






文章目录
Deepseek官网卡顿:教你玩转蓝耘的Deepseek-R1/V3满血版,免费送500万Tokens,蓝耘元生代智算云平台是一个现代化的、基于 Kubernetes 的云平台,专为大规模 GPU 加速工作负载而构建。该平台速度可比传统云服务提供商快 35 倍,成本降低 30%,时延减少 50%,能够为 Deepseek-R1 满血版提供高效的算力支持和稳定的运行环境。平台基础设施的每个组件都经过精心设计,具备丰富的英伟达 GPU 系列资源、大规模纯 CPU 实例、完全托管的 Kubernetes、分布式和容错存储以及高性能的网络等,可满足不同用户在模型构建、训练和推理等业务全流程的需求。
一、前言
在数字浪潮汹涌澎湃的时代,程序开发宛如一座神秘而宏伟的魔法城堡,矗立在科技的浩瀚星空中。代码的字符,似那闪烁的星辰,按照特定的轨迹与节奏,组合、交织、碰撞,即将开启一场奇妙且充满无限可能的创造之旅。当空白的文档界面如同深邃的宇宙等待探索,程序员们则化身无畏的星辰开拓者,指尖在键盘上轻舞,准备用智慧与逻辑编织出足以改变世界运行规则的程序画卷,在 0 和 1 的二进制世界里,镌刻下属于人类创新与突破的不朽印记。
在人工智能飞速发展的今天,强大的语言模型为我们解决各类问题提供了极大的便利。蓝耘元生代智算云的 Deepseek-R1 满血版便是一款性能卓越的人工智能模型,它能够处理复杂的自然语言任务,帮助用户在科研、工作、学习等多个领域提升效率。本教程将详细介绍如何使用蓝耘元生代智算云的 Deepseek-R1 满血版,无论你是初次接触人工智能模型的新手,还是希望深入了解并高效运用该模型的专业人士,都能从本教程中获取到实用的信息。
二、准备工作
2.1 了解蓝耘元生代智算云
蓝耘元生代智算云是一个基于 Kubernetes 构建的现代化云平台,专为大规模 GPU 加速工作负载而设计。它具备以下优势:
高性能:速度可比传统云服务提供商快 35 倍,这意味着在运行 Deepseek-R1 这样的大型模型时,能够快速地给出结果,大大节省用户等待时间。
低成本:成本降低 30%,对于需要长期使用智算服务的企业和个人来说,能够有效控制开支。
低时延:时延减少 50%,保证了模型响应的及时性,让交互更加流畅。
2.2 注册与登录
访问官网:打开你常用的浏览器,在地址栏输入蓝耘元生代智算云的官方网址(请确保从官方渠道获取准确网址)。
注册账号:如果您是新用户,点击页面上的 “注册” 按钮。在注册页面,填写必要的信息,通常包括用户名、邮箱地址、密码等。用户名应简洁易记,且符合平台规定的命名规则;邮箱地址用于接收平台的重要通知和验证信息;密码需设置为强度较高的组合,包含字母、数字和特殊字符,以确保账号安全。填写完成后,点击 “注册” 按钮完成注册流程。
登录账号:注册成功后,返回官网首页,点击 “登录” 按钮。在登录页面输入您刚刚注册的用户名和密码,点击 “登录” 即可进入蓝耘元生代智算云平台。
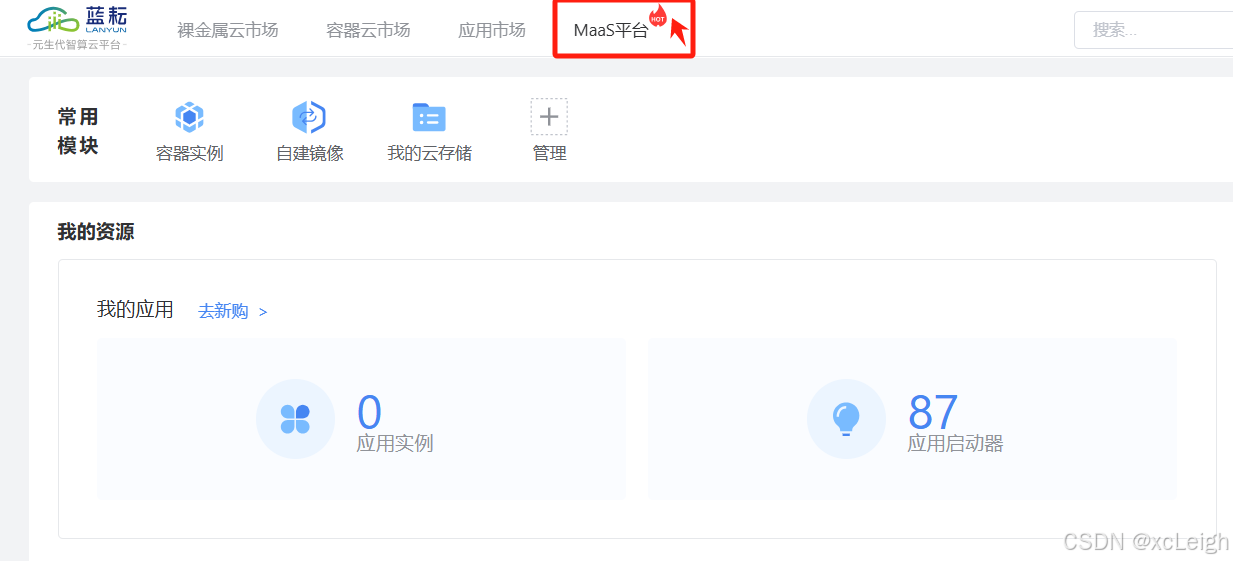
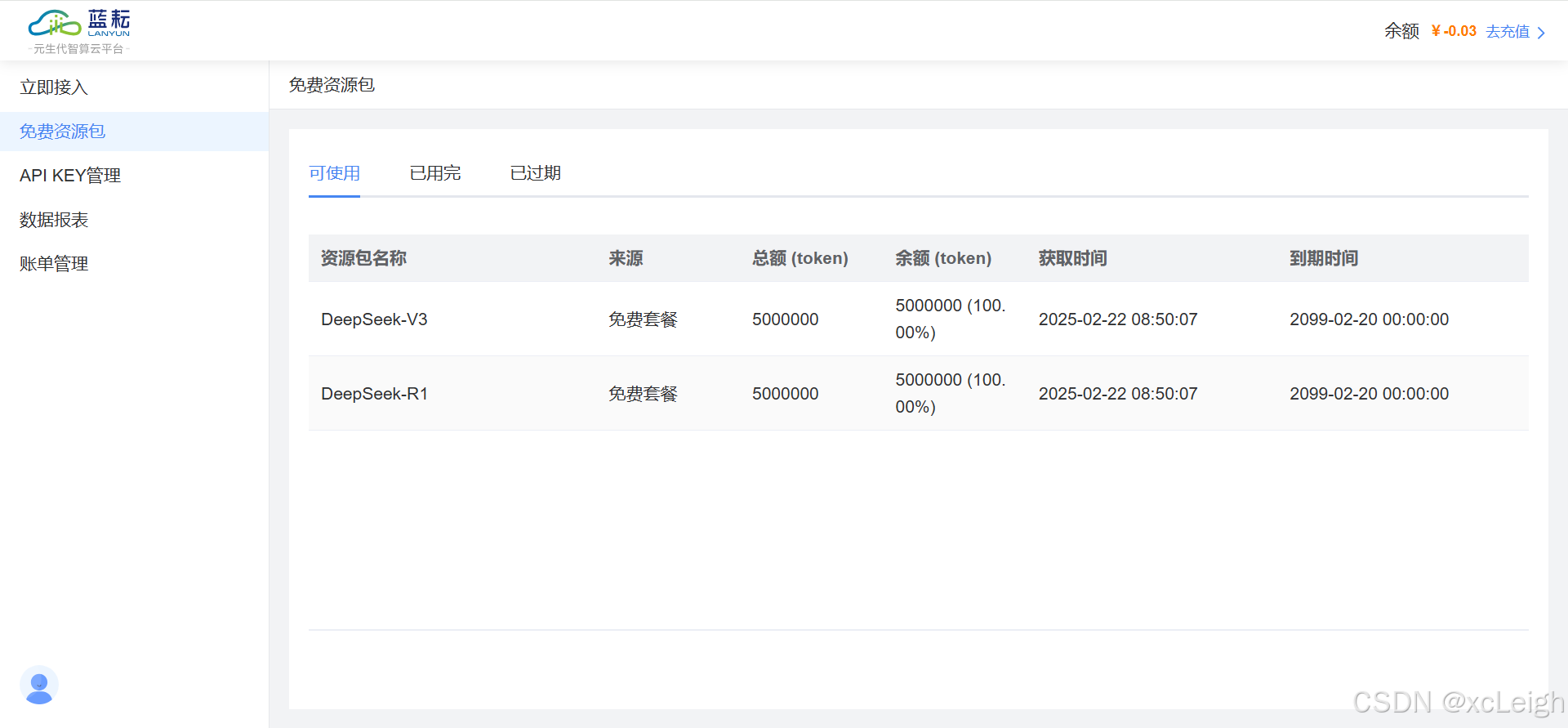
2.3 免费送500万Tokens
点击MaaS平台,进入免费资源包领取,有效期到2099年,免费送500万Tokens!!!
三、创建实例
3.1 进入实例创建页面
登录成功后,在平台的首页或主要操作界面中,找到 “创建空间” 或 “创建实例” 相关的按钮或入口。不同版本的平台界面可能略有差异,但通常该入口会在比较显眼的位置,方便用户快速找到。
3.2 选择应用
在实例创建页面的应用列表中,仔细查找 “Deepseek-R1” 应用。应用列表可能会按照不同的分类或排序方式展示,您可以通过搜索框输入 “Deepseek-R1” 来快速定位。
点击 “Deepseek-R1” 应用,选择该应用作为您要创建实例的基础。
3.3 选择算力与计费方式
算力配置:
理解算力概念:算力是指计算能力,在人工智能领域,强大的算力是运行大型模型的关键。对于 Deepseek-R1 满血版这样的大型语言模型,算力的高低直接影响到模型的运行速度和处理能力。蓝耘元生代智算云提供多种算力配置选项,例如不同数量和型号的 GPU(图形处理器)。GPU 在人工智能计算中发挥着重要作用,它能够并行处理大量数据,加速模型的计算过程。常见的 GPU 型号有 NVIDIA 的 A100、V100 等,不同型号的 GPU 在计算性能、显存大小等方面存在差异。
选择合适的算力:如果您只是进行一些简单的测试或小型任务,可以选择较低配置的算力,如配备少量 A100 GPU 的实例。这种配置成本相对较低,适合初步探索和学习。但如果您要处理大规模的文本数据、进行复杂的科研计算或商业应用开发,建议选择较高配置的算力,如配备多个 A100 GPU 的实例,以确保模型能够高效运行。
计费方式:
常见计费方式:蓝耘元生代智算云通常提供多种计费模式,主要包括按小时计费和按使用量计费。按小时计费是指根据您使用实例的时长来计算费用,每小时收取一定的费用。这种计费方式简单明了,适合使用时间相对固定的用户。按使用量计费则是根据您对模型的实际使用量,如处理的数据量、调用模型的次数等,来计算费用。这种计费方式更加灵活,能够根据您的实际业务需求进行收费。
选择计费方式:在选择计费方式时,您需要综合考虑自己的使用场景和预算。如果您的使用时间比较规律,且能够预估使用时长,按小时计费可能更适合您。例如,您每天固定使用模型进行几个小时的文本处理工作,按小时计费可以让您清楚地了解费用支出。如果您的使用量波动较大,且难以准确预估使用时间,按使用量计费可能更为经济实惠。比如,您在进行一个短期的项目,项目期间对模型的使用量会根据项目进展而变化,按使用量计费可以避免因预估不准而造成的费用浪费。
3.4 授权并完成实例创建
授权操作:在确认算力配置和计费方式后,需要进行授权操作。这通常涉及到阅读并同意平台的相关服务条款和隐私政策。这些条款和政策详细规定了您在使用平台服务过程中的权利和义务,以及平台对用户数据的保护措施等内容。请仔细阅读,确保您理解并接受其中的条款。阅读完成后,勾选相关的确认框,表示您同意授权。
创建实例:完成授权后,点击 “立即创建” 按钮。系统将开始为您创建 Deepseek-R1 实例,创建过程可能需要一定的时间,具体时长取决于平台的负载情况和您选择的算力配置。在创建过程中,页面会显示实例的创建进度,您可以耐心等待。当状态显示为 “运行中” 时,说明实例创建成功,您可以开始使用 Deepseek-R1 满血版模型。
四、连接与基本使用
4.1 连接到实例
打开交互界面:实例创建成功后,在平台的实例管理界面中,找到刚刚创建的 Deepseek-R1 实例,点击 “快速启动” 按钮。这将打开一个名为 openwebui 的交互界面,它是您与 Deepseek-R1 模型进行交互的主要窗口。
登录交互界面:在 openwebui 界面的登录框中,输入默认的账号密码(通常平台会在创建实例时提供默认的账号密码信息,您也可以在相关的文档或通知中查找)。输入正确的账号密码后,点击 “登录” 按钮,即可进入 openwebui 的操作界面。
4.2 基本使用方法
提问与获取回答:进入 openwebui 操作界面后,您会看到一个输入框。在输入框中,您可以输入各种自然语言问题或任务描述。例如,您可以输入 “请帮我总结这篇论文的主要观点”,然后附上论文的文本内容;或者输入 “写一段关于人工智能发展趋势的文章” 等。输入完成后,点击 “发送” 按钮或按下回车键,Deepseek-R1 模型将开始处理您的输入,并在界面的输出区域返回回答。
理解回答结果:Deepseek-R1 模型返回的回答可能是一段文字、代码片段、分析结果等,具体形式取决于您的提问。例如,如果您询问一个数学问题,回答可能是详细的解题步骤和答案;如果您要求生成一段代码,回答将是符合要求的代码内容。在阅读回答结果时,要仔细理解模型的输出,确保它满足您的需求。如果回答结果不符合预期,您可以进一步调整提问方式或补充更多的信息,重新向模型提问。
五、高级使用技巧
5.1 命令行调用
进入命令行界面:在蓝耘元生代智算云平台的控制台中,找到 “webterminal” 入口(如果平台提供该功能)。点击进入 webterminal,这是一个命令行操作界面,您可以在其中输入各种命令来与实例进行交互。
加载模型:在 webterminal 中,输入 “ollamarundeepseek-r1” 命令,这将加载默认的 1.5b 模型。如果您需要使用更高规格的模型,如 7b、8b 或 14b 等,可以在命令后输入相应的参数指令进行切换。例如,输入 “ollamarundeepseek-r1 7b” 即可切换到 7b 模型。这种通过命令行调用不同规格模型的方式,适用于对模型性能有特定要求的用户,能够根据具体任务灵活选择合适的模型。
命令行参数解释:在上述命令中,“ollamarundeepseek-r1” 是调用 Deepseek-R1 模型的基本命令,后面跟随的数字(如 1.5b、7b 等)是模型的参数规格。不同的参数规格代表模型的不同版本,这些版本在模型大小、计算复杂度和性能表现上存在差异。参数越大,模型通常能够处理更复杂的任务,但同时也需要更高的算力支持和更长的计算时间。
5.2 使用实用工具
访问实用工具:在算力管理控制台中,找到 “实用工具” 选项卡或入口。这里提供了一系列工具,用于对 Deepseek-R1 模型的运行进行监控和管理。
监控模型运行:使用实用工具中的监控功能,您可以实时查看模型的运行状态,包括 CPU 使用率、GPU 使用率、内存占用等指标。例如,通过监控 CPU 使用率,您可以了解模型在运行过程中对中央处理器的资源消耗情况。如果 CPU 使用率过高,可能意味着模型的计算任务过于繁重,或者当前的算力配置不足,需要考虑调整任务或增加算力。同样,监控 GPU 使用率和内存占用,可以帮助您及时发现模型运行中的性能瓶颈,确保模型高效运行。
管理模型资源:实用工具还提供了对模型资源的管理功能,您可以根据实际需求调整模型的资源分配。例如,如果您发现某个任务在运行过程中占用了过多的内存,导致其他任务无法正常运行,您可以通过实用工具调整该任务的内存分配,优化模型的资源利用效率。
5.3 优化模型性能
调整输入参数:在与 Deepseek-R1 模型交互时,合理调整输入参数可以显著提升模型的性能。例如,在进行文本生成任务时,您可以调整生成文本的长度参数。如果您希望生成一段简短的摘要,将长度参数设置为较小的值;如果需要生成详细的报告,适当增大长度参数。此外,还可以调整生成文本的随机性参数,该参数影响模型生成文本的多样性。将随机性参数设置为较低的值,模型生成的文本会更加保守、准确;设置为较高的值,生成的文本会更加多样化,但也可能增加出现错误或不合理内容的风险。
使用上下文信息:Deepseek-R1 模型能够利用上下文信息更好地理解用户的提问。在提问时,尽量提供完整的上下文信息,有助于模型给出更准确的回答。例如,在询问关于某个项目的问题时,先简要介绍项目的背景、目标和当前进展等信息,然后再提出具体问题。这样模型可以根据这些上下文信息,更全面地分析问题,提供更符合实际情况的答案。
六、关闭实例与成本控制
6.1 关闭实例
当您暂时不需要使用 Deepseek-R1 实例时,为了避免不必要的费用支出,需要及时关闭实例。在实例管理界面中,找到要关闭的实例,点击 “更多” 按钮,在弹出的菜单中选择 “关闭” 选项。系统会提示您确认关闭操作,确认后实例将停止运行。
6.1 成本控制策略
合理规划使用时间:根据自己的实际需求,合理安排使用 Deepseek-R1 实例的时间。避免长时间闲置实例而产生不必要的费用。例如,如果您只是在每天的特定时间段内使用模型进行工作,在其他时间将实例关闭。
优化算力配置:定期评估自己的任务需求,根据实际情况调整算力配置。如果发现当前的算力配置过高,而任务负载较低,可以降低算力配置,选择更经济实惠的方案。反之,如果任务量增加,且当前算力无法满足需求,再适当提升算力配置。通过灵活调整算力配置,实现成本的有效控制。
七、常见问题与解决方法
7.1 连接问题
无法打开 openwebui 界面:
可能原因:网络连接不稳定、浏览器兼容性问题、平台服务器故障等。
解决方法:首先检查自己的网络连接,确保网络正常。可以尝试打开其他网页,确认网络是否畅通。如果网络正常,更换浏览器或使用浏览器的无痕模式再次尝试打开 openwebui 界面,以排除浏览器兼容性问题。如果问题仍然存在,联系蓝耘元生代智算云的客服人员,了解平台服务器是否存在故障,并等待修复。
登录 openwebui 失败:
可能原因:输入的账号密码错误、账号被锁定、平台认证系统故障等。
解决方法:仔细检查输入的账号密码是否正确,注意区分大小写。如果忘记密码,可以点击 “忘记密码” 按钮,按照系统提示进行密码重置。如果账号被锁定,联系平台客服了解解锁方法。如果是平台认证系统故障,等待平台修复,并关注平台的通知信息。
7.2 模型运行问题
模型回答结果不准确:
可能原因:提问方式不清晰、输入的上下文信息不足、模型本身的局限性等。
解决方法:优化提问方式,使用简洁明了的语言表达问题。同时,补充更多的上下文信息,帮助模型更好地理解问题。如果问题仍然存在,考虑到模型可能存在一定的局限性,尝试从不同角度重新提问,或者结合其他工具和方法来解决问题。
模型运行缓慢:
可能原因:算力配置不足、当前平台负载过高、模型参数设置不合理等。
解决方法:如果是算力配置不足,可以在实例管理界面中调整算力配置,增加 GPU 数量或选择更高性能的 GPU 型号。如果是平台负载过高,可以等待一段时间后再次尝试,或者联系平台客服了解平台的负载情况和预计恢复时间。如果是模型参数设置不合理,参考模型的使用文档,调整相关参数,优化模型的运行效率。
八、OpenAI兼容接口
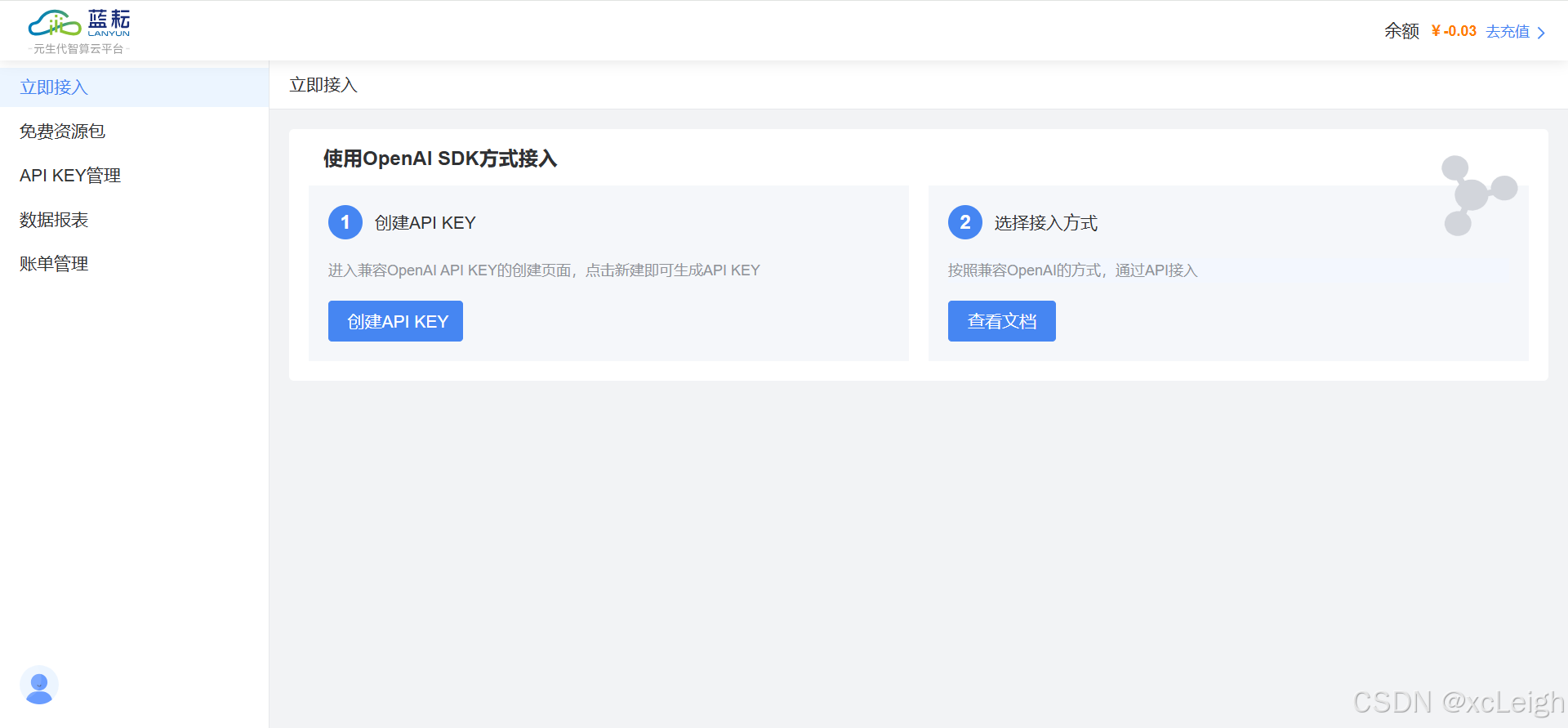
直接使用 OpenAI 官方提供的 SDK 来调用大模型对话接口。您仅需要将 base_url 和 api_key 替换成相关配置,不需要对应用做额外修改,即可无缝将您的应用切换到相应的大模型。
base_url:https://maas-api.lanyun.net/v1
api_key:如需获取请参考获取API KEY
接口完整路径:https://maas-api.lanyun.net/v1/chat/completions
8.1 python调用
创建一个python文件命名为ark_example.py,将下面示例代码拷贝进文件。并替换密钥为您的API KEY。替换content中的<你是谁>为您想要的提问内容。点击运行,稍等您可以在终端窗口中看到模型调用的返回结果。这样您就完成了您的首次型服务调用。
from openai import OpenAI
# 构造 client
client = OpenAI(
api_key="sk-xxxxxxxxxxx", # APIKey
base_url="https://maas-api.lanyun.net/v1",
)
# 流式
stream = True
# 请求
chat_completion = client.chat.completions.create(
model="/maas/deepseek-ai/DeepSeek-R1",
messages=[
{
"role": "user",
"content": "你是谁",
}
],
stream=stream,
)
if stream:
for chunk in chat_completion:
# 打印思维链内容
if hasattr(chunk.choices[0].delta, 'reasoning_content'):
print(f"{chunk.choices[0].delta.reasoning_content}", end="")
# 打印模型最终返回的content
if hasattr(chunk.choices[0].delta, 'content'):
if chunk.choices[0].delta.content != None and len(chunk.choices[0].delta.content) != 0:
print(chunk.choices[0].delta.content, end="")
else:
result = chat_completion.choices[0].message.content
8.1 NodeJS调用
const OpenAI = require("openai");
// 构造 client
const client = new OpenAI({
apiKey: "sk-xxxxxxxxxxx", // APIKey
baseURL: "https://maas-api.lanyun.net/v1/chat/completions",
});
// 定义一个异步函数来处理请求
async function getCompletion() {
try {
const completion = await client.chat.completions.create({
model: '/maas/deepseek-ai/DeepSeek-R1',
messages: [{ role: 'user', content: '你好' }],
stream: true,
});
// 处理流式响应
for await (const chunk of completion) {
if (chunk.choices) {
// 打印思维链内容
console.log("reasoning_content:", chunk.choices[0]?.delta?.reasoning_content);
// 打印模型最终返回的content
console.log("content", chunk.choices[0]?.delta?.content);
}
}
} catch (error) {
console.error("Error occurred:", error);
}
}
// 调用异步函数
getCompletion();
8.1 cURL
您可以通过 HTTP 方式直接调用模型服务。在终端窗口中,拷贝下面命令,并替换密钥为您的API KEY。替换content中的<你好>为您想要的提问内容。稍等您可以在终端窗口中看到模型调用的返回结果。这样您就完成了您的首次型服务调用
curl https://maas-api.lanyun.net/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-xxxxxxxxxxx" \
-d '{
"model": "/maas/deepseek-ai/DeepSeek-R1",
"messages": [
{
"role": "user",
"content": "你好"
}
],
"stream": true
}'
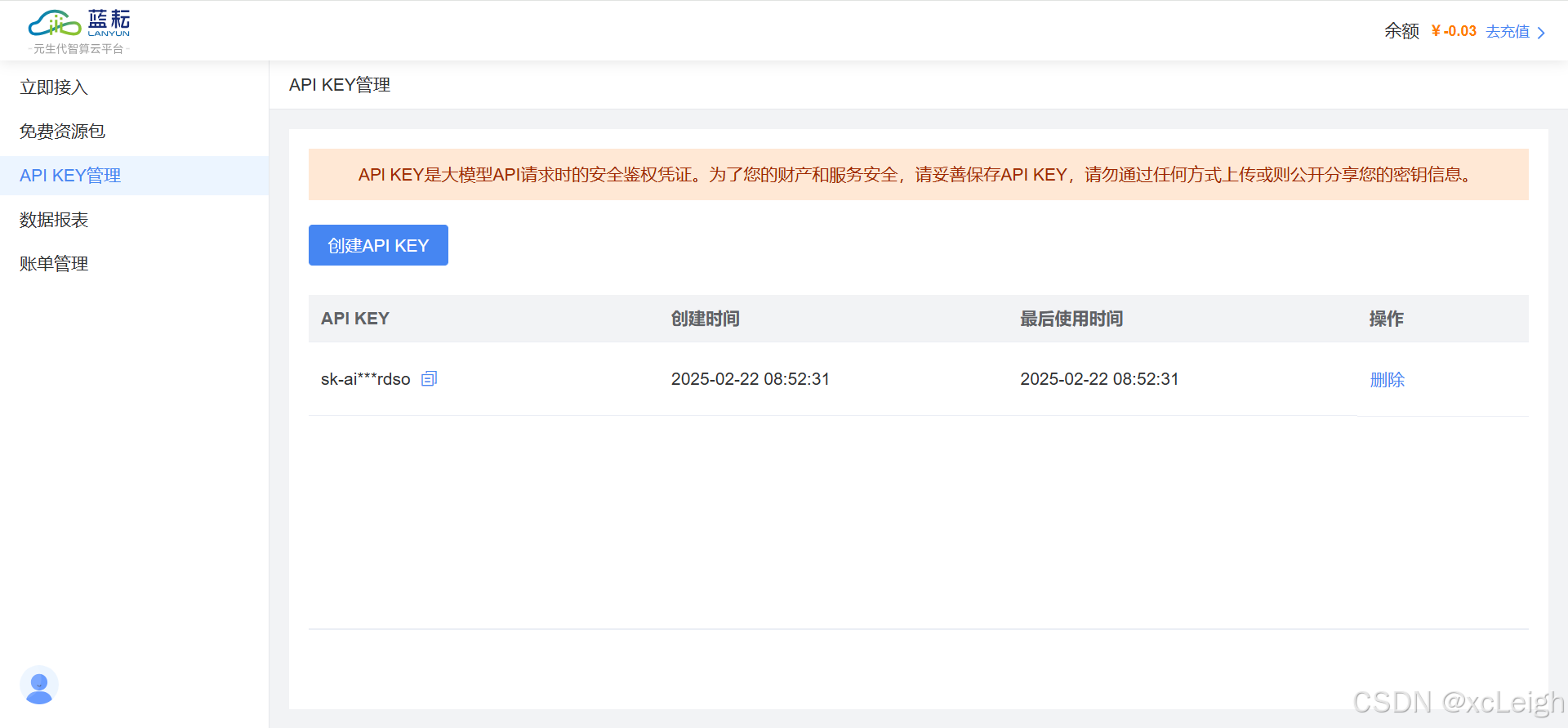
8.1获取 API Key
-
1.进入 API平台 > 立即接入 管理,单击创建 API KEY。
-
2.单击创建 API Key 按钮。
-
3.在弹出框的名称文本框中确认/更改 API Key 名称,单击创建。
说明: 请妥善保存好API Key,强烈建议您不要将其直接写入到调用模型的代码中 -
4.创建完成后,进入 API KEY 管理,进行新增、查看、删除操作。
九、总结
通过本教程,我们详细介绍了蓝耘元生代智算云的 Deepseek-R1 满血版的使用方法,从准备工作、创建实例、连接与使用,到高级技巧、成本控制以及常见问题解决等方面,为您提供了全面的指导。希望您能够通过本教程,熟练掌握 Deepseek-R1 满血版的使用,充分发挥其强大的性能,在人工智能应用的道路上取得更好的成果。在使用过程中,如果您遇到任何问题或有新的需求,随时可以查阅相关文档或联系蓝耘元生代智算云的技术支持团队,获取帮助和指导。
如果你对文章中的某个部分,比如某个概念的解释、代码示例等,还有更具体的要求,欢迎告诉我,我会进一步完善。
今天就介绍到这里了,更多功能快去尝试吧……
结束语
亲爱的朋友,无论前路如何漫长与崎岖,都请怀揣梦想的火种,因为在生活的广袤星空中,总有一颗属于你的璀璨星辰在熠熠生辉,静候你抵达。
愿你在这纷繁世间,能时常收获微小而确定的幸福,如春日微风轻拂面庞,所有的疲惫与烦恼都能被温柔以待,内心永远充盈着安宁与慰藉。
至此,文章已至尾声,而您的故事仍在续写,不知您对文中所叙有何独特见解?期待您在心中与我对话,开启思想的新交流。
🚍 蓝耘元生代智算云平台:https://cloud.lanyun.net//#/registerPage?promoterCode=0131


① 🉑提供云服务部署(有自己的阿里云);
② 🉑提供前端、后端、应用程序、H5、小程序、公众号等相关业务;
如🈶合作请联系我,期待您的联系。
亲,码字不易,动动小手,欢迎 点赞 ➕ 收藏,如 🈶 问题请留言(评论),博主看见后一定及时给您答复,💌💌💌




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











