







文章主要探讨了多模态大语言模型(VLLMs)中的跨模态一致性问题。研究表明,尽管像GPT-4V这样的模型在文本和视觉任务中展现了出色的能力,但它们在不同模态下的表现存在显著差异,尤其是在面对相同任务实例时,文本和视觉模态的准确性差距较大。为了深入分析这种现象,文章提出了“跨模态一致性”的新概念,并基于这一概念构建了一个量化评估框架。实验结果表明,GPT-4V在视觉和语言模态下的表现并不一致,尽管两者传递的信息量相同。文章还提出了一种名为“视觉描绘提示(VDP)”的方法,旨在通过加强语言处理能力来提高跨模态一致性,并在多个任务中取得了显著的改善。通过这些研究,文章为如何优化和设计多模态系统提供了重要的见解。
1 跨模态一致性
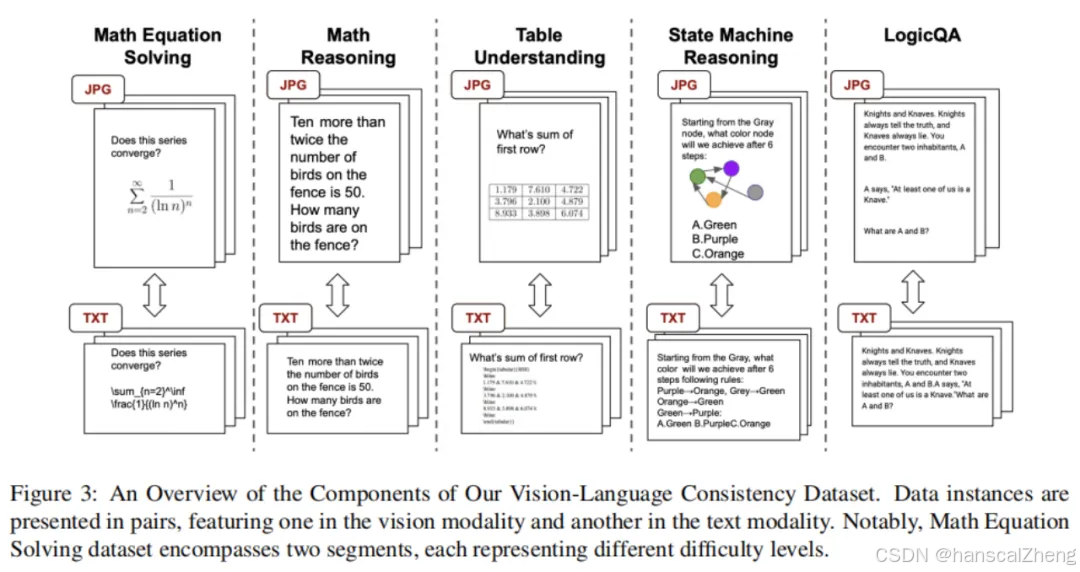
跨模态一致性是指在不同模态下(如文本和视觉)处理相同任务时,智能体的表现应保持一致,即相同的信息应当能通过不同模态传递并得出相同结果。
· 评估框架:文章提出了一个量化的评估框架,核心在于通过转换器将任务实例在不同模态间转换,确保转换过程中信息的完整性,进而评估智能体在不同模态下的表现一致性。
· 一致性度量:通过计算任务在不同模态下的输出一致性,定义了一个一致性评分,衡量智能体在视觉和语言模态下对同一任务的处理结果是否一致。
· 智能体行为的独立性:方法侧重于分析智能体在处理不同模态时是否表现出独立的推理过程,即语言和视觉模态是否影响智能体的推理和决策。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









