










1.摘要
包括计算摄影(闪光反射)和增强现实效果(虚拟化身)在内的广泛的现实世界应用依赖于准确跟踪眼睛内的虹膜。由于有限的计算资源、可变的光照条件以及遮挡物(例如头发或人眯眼)的存在,在移动设备上解决此问题是一项具有挑战性的任务。虹膜跟踪也可用于确定相机到用户的公制距离。这可以改进各种用例,从虚拟试戴合适尺寸的眼镜和帽子到根据观看者的距离采用字体大小的辅助功能。通常,使用复杂的专用硬件来计算公制距离,从而限制了可以应用该解决方案的设备范围。
MediaPipe 虹膜是一种用于精确虹膜估计的 ML 解决方案,能够使用单个 RGB 摄像头实时跟踪涉及虹膜、瞳孔和眼睛轮廓的地标,无需专门的硬件。通过使用虹膜地标,该解决方案还能够以小于 10% 的相对误差确定对象与相机之间的公制距离。请注意,虹膜跟踪不会推断人们正在查看的位置,也不会提供任何形式的身份识别。借助 MediaPipe 框架的跨平台功能,MediaPipe 虹膜可以在大多数现代手机、台式机/笔记本电脑甚至网络上运行。
2.ML管道
管道的第一步利用 MediaPipe面部网格,它生成近似面部几何体的网格。从这个网格中,我们获取原始图像中的眼睛区域,以用于随后的虹膜跟踪步骤。
管道被实现为一个 MediaPipe 图,它使用来自面部地标模块的面部地标子图以及来自虹膜地标模块的虹膜地标子图,并使用专用的虹膜和深度渲染器子图进行渲染。人脸地标子图内部使用人脸检测模块中的人脸检测子图。
管道的输出是一组 478 个 3D 地标,包括来自 MediaPipe 面部网格 的 468 个面部地标,眼睛周围的标志进一步细化,最后附加了 10 个额外的虹膜地标(每只眼睛 5 个)。
3.模型
- 人脸检测模型:人脸检测器与 MediaPipe 人脸检测中使用的 BlazeFace 模型相同。
- 人脸地标模型:人脸地标模型与 MediaPipe 面部网格中的相同。
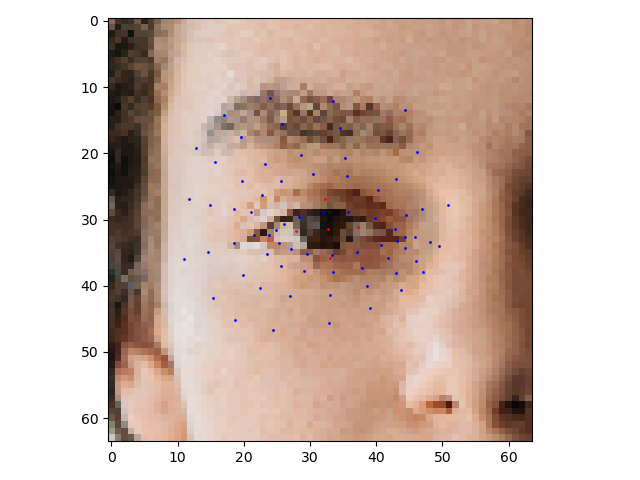
- 虹膜地标模型:虹膜模型获取眼睛区域的图像块并估计眼睛地标(沿眼睑)和虹膜地标(沿虹膜轮廓)。

眼 睛 地 标 ( 红 色 ) 和 虹 膜 地 标 ( 绿 色 ) 。 眼睛地标(红色)和虹膜地标(绿色)。 眼睛地标(红色)和虹膜地标(绿色)。
4.根据虹膜测量深度
MediaPipe 虹膜能够以小于 10% 的误差确定拍摄对象到相机的公制距离,而无需任何专门的硬件。这是通过依赖这样一个事实来完成的:人眼的水平虹膜直径在广泛的人群中保持大致恒定在 11.7±0.5 毫米,以及一些简单的几何参数。有关更多详细信息,请参阅Google AI 博客文章。
5.解决方案
官方没有虹膜检测的Python代码,我在Github上找到了TensorFlow以及PyTorch的代码:
链接:https://pan.baidu.com/s/13-Kh_2pGUZGn7Fz-Bifw6Q
提取码:123a
5.1目录结构

5.1TensorFlow上实现
import numpy as np
import tensorflow as tf
import cv2
import matplotlib.pyplot as plt
def centerCropSquare(img, center, side=None, scaleWRTHeight=None):
a = side is None
b = scaleWRTHeight is None
assert (not a and b) or (a and not b) # Python没有实现异或操作
half = 0
if side is None:
half = int(img.shape[0] * scaleWRTHeight / 2)
else:
half = int(side / 2)
return img[(center[0] - half):(center[0] + half), (center[1] - half):(center[1] + half), :]
# Load the TFLite model and allocate tensors.
interpreter = tf.lite.Interpreter(model_path="iris_landmark.tflite")
interpreter.allocate_tensors()
# Get input and output tensors.
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# Test the model on image
img = cv2.imread("test.jpg")
centerRight = [485, 332]
centerLeft = [479, 638]
img = centerCropSquare(img, centerRight,
side=400) # 400 is 1200 (image size) * 64/192, as the detector takes a 64x64 box inside the 192 image
# img = np.fliplr(img) # the detector is trained on the left eye only, hence the flip
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (64, 64))
input_data = np.expand_dims(img.astype(np.float32) / 127.5 - 1.0, axis=0)
# input_data = np.expand_dims(img.astype(np.float32)/255.0, axis=0)
input_shape = input_details[0]['shape']
interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()
# The function `get_tensor()` returns a copy of the tensor data.
# Use `tensor()` in order to get a pointer to the tensor.
output_data_0 = interpreter.get_tensor(output_details[0]['index'])
# indices = output_data[:, 0:2] * 64.0
eyes = output_data_0
print(eyes.shape)
iris = interpreter.get_tensor(output_details[1]["index"])
print(iris.shape)
# print(indices)
plt.imshow(img, zorder=1)
x, y = eyes[0, ::3], eyes[0, 1::3]
plt.scatter(x, y, zorder=2, s=1.0, c="b")
x, y = iris[0, ::3], iris[0, 1::3]
plt.scatter(x, y, zorder=2, s=1.0, c="r")
plt.show()
5.2PyTorch上实现
import torch
from irislandmarks import IrisLandmarks
import matplotlib.pyplot as plt
import cv2
def centerCropSquare(img, center, side=None, scaleWRTHeight=None):
a = side is None
b = scaleWRTHeight is None
assert (not a and b) or (a and not b) # Python没有实现异或操作
half = 0
if side is None:
half = int(img.shape[0] * scaleWRTHeight / 2)
else:
half = int(side / 2)
return img[(center[0] - half):(center[0] + half), (center[1] - half):(center[1] + half), :]
print("PyTorch version:", torch.__version__)
print("CUDA version:", torch.version.cuda)
print("cuDNN version:", torch.backends.cudnn.version())
gpu = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = IrisLandmarks().to(gpu)
net.load_weights("irislandmarks.pth")
img = cv2.imread("test.jpg")
centerRight = [485, 332]
centerLeft = [479, 638]
img = centerCropSquare(img, centerRight,
side=400) # 400 is 1200 (image size) * 64/192, as the detector takes a 64x64 box inside the 192 image
img = img[..., ::-1]
plt.imshow(img)
plt.show()
# img = np.fliplr(img) # the detector is trained on the left eye only, hence the flip
img = cv2.resize(img, (64, 64))
eye_gpu, iris_gpu = net.predict_on_image(img)
eye = eye_gpu.cpu().numpy()
iris = iris_gpu.cpu().numpy()
print(eye.shape)
print(iris.shape)
# (1, 71, 3)
# (1, 5, 3)
plt.imshow(img, zorder=1)
x, y = eye[0, :, 0], eye[0, :, 1]
plt.scatter(x, y, zorder=2, s=1.0, c='b')
x, y = iris[0, :, 0], iris[0, :, 1]
plt.scatter(x, y, zorder=2, s=1.0, c='r')
plt.show()
# torch.onnx.export(
# net,
# (torch.randn(1,3,64,64, device='cuda'), ),
# "irislandmarks.onnx",
# input_names=("image", ),
# output_names=("preds", "conf"),
# opset_version=9
# )
参考目录
https://github.com/cedriclmenard/irislandmarks.pytorch
https://google.github.io/mediapipe/solutions/iris















 1059
1059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









