







如果您遇到过PASCAL Visual Object Classes (VOC)和MS Common Objects in Context (COCO)挑战,或者涉及过信息检索和重识别(ReID)的项目,那么您可能会非常熟悉称为mAP的度量。
mAP或有时简称为AP是一种流行的度量标准,用于衡量信息检索和对象检测任务的模型的性能。
本文希望计算出目标检测和信息检索任务的mAP。本文还将探讨为什么mAP是信息检索和目标检测任务的合适且常用的度量。
大纲
- 基础知识
- 信息检索中的AP和mAP
- 目标检测中的AP和mAP
1.基础知识
精度和查全率是判断分类模型性能的两个常用指标。要理解mAP,我们首先需要回顾精度和查全率。
更“著名”的“精度”和“查全率”
T
P
=
T
r
u
e
P
o
s
i
t
i
v
e
(
模
型
预
测
为
正
样
本
,
实
际
为
正
样
本
)
T
N
=
T
r
u
e
N
e
g
a
t
i
v
e
(
模
型
预
测
为
负
样
本
,
实
际
为
负
样
本
)
F
P
=
F
a
l
s
e
P
o
s
i
t
i
v
e
(
模
型
预
测
为
正
样
本
,
实
际
为
负
样
本
)
F
N
=
F
a
l
s
e
N
e
g
a
t
i
v
e
(
模
型
将
预
测
为
负
样
本
,
实
际
为
正
样
本
)
TP=True Positive(模型预测为正样本,实际为正样本)\\ TN=True Negative(模型预测为负样本,实际为负样本)\\ FP=False Positive(模型预测为正样本,实际为负样本)\\ FN=False Negative(模型将预测为负样本,实际为正样本) \\
TP=TruePositive(模型预测为正样本,实际为正样本)TN=TrueNegative(模型预测为负样本,实际为负样本)FP=FalsePositive(模型预测为正样本,实际为负样本)FN=FalseNegative(模型将预测为负样本,实际为正样本)
在统计学和数据科学领域,给定类别的分类精度,即正预测值,是真阳性(TP)与总预测阳性数之比。公式如下所示:

同样,分类中给定类别的召回率,即真阳性率或灵敏度,定义为TP与数据集中所有阳性之和的比值。公式如下所示:

对于一个给定的分类模型,它的精确度和查全率之间存在权衡。如果我们使用神经网络,这种权衡可以通过模型的最后一层softmax阈值进行调整。
为了提高精确度,我们需要减少FP的数量,这样做会减少我们的召回量。同样地,减少FN的数量会增加我们的召回率并降低精确度。在信息检索和对象检测的情况下,我们通常希望我们的精度较高(我们的预测阳性为TP)。

精确度和召回率通常与准确性、f1评分、ROC(receiver operating characteristics)等指标一起使用。
不那么“出名”的“精度”和“查全率”
然而,当涉及到信息检索时,定义是不同的。

默认情况下,精度将考虑所有检索到的文档,但是,它也可以在给定检索到的文档数量(通常称为cut-off rank)下进行评估,在这种情况下,只通过考虑最上面的查询来评估模型。这种测量称为k点的精度或P@K。
让我们用一个例子来更好地理解这个公式。
定义一个典型的信息检索任务
信息检索中的一个典型任务是用户向数据库提供查询,并检索与查询非常相似的信息。现在让我们用一个带有三个真值的例子来执行精度计算。
我们将定义以下变量:
- Q为用户查询
- G为数据库中标记数据的集合
- D(i,j)是一个分数函数,表示对象i与j的相似程度
- G’为G根据分数函数d(,)排序后的有序集
- k是G’的索引
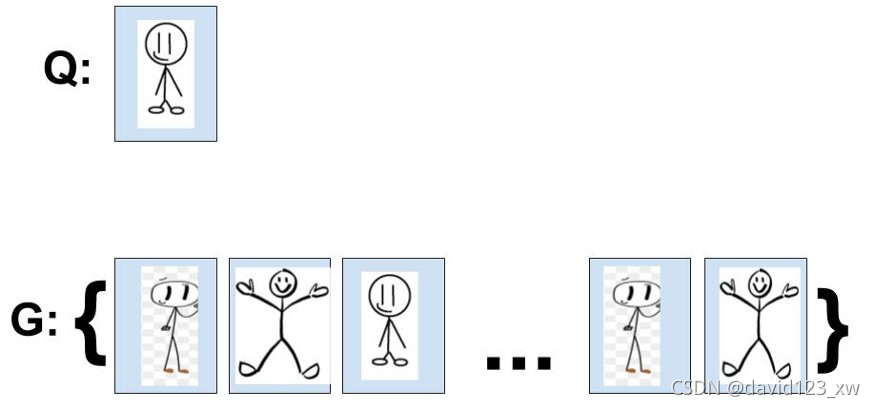
在计算出Q与G中的每个元素的d(,)后,我们可以根据d(,)对G进行排序,得到G '。假设模型返回如下G ':

利用上面的Precision公式,我们得到:
P@1 = 1/1 = 1
P@2 = 1/2 = 0.5
P@3 = 1/3 = 0.33
P@4 = 2/4 = 0.5
P@5 = 3/5 = 0.6
P@n = 3/n
类似地,Wiki定义的召回公式如下:
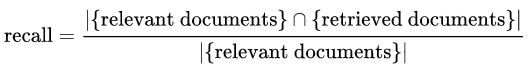
在这种情况下,查全率本身通常不用作指标。
2.信息检索中的AP和mAP
熟悉precision@k之后,我们可以继续计算平均精度。这将使我们更好地衡量我们的模型对查询结果G '进行排序的能力。

其中GTP为ground truth positive的总数,n为您感兴趣的文档总数,P@k为precision@k, rel@k为相关函数。相关性函数是一个指示函数,如果rank k的文档是相关的,则该函数等于1,否则等于0。
回想一下精度的定义,我们现在将使用它来计算G '中的每个文档的AP。使用上面的同一个例子:

这个查询的总AP是0.7。需要注意的是,由于我们知道只有三个GTP, AP@5将等于整个AP。
对于另一个查询Q,如果返回的G '是这样排序的,我们可以得到一个完美的AP为1:
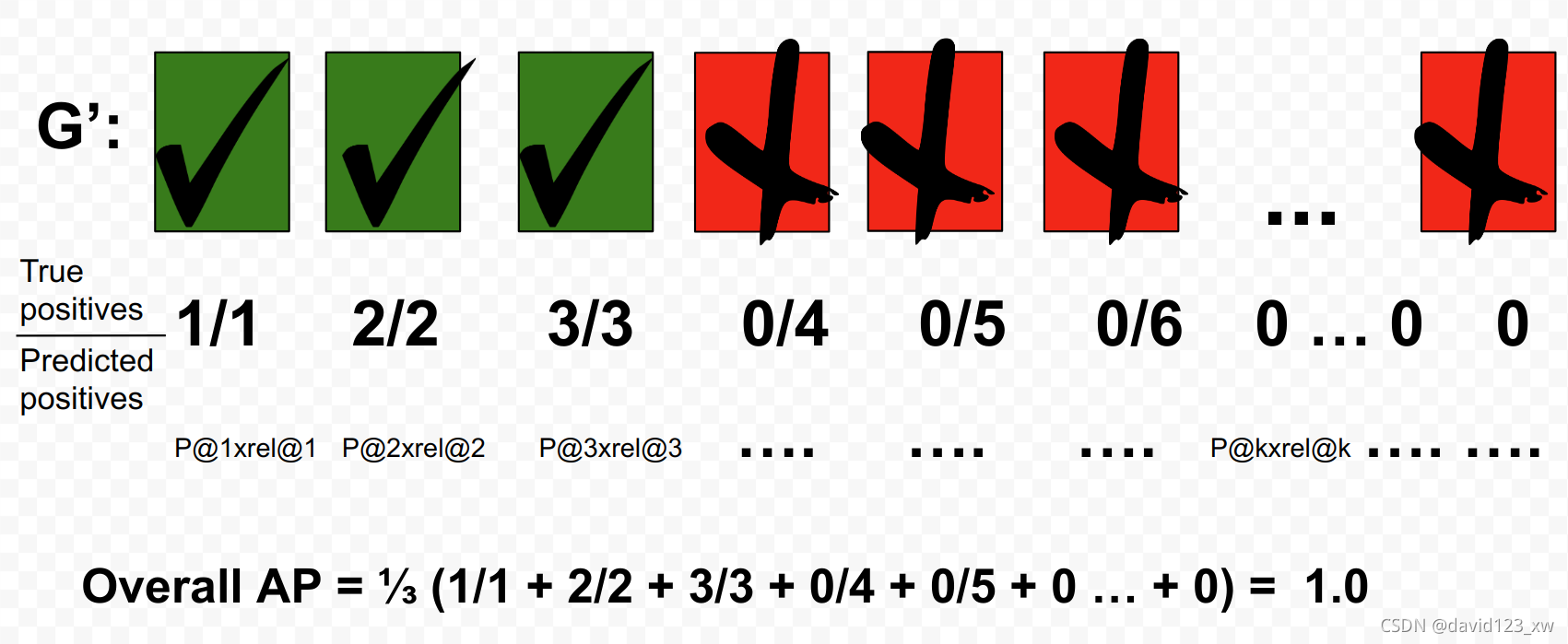
在这种情况下,AP所做的是惩罚那些不能以TPs为首的G '排序的模型。它提供了一个数字,可以根据评分函数d(,)量化排序的优劣。通过将精度的总和除以总GTP而不是除以G的长度,可以为只有几个GTP的查询提供更好的表示。
计算mAP
对于每个查询Q,我们可以计算一个相应的AP。用户可以对这个标记的数据库进行任意多的查询。mAP只是使用所进行的所有查询的平均值。

3. 目标检测中的AP和mAP
计算AP(传统IoU = 0.5)
a. IOU交并比
为了计算用于目标检测的AP,我们首先需要了解IoU。IoU由预测边界框与真实边界框的交面积与并面积之比给出。
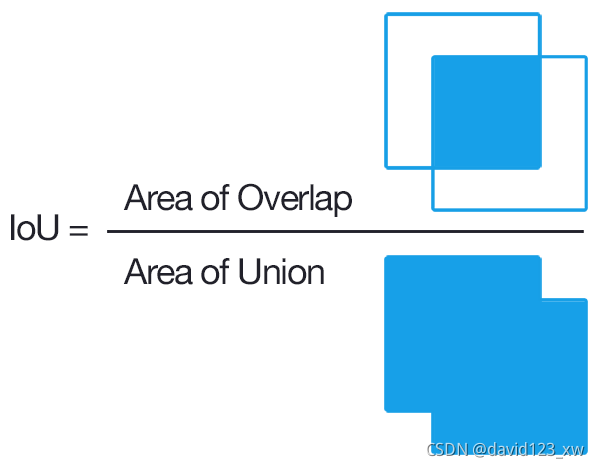
IoU将用于确定预测边界框(BB)是TP、FP还是FN。由于假设每张图像中都有一个对象,所以TN不进行评估。让我们考虑以下图像:

这个图像包含了一个人和一匹马,以及它们相应的真实边界框。我们先不去管那匹马。我们在这张图像上运行我们的目标检测模型,并接收到一个预测的人的边界框。传统上,如果IoU为> 0.5,我们将预测定义为TP。可能出现的情况如下:
- True Positive (IoU > 0.5)

IoU为预测BB(黄色)和GT BB(蓝色)> 0.5,分类正确 - False Positive
BB被认为是FP有两种可能的情况:
a. IoU < 0.5
b. 重复的BB

一个预测的BB(黄色)将被认为是FP的不同场景。 - False Negative
当我们的目标检测模型未检测到目标时,则认为是假阴性。两种可能的情况如下:
a. 当根本没有检测到对象的时候

b. 当预测BB的IoU > 0.5但分类错误时,预测BB为FN

FN BB作为预测类是马而不是人.
精度/召回率曲线(PR曲线)
在正式定义了TP、FP和FN之后,我们现在可以在测试集计算对给定类的检测的精度和召回率。每个BB都有它的置信度,通常由它的softmax层给出,并用于对输出进行排序。请注意,这与信息检索案例非常相似,只是我们没有使用相似度函数d(,)来提供排名,而是使用模型预测的BB的置信度。
计算AP
在绘制PR曲线之前,我们首先需要知道插值精度。插值精度p_interp是在每个召回水平r上通过取该r的最大测量精度来计算的。公式如下:

其中p® ~是召回量r ~时的测量精度。
P
i
n
t
e
r
p
(
r
)
P_{interp}(r)
Pinterp(r)是超过r的recall中对应最大的precision值,例如
P
i
n
t
e
r
p
(
0.6
)
P_{interp}(0.6)
Pinterp(0.6)就是大于0.6的所有recall中对应的最大的precision的值。
对PR曲线进行插值的目的是减少检测排序的微小变化所引起的“摆动”的影响。
现在,我们可以开始绘制PR曲线了。考虑一个带有3TP和4FP的person类的示例。我们计算相应的精度,查全率,和插值精度。

以3TP和4FP为例绘制PR曲线的计算表。行对应于BB,人分类按其各自的softmax置信度排序。

然后通过取PR曲线下的面积来计算AP。这是通过将召回平均分割为11个部分来实现的:{0,0.1,0.2,…,0.9,1}。我们得到如下结果:
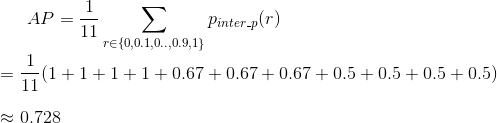
计算mAP
用于对象检测的mAP是所有类计算出的AP的平均值。同样需要注意的是,有些论文可以互换使用AP和mAP
其他计算AP的方法
COCO提供了六种新的AP计算方法,其中三种方法是在不同的 IoU 下对 BB 进行阈值处理:
- AP:在 IoU= 0.50: 0.05: 0.95的AP(主要指标)
- AP@IOU=0.50(如上所述的传统计算方法)
- AP@IOU=0.75(BB的IOU要大于0.75)
对于主要指标的AP, 0.5:0.05:0.95意味着从IoU = 0.5开始,步长为0.05,我们增加到IoU = 0.95。这将导致计算AP阈值在10个不同的IOU。平均值是为了提供一个单一的数字,奖励那些更擅长定位的探测器。
其余三种方法是跨尺度计算AP:
- A P s m a l l AP^{small} APsmall:小对象AP,面积小于32² px
- A P m e d i u m AP^{medium} APmedium:中等对象AP,面积介于32² px与96² px之间
-
A
P
s
m
a
l
l
AP^{small}
APsmall:大对象AP,面积大于96² px
这将允许更好地区分模型,因为一些数据集比其他数据集有更多的小对象。
参考目录
https://towardsdatascience.com/breaking-down-mean-average-precision-map-ae462f623a52














 139
139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









