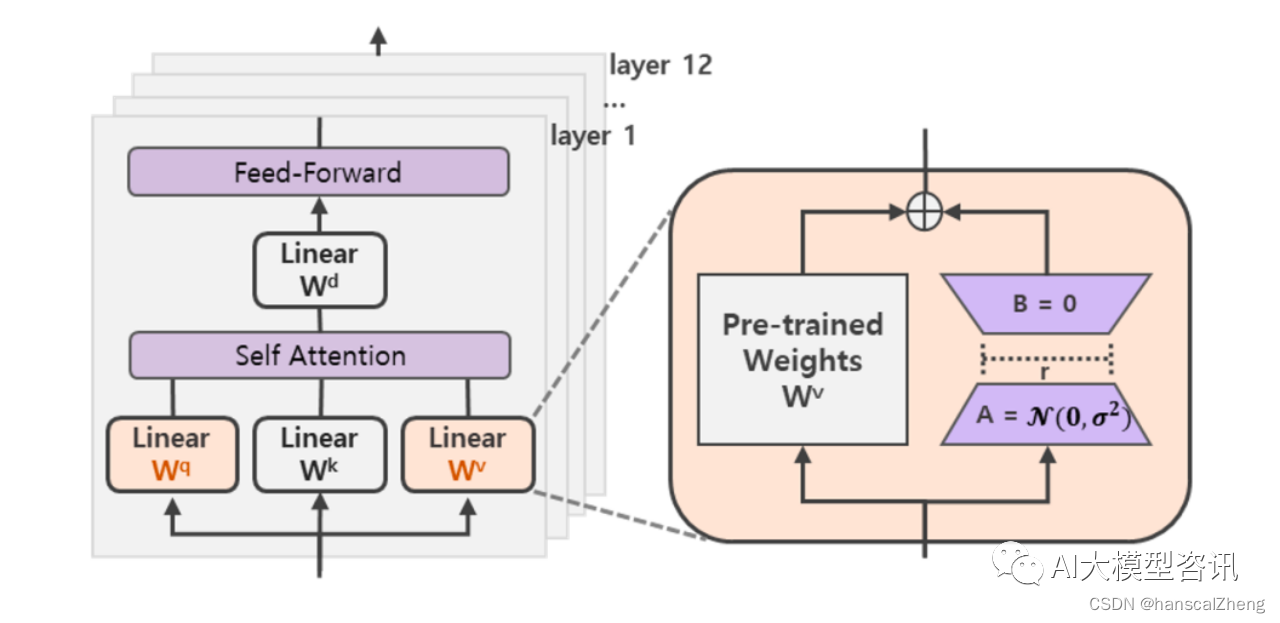
在 Transformer 模块中 LoRA 的位置和结构示例
在下面的结构图中, 将 Transformer 层的输入和输出二层大小表示为 d,用 Wq ,Wk ,Wv 和 Wo 来指代在自 我注意模块中的查询/键/值/输出投影矩阵。W ∈ Rd∗d 指的是预先训练好的权重矩阵, 6W 是它在适应过程中的累积梯度更新。用 r 来表示一个 LoRA 模块的秩。使用 Adam 进行模型优化, 使用 Transformer MLP 前馈维度 df f n = 4 × d。在 LoRA 中,用矩阵 A 和 B 来近似来表示 δW :
-
A ∈ Rr∗d :低秩矩阵 A,其中被称为“秩”,对 A 采用高斯初始化。
-
B ∈ Rd∗r :低秩矩阵 B,对 B 采用零初始化。
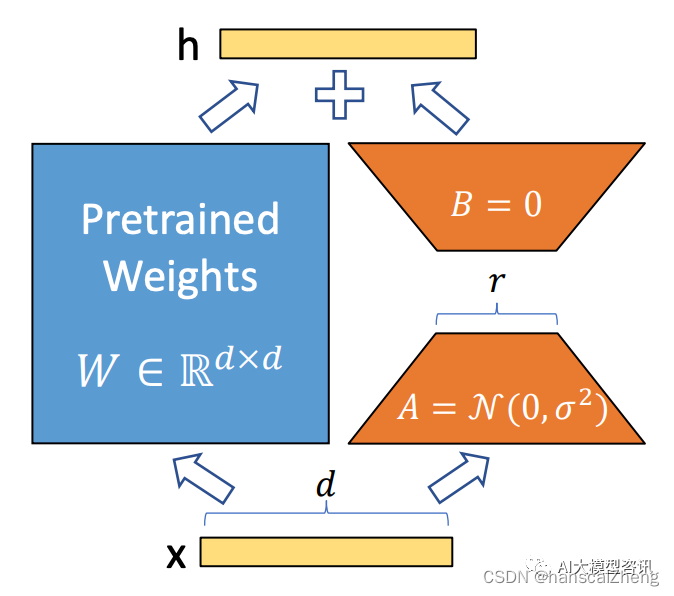
LoRA 的详细结构示例
对于一个预先训练好的权重矩阵 W ∈ Rd∗d ,通过用一个低秩变换来限制其更新。组成 W + δW = W + BA, 在训练期间, W 被冻结, 不接受梯度更新, 而 A 和 B 包含可训练参数。这里的 W 和 W = BA 都与相同的输入相乘,它们各自的输出向量是按坐标相加的。对于 h = Wx,修改后的前向传递得到:
![]()
在上图中也说明了这个重新参数化过程。对 A 使用随机高斯初始化, 对 B 使用零初始化, 所以 δW 在训练 开始时是零。然后,将 δWx 的缩放为 ,α 是r 中的一个常数,一般取 α ≥ r 。
这里有一个超参数 α, 文章中的解释是, 当用 Adam 进行优化时, 如果适当地调整缩放初始化, 调整 α 与调 整学习率大致相同。因此, 只需将 α 设置为尝试的第一个 r ,而不对其进行调整。这种缩放有助于减少在改变 r时重新调整超参数的需要。在上面公式中, W 表示预训练权重(旧知识), Wx + BAx 表示增量权重 δW 的近 似(新知识)。理论上说, 当 r 较小时, 提取的是 δW 中信息含量最丰富的维度, 此时信息精炼, 但不全面; 当 较大时, 我们的低秩近似越逼近, 此时信息更加全面, 但带来的噪声也越多(含有很多冗余无效的信息)。把 α固定住,意味着随着 r 的减小, 会越来越大,即这样做的原因是:
-
当 r 越小时, 低秩矩阵表示的信息精炼, 但不全面。通过调大 ,来放大 forward 过程中新知识对模型的影响。
-
当 r 越小时, 低秩矩阵表示的信息精炼, 噪声/冗余信息少, 此时梯度下降的方向也更加确信, 所以可以通 过调大 ,适当增加梯度下降的步伐,也就相当于调整 learning rate 了。
上图中展示的是在原始预训练矩阵的旁路上, 用低秩矩阵 A 和 B 来近似替代增量更新。你可以在你想要 的模型层上做这样的操作, 比如 Transformer 中的、 MLP 层的权重、甚至是 Embedding 部分的权重。在 LoRA 原 始论文中, 只对 Attention 部分的参数做了低秩适配, 但在实际操作中, 可以灵活根据需要设置实验方案, 找到 最佳的适配方案。
研究者做了实验来验证 LoRA 低秩矩阵的有效性, 首先, 将 LoRA 和其余微调方法(全参数微调, Adatper Tuning 等) 做了比较。无论是在各个数据集微调准确率指标上, 还是在最后平均微调准确率指标上(Avg. ),LoRA 都取得了不错的表现, 而且它可训练的参数量也非常小。在实操中, 例如在 LoRA 源码对 GPT2 微调, 做 NLG 任务时,就取 α = 32, r = 4。
LoRA 有几个优势:
-
一个预先训练好的模型可以被共享, 并用于为不同的任务建立许多小的 LoRA 模块。可以冻结共享模型,并通过替换图中的矩阵 A 和 B 来有效地切换任务,从而大大降低存储需求和任务切换的难度。
-
LoRA 使训练更加有效, 在使用自适应优化器时, 硬件门槛降低了 3 倍, 因为我们不需要计算梯度或维护 大多数参数的优化器状态。相反,只优化注入的、小得多的低秩矩阵。
-
简单的线性设计允许我们在部署时将可训练矩阵与冻结权重合并, 与完全微调的模型相比, 在结构上没有 引入推理延迟。
-
LoRA 与许多先前的方法是正交的,并且可以与许多方法相结合,例如前缀调整。
peft 库中含有包括 LoRA 在内的多种高效微调方法, 且与 transformer 库兼容。使用示例如下所示。其中, lora_alpha α 表示放缩系数。表示参数更新量的 W 会与 α/r 相乘后再与原本的模型参数相加。

接下来介绍 peft 库对 LoRA 的实现, 也就是上述代码中 get_peft_model 函数的功能。该函数包裹了基础模型 并得到一个 PeftModel 类的模型。如果是使用LoRA 微调方法,则会得到一个 LoraModel 类的模型。

LoraModel 类通过add_adapter 方法添加LoRA 层。该方法包括_find_and_replace 和_mark_only_lora_as_trainable 两个主要函数。_mark_only_lora_as_trainable 的作用是仅将Lora 参数设为可训练,其余参数冻结;_find_and_replace 会根据 config 中的参数从基础模型的 named_parameters 中找出包含指定名称的模块 (默认为“q”、“v ”,即注意 力模块的 Q 和 V 矩阵),创建一个新的自定义类 Linear 模块,并替换原来的。

创建 Linear 模块时, 会将原本模型的相应权重赋给其中的 nn.linear 部分。另外的 LoraLayer 部分则是 Lora 层,在 update_adapter 中初始化。Linear 类的 forward 方法中, 完成了对 LoRA 计算逻辑的实现。这里的 self.scaling [self.active_adapter] 即 lora_alpha/r。
对于 GPT-3 模型, 当 r=4 且仅在注意力模块的 Q 矩阵和 V 矩阵添加旁路时, 保存的检查点大小减小了 10000 倍 (从原本的 350GB 变为 35MB),训练时 GPU 显存占用从原本的 1.2TB 变为 350GB,训练速度相较全量参数微 调提高 25%。
AdaLoRA
LoRA 对预训练权重的增量更新进行建模, 而无需修改模型架构, 即 W + 6W ,该方法可以达到与完全微调 几乎相当的性能, 但是也存在一些问题, LoRA 需要预先指定每个增量矩阵的本征秩 r 相同, 忽略了在微调预训 练模型时, 权重矩阵的重要性在不同模块和层之间存在显著差异, 并且只训练了 Attention,没有训练 FFN,事 实上 FFN 更重要。基于以上问题进行总结:
-
不能预先指定矩阵的秩, 需要动态更新增量矩阵的秩, 因为权重矩阵的重要性在不同模块和层之间存在显 著差异。
-
需要找到更加重要的矩阵, 分配更多的参数, 裁剪不重要的矩阵。找到重要的矩阵, 可以提升模型效果;而 裁剪不重要的矩阵,可以降低参数计算量,降低模型效果差的风险。
AdaLoRA (论文:AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning), 是对 LoRA 的 一种改进, 它根据重要性评分动态分配参数预算给权重矩阵。在 AdaLoRA 中, 以奇异值分解的形式对权重矩阵 的增量更新进行参数化。然后,根据新的重要性指标,通过操纵奇异值,在增量矩阵之间动态地分配参数预算。 这种方法有效地提高了模型性能和参数效率。具体做法如下:
-
调整增量矩分配。AdaLoRA 将关键的增量矩阵分配高秩以捕捉更精细和任务特定的信息, 而将较不重要 的矩阵的秩降低,以防止过拟合并节省计算预算。
-
以奇异值分解的形式对增量更新进行参数化, 并根据重要性指标裁剪掉不重要的奇异值, 同时保留奇异向 量。由于对一个大矩阵进行精确 SVD 分解的计算消耗非常大, 这种方法通过减少它们的参数预算来加速 计算,同时,保留未来恢复的可能性并稳定训练, 如下面公式所示。
-
在训练损失中添加了额外的惩罚项, 以规范奇异矩阵 P 和 Q 的正交性, 从而避免 SVD 的大量计算并稳定 训练。
为了达到降秩且最小化目标矩阵与原矩阵差异的目的, 常用的方法是对原矩阵进行奇异值分解并裁去较小 的奇异值。然而, 对于大语言模型来说, 在训练过程中迭代地计算那些高维权重矩阵的奇异值是代价高昂的。因 此, AdaLoRA 由对可训练参数 W 进行奇异值分解,改为令 W = P ΛQ(P ΛQ 为可训练参数) 来近似该操作。
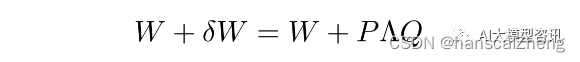
上式中, P ∈ Rd_1 ×r, Q ∈ Rr×d2 ,分别表示δW 的左、右奇异向量, 对角矩阵 Λ ∈ Rr ×r 。Λ 为对角矩阵, 可用一 维向量表示;P 和 Q 应近似为酉矩阵,需在损失函数中添加以下正则化项:
![]()
在通过梯度回传更新参数, 得到权重矩阵及其奇异值分解的近似解之后, 需要为每一组奇异值及其奇异向量 {Pk,i , λk,i , Qk,i } 计算重要性分数 S。其中下标 k 是指该奇异值或奇异向量属于第 k 个权重矩阵, 上标 t 指 训练轮次为第 t 轮。接下来根据所有组的重要性分数排序来裁剪权重矩阵以达到降秩的目的。有两种方法定义该 矩阵的重要程度。一种方法直接令重要性分数等于奇异值,另一种方法是用下式计算参数敏感性:
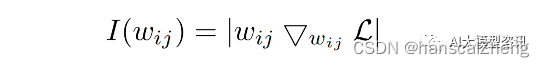
其中, wij 表示可训练参数。该式估计了当某个参数变为 0 后, 损失函数值的变化。因此, I(wij ) 越大, 表示模型 对该参数越敏感, 这个参数也就越应该被保留。该敏感性度量受限于小批量采样带来的高方差和不确定性, 因 此并不完全可靠。有研究者提出了一种新的方案来平滑化敏感性,以及量化其不确定性。
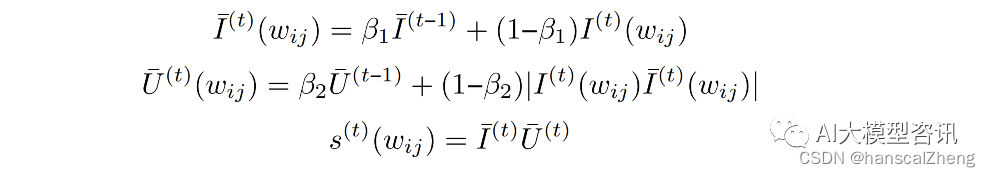
通过实验对上述几种重要性定义方法进行了对比, 发现由上面公式中间等式计算得到的重要性分数, 即平滑后的参数敏 感性,效果最优。故而最终的重要性分数计算式为:
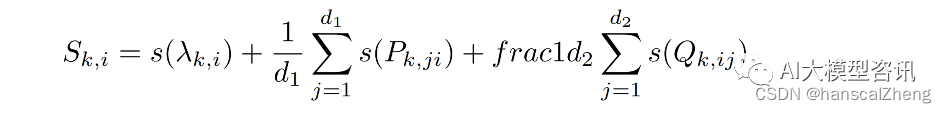
QLoRA
虽然最近的量化方法可以减少LLM 的内存占用,但此类技术仅适用于推理场景。基于此,作者提出了QLoRA, 并首次证明了可以在不降低任何性能的情况下微调量化为 4 bit 的模型。
QLoRA (论文:QLORA: Efficient Finetuning of Quantized LLMs),其并没有对 LoRA 的逻辑作出修改, 而是 通过将预训练模型量化为 4-bit 以进一步节省计算开销。使用一种新颖的高精度技术将预训练模型量化为 4 bit, 然后添加一小组可学习的低秩适配器权重, 这些权重通过量化权重的反向传播梯度进行微调。QLORA 有一种低 精度存储数据类型(4 bit),还有一种计算数据类型(BFloat16)。实际上, 这意味着无论何时使用 QLoRA 权重张 量, 我们都会将张量反量化为 BFloat16,然后执行 16 位矩阵乘法。QLoRA 提出了两种技术实现高保真 4 bit 微 调——4 bit NormalFloat(NF4) 量化和双量化。此外, 还引入了分页优化器, 以防止梯度检查点期间的内存峰值, 从而导致内存不足的错误, 这些错误在过去使得大型模型难以在单台机器上进行微调。QLoRA 可以将 650 亿参 数的模型在单张 48GBGPU 上微调并保持原本 16-bit 微调的性能。QLoRA 的主要技术为:
-
新的数据类型 4bit NormalFloat (NF4):对于正态分布权重而言, 一种信息理论上最优的新数据类型, 该数 据类型对正态分布数据产生比 4 bit 整数和 4bit 浮点数更好的实证结果。这是一种新的 int4 量化方法, 灵 感来自信息论。NF4 量化可以保证量化后的数据和量化前具有同等的数据分布。意思就是 NF4 量化后, 权 重信息损失少,那么最后模型的整体精度就损失少。
-
双量化 (Double Quantization):对第一次量化后的那些常量再进行一次量化,减少存储空间。
-
分页优化器 (Paged Optimizers):使用 NVIDIA 统一内存特性, 该特性可以在在 GPU 偶尔 OOM 的情况下, 进行 CPU 和 GPU 之间自动分页到分页的传输, 以实现无错误的 GPU 处理, 可以从现象上理解成出现训 练过程中偶发 OOM 时能够自动处理, 保证训练正常训练下去。该功能的工作方式类似于 CPU 内存和磁盘 之间的常规内存分页。使用此功能为优化器状态(Optimizer) 分配分页内存, 然后在 GPU 内存不足时将 其自动卸载到 CPU 内存,并在优化器更新步骤需要时将其加载回 GPU 内存。
着重对上述的双量化进行介绍, 量化方法中假设权重近似服从均值为 0 的正态分布, 因此可以用其标准差 表示其分布。所以, 将一个权重张量进行量化后, 不仅需要将保存量化后的张量, 还需要额外一个 32 位的浮点 数以表示其标准差(即 c2fp32 ), 其占用 32 个比特的空间。因此, 如果只做第一次量化, 则需要额外存储的空间 (除了存储量化张量以外) 为 32 个比特, 假如张量的大小(blocksize, 即张量各个维度的乘积) 为 64,则其实就是 对 64 个数字进行量化,那额外需要的 32 比特平均到每个数字上,就是 32/64=0.5 比特。
NF4 基于分位数量化 (QuantileQuantization) 构建而成, 该量化方法使得使原数据经量化后, 每个量化区间中 的值的数量相同。具体做法是对数据进行排序并找出所有 k 分之一位数组成数据类型 (Datatype)。对于 4-bit 来 说, k = 24 = 16。然而该过程的计算代价对于大语言模型的参数来说是不可接受的。考虑到预训练模型参数通常呈均值为 0 的高斯分布, 因此可以首先对一个标准高斯分布 N(0,1) 按上述方法得到其 4-bit 分位数量化数据类 型, 并将该数据类型的值缩放至 [−1,1]。随后将参数也缩放至 [−1,1] 即可按通常方法进行量化。该方法存在的一 个问题是数据类型中缺少别对标准正态分布的非负和非正部分取分位数并取它们的并集, 组合成最终的数据类 型 NF4。
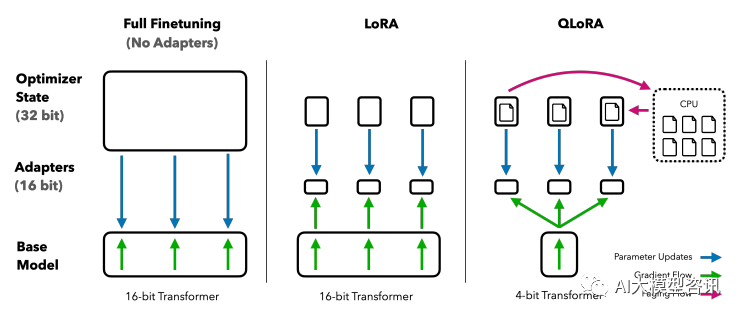
QLoRA 将 LoRA 的 Transformer 结构量化到 4 位精度,并利用分页优化器处理内存峰值。
由于 QLoRA 的量化过程涉及放缩操作, 当参数中出现一些离群点时会将其他值压缩在较小的区间内。为了 把这个额外空间进一步降低, 研究者将 C_2^{fp32} 进行进一步的量化, 因此提出分块量化, 减小离群点的影响范围。为了恢复量化后的数据, 需要存储每一块数据的放缩系数。如果用 32 位来存储放缩系数, 块的大小设为 64,放 缩系数的存储将为平均每一个参数带来 =0.5bits 的额外开销, 即 12.5% 的额外显存耗用。因此, 需进一步对这些 放缩系数也进行量化, 即双重量化。在 QLoRA 中, 每 256 个放缩系数会进行一次 8-bit 量化, 最终每参数的额 外开销由原本的 0.5bits 变为(8*256+32)/(64*256)=8/64+32/(64*256)=0. 127 比特, 即有 64*256 个数字需要量化, 那就将其分为 256 个 block,每 64 个数字划分到一个 block 中,对 64 个 block 中进行量化会产生 256 个C_2^{fp32}。为 了降低额外空间, 需要对这 256 个C_2^{fp32}进行第二次量化。具体做法是将其量化到 8 比特的浮点数格式(C_2^{fp8} ), 并且再用一个 FP32 表示这 256 个C_2^{fp32}的标准差, 即为C_1^{fp32}。所以, 对 64*256 个数字进行量化所需要的额外 空间为(8*256+32)/(64*256)=8/64+32/(64*256)=0. 127 比特, 量化每个数字所需要的额外空间从 0.5 减少到 0.127, 所以减少了 0.373 。注意不是每个权重值量化所需要的空间,而是所需要的额外空间。
ps: 欢迎扫码关注公众号^_^.


















 162
162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









