










一、SD教程说明
众所周知StableDiffusion这款开源软件对电脑硬件要求非常高,因此我们普通人想体验如今最火的AI绘画软件的话,用这种谷歌colab的方式是最好的方式了,接下来跟着我一块来体验一下如何使用吧。
二、准备前提
1、一个谷歌账号
2、github上一个开源项目
三、教程说明
本教程使用谷歌colab来云端部署的,就是不需要任何成本来部署实现SD。colab给的免费GPU算力,在24小时之内只有最多12小时的使用时长,如果出现无法分配GPU算力,可能需要等待下一个24小时才可以使用,这也是这种方法的一个缺点。
详细教程请移步我的博客:
SD/StableDiffusion模型,ai绘画部署教程,谷歌云端零成本部署,支持中文![]() https://www.idcyli.com/226.html
https://www.idcyli.com/226.html
四、开始搭建
1、第一步,下载ipynb脚本文件
链接:https://pan.baidu.com/s/1OIjGIL6NPxpwTJ6SW7q6dw?pwd=cf9u
提取码:cf9u
2、第二步,上传一键脚本文件到谷歌云盘
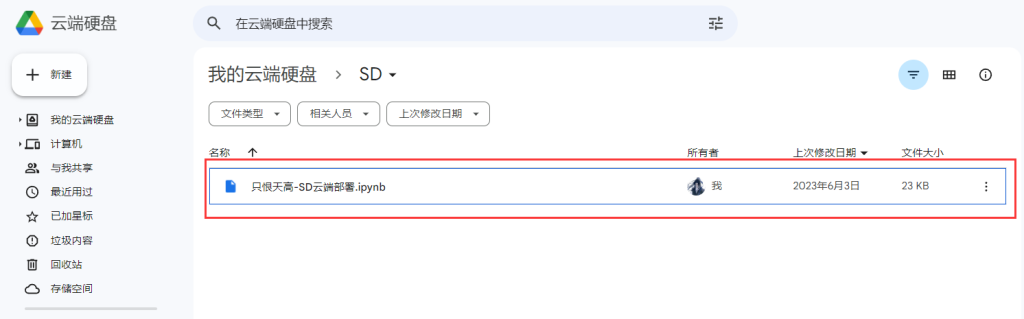
3、选择该.ipynb文件--右键--打开方式--关联更多应用

4、输入框搜索Colaboratory找到该应用,安装

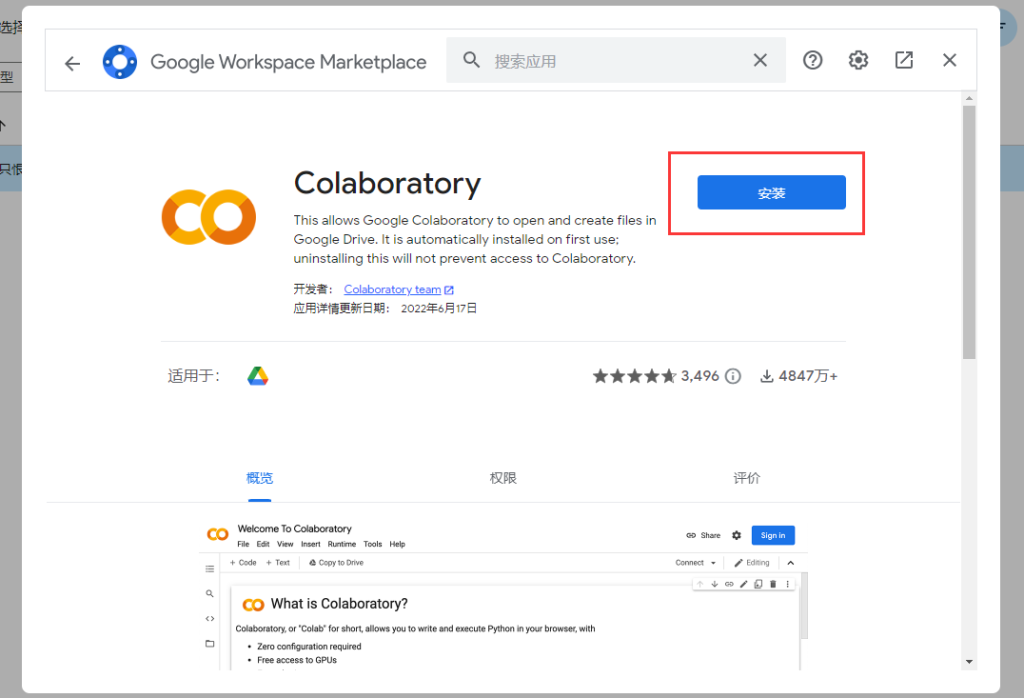

5、安装过程中,选择您已经登录的Google账户

6、用安装好的Colaboratory打开.ipynb文件
文件--右键--打开方式--Colaboratory

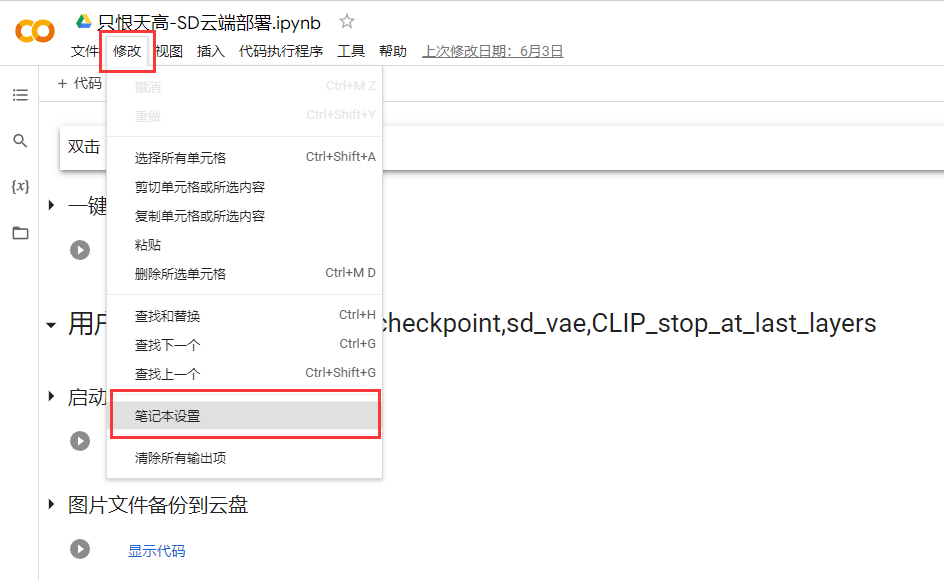
7、在使用Colaboratory打开的界面选中修改-笔记本设置-确认默认设置

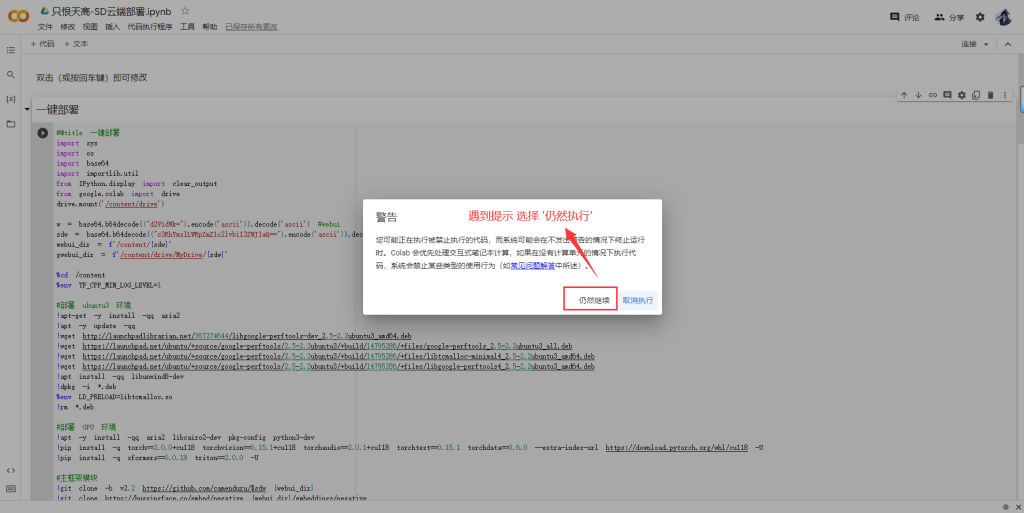
8、一键部署

遇到访问权限询问弹窗都选择允许即可


9、耐心等待云端部署完成,大概15分左右。


前提得有免费的GPU算力,如果提示执行失败,等几十分钟或者几个小时重新一键部署。

10、成功部署后打开的页面

中文汉化:
打开settings--User interface
填写下面代码:
sd_model_checkpoint,sd_vae,CLIP_stop_at_last_layers
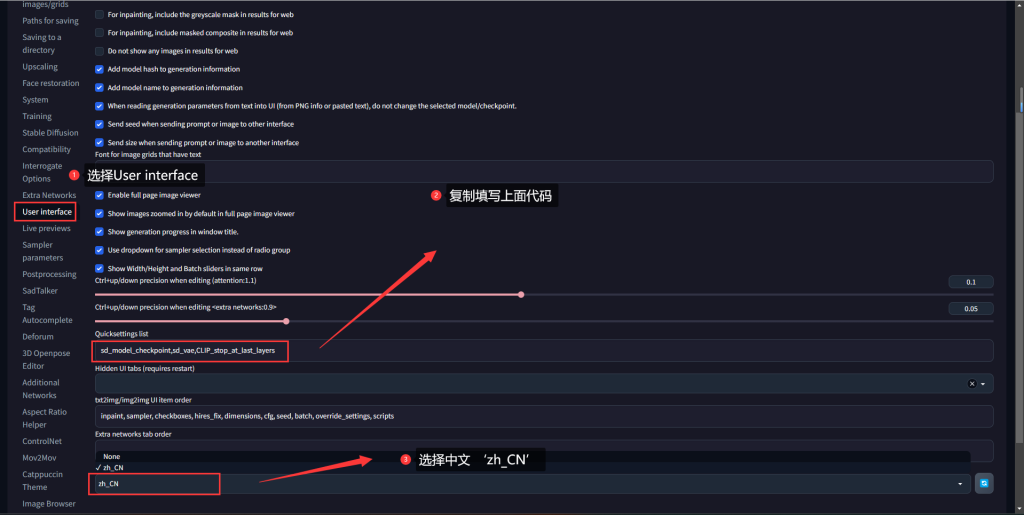
保存-并重启web-ui

11、打开新链接即可出现中文界面

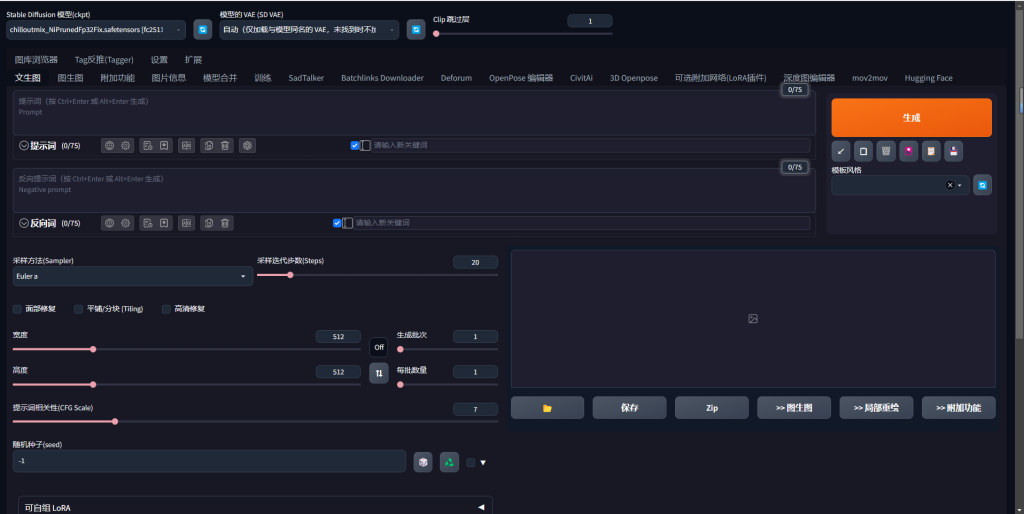
其他可能遇见问题
打开提示没有改接口运行,就打开其他的项目启动链接。

12、简单使用

简单示例:
关键词,提示词:
水上少女
{masterpiece},{best quality},{1girl,{{loli},black hair,blue eyes,very long hair,hair flower,school uniform,happy}},Amazing,beautiful detailed eyes,finely detail,Depth of field,extremely detailed CG,original,outdoors,beautiful detailed hand,beautiful detailed fingers,wet through,{knee under water},standing,{beautiful detailed water,beautiful detailed sky,fluttered detailed splashs},by Paul Hedley,colorful,hdr,{{colorful refraction}},{{cinematic lighting}},sd绘画输出结果

关键词,提示词:
新娘
1girl, dress, solo, realistic, veil, lips, see-through, black hair, white dress, long hair, own hands together, black eyes, wedding dresssd绘画输出结果

五、其他相关项目介绍
最新AI创作系统
程序核心功能:
程序已支持ChatGPT3.5/4.0提问、AI绘画、Midjourney绘画(全自定义调参)、Midjourney以图生图、Dall-E2绘画、思维导图生成、知识库(可自定义训练)、AI绘画广场、邀请+代理分销模式、用户每日签到功能、会话记录保存、微信公众号+邮箱+手机号注册登录、后续其他免费版本功能更新...
系统介绍搭建部署教程文档
最新ChatGPT程序源码+AI系统+详细图文搭建教程/支持GPT4/AI绘画/H5端/完整Prompt知识库![]() https://www.idcyli.com/33.html
https://www.idcyli.com/33.html
系统功能模块演示



















 2860
2860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











