







有许多不同的卷积神经网络 (CNN) 模型用于图像分类(VGG、ResNet、DenseNet、MobileNet 等)。它们都提供不同的精度。
与包含在集成网络中的任何单个模型的准确性相比,多个 CNN 模型的集成可以显着提高我们预测的准确性。 如果我们有三种不同的图像分类模型,它们分别提供例如 81%、83% 和 85% 的准确率,那么这三个模型的集成可以提供例如 87% 的准确率,这是一个相当不错的改进。

在本教程中,我们将使用 PyTorch 在 TinyImageNet 数据集上训练三个图像分类模型(DenseNet161、ResNet152 和 VGG19)。然后我们将他们联合成一个整体。 TinyImageNet 由 200 个类组成,训练部分包含 100,000 张图像,验证部分包含 10,000 张图像,测试部分包含 10,000 张图像。所有图像的大小为 64×64。
1.导入相关库
在 Jupyter Notebook 中创建一个新笔记本。首先,我们需要导入必要的模块并检查 GPU 可用性:
import os
import numpy as np
import pandas as pd
from PIL import Image
import matplotlib.pyplot as plt
from tqdm import tqdm
import copy
from sklearn.preprocessing import LabelEncoder
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, models
if torch.cuda.is_available():
print('CUDA is available. Working on GPU')
DEVICE = torch.device('cuda')
else:
print('CUDA is not available. Working on CPU')
DEVICE = torch.device('cpu')
# CUDA is available. Working on GPU
2.下载 TinyImageNet 数据集
下载并解压数据集:
!wget -O tiny-imagenet-200.zip http://cs231n.stanford.edu/tiny-imagenet-200.zip
!unzip tiny-imagenet-200.zip
3.图像和标签
数据集包含文件夹 val/、train/ 和 test/。对于每个文件夹,我们将创建带有文件(图像)路径的列表和带有标签的列表:
DIR_MAIN = 'tiny-imagenet-200/'
DIR_TRAIN = DIR_MAIN + 'train/'
DIR_VAL = DIR_MAIN + 'val/'
DIR_TEST = DIR_MAIN + 'test/'
# Number of labels - 200
labels = os.listdir(DIR_TRAIN)
# Initialize labels encoder
encoder_labels = LabelEncoder()
encoder_labels.fit(labels)
# Create lists of files and labels for training (100'000 items)
files_train = []
labels_train = []
for label in labels:
for filename in os.listdir(DIR_TRAIN + label + '/images/'):
files_train.append(DIR_TRAIN + label + '/images/' + filename)
labels_train.append(label)
# Create lists of files and labels for validation (10'000 items)
files_val = []
labels_val = []
for filename in os.listdir(DIR_VAL + 'images/'):
files_val.append(DIR_VAL + 'images/' + filename)
val_df = pd.read_csv(DIR_VAL + 'val_annotations.txt', sep='\t', names=["File", "Label", "X1", "Y1", "X2", "Y2"], usecols=["File", "Label"])
for f in files_val:
l = val_df.loc[val_df['File'] == f[len(DIR_VAL + 'images/'):]]['Label'].values[0]
labels_val.append(l)
# List of files for testing (10'000 items)
files_test = []
for filename in os.listdir(DIR_TEST + 'images/'):
files_test.append(DIR_TEST + 'images/' + filename)
files_test = sorted(files_test)
print("The first five files from the list of train images:", files_train[:5])
print("\nThe first five labels from the list of train labels:", labels_train[:5])
print("\nThe first five files from the list of validation images:", files_val[:5])
print("\nThe first five labels from the list of validation labels:", labels_val[:5])
print("\nThe first five files from the list of test images:", files_test[:5])
查看输出以更好地理解创建列表的结构:
The first five files from the list of train images: ['tiny-imagenet-200/train/n03970156/images/n03970156_391.JPEG', 'tiny-imagenet-200/train/n03970156/images/n03970156_35.JPEG', 'tiny-imagenet-200/train/n03970156/images/n03970156_405.JPEG', 'tiny-imagenet-200/train/n03970156/images/n03970156_92.JPEG', 'tiny-imagenet-200/train/n03970156/images/n03970156_162.JPEG']
The first five labels from the list of train labels: ['n03970156', 'n03970156', 'n03970156', 'n03970156', 'n03970156']
The first five files from the list of validation images: ['tiny-imagenet-200/val/images/val_9055.JPEG', 'tiny-imagenet-200/val/images/val_682.JPEG', 'tiny-imagenet-200/val/images/val_2456.JPEG', 'tiny-imagenet-200/val/images/val_7116.JPEG', 'tiny-imagenet-200/val/images/val_2825.JPEG']
The first five labels from the list of validation labels: ['n03584254', 'n04008634', 'n02206856', 'n04532670', 'n01770393']
The first five files from the list of test images: ['tiny-imagenet-200/test/images/test_0.JPEG', 'tiny-imagenet-200/test/images/test_1.JPEG', 'tiny-imagenet-200/test/images/test_10.JPEG', 'tiny-imagenet-200/test/images/test_100.JPEG', 'tiny-imagenet-200/test/images/test_1000.JPEG']
可以看到,类的名称,或者说标签,并不是常用的“table”、“bicycle”、“ariplane”等词,而是用代码命名的,比如“n04379243”、“n02834778”、 'n02691156' 等。 TinyImageNet 数据集中共有 200 个唯一标签。
除了创建上述列表之外,我们还为标签初始化了一个编码器。标签需要从字符串编码为整数,因为神经网络不理解字符串,它只理解数字。因此,我们将使用数字 0 代替标签“n01443537”,数字 1 代替标签“n01629819”,数字 2 代替标签“n01641577”,依此类推……
例如,这行代码 encoder_labels.transform(['n02206856', 'n04532670', 'n01770393']) 将返回 array([ 38, 170, 7])。而这行代码encoder_labels.inverse_transform([38, 170, 7])会返回array([‘n02206856’, ‘n04532670’, ‘n01770393’])。这就是编码器的工作原理。
4.Dataset类
Dataset类应该继承自标准的 torch.utils.data.Dataset 类,并且 __getitem__ 应该返回图像(张量)和目标(整数)。
class ImagesDataset(Dataset):
def __init__(self, files, labels, encoder, transforms, mode):
super().__init__()
self.files = files
self.labels = labels
self.encoder = encoder
self.transforms = transforms
self.mode = mode
def __len__(self):
return len(self.files)
def __getitem__(self, index):
pic = Image.open(self.files[index]).convert('RGB')
if self.mode == 'train' or self.mode == 'val':
x = self.transforms(pic)
label = self.labels[index]
y = self.encoder.transform([label])[0]
return x, y
elif self.mode == 'test':
x = self.transforms(pic)
return x, self.files[index]
transforms_train = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.4802, 0.4481, 0.3975], [0.2302, 0.2265, 0.2262]),
transforms.RandomErasing(p=0.5, scale=(0.06, 0.08), ratio=(1, 3), value=0, inplace=True)
])
transforms_val = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.4802, 0.4481, 0.3975], [0.2302, 0.2265, 0.2262])
])
我们还定义了两个复杂的变换 transforms_train 和 transforms_val,它们将用于模型训练和验证。
验证阶段的复杂变换 transforms_val 包括三个简单的变换:将图像大小调整为 224x224,将其转换为张量并对其进行归一化。本质上,transforms_val 实现了 PyTorch 网站的官方指南:
所有预训练模型都期望输入图像以相同的方式归一化,即形状为 (3 x H x W) 的 3 通道 RGB 图像的小批量,其中 H 和 W 预计至少为 224。图像必须加载到 [0, 1] 的范围内,然后使用 mean = [0.485, 0.456, 0.406] 和 std = [0.229, 0.224, 0.225] 进行归一化。
复杂变换 transforms_train 包括与 transforms_val 相同的简单变换,但它还包括随机水平翻转和随机擦除,将在训练阶段应用。因此,我们本质上将“创建新图像”,这将与原始图像略有不同,但仍然非常适合训练我们的模型。换句话说,我们将人为地扩展我们的数据集。
5.可视化数据集中的随机项
在这里,我们将初始化三个数据集(训练、验证和测试),然后我们将看一个来自训练数据集的几个示例:
train_dataset = ImagesDataset(files=files_train,
labels=labels_train,
encoder=encoder_labels,
transforms=transforms_train,
mode='train')
val_dataset = ImagesDataset(files=files_val,
labels=labels_val,
encoder=encoder_labels,
transforms=transforms_val,
mode='val')
test_dataset = ImagesDataset(files=files_test,
labels=None,
encoder=None,
transforms=transforms_val,
mode='test')
fig, axs = plt.subplots(3, 6, figsize=(20,11))
fig.suptitle('Random pictures from train dataset', fontsize=20)
for ax in axs.flatten():
n = np.random.randint(len(train_dataset))
img = train_dataset[n][0]
img = img.numpy().transpose((1, 2, 0))
mean = np.array([0.4802, 0.4481, 0.3975])
std = np.array([0.2302, 0.2265, 0.2262])
img = std * img + mean
img = np.clip(img, 0, 1)
ax.set_title(encoder_labels.inverse_transform([train_dataset[n][1]])[0])
ax.imshow(img)

你可以看到一些图像在不同的地方裁剪了不同大小的部分,这就是随机擦除变换的工作原理。
6.训练模型函数
在这里,我们将定义两个函数:training() 将执行训练模型的所有基本步骤,visualize_training_results() 将在训练完成后向我们显示每个 epoch 的指标图表。
def training(model, model_name, num_epochs, train_dataloader, val_dataloader):
loss_function = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.0003)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.33)
train_loss_array = []
train_acc_array = []
val_loss_array = []
val_acc_array = []
lowest_val_loss = np.inf
best_model = None
for epoch in tqdm(range(num_epochs)):
print('Epoch: {} | Learning rate: {}'.format(epoch + 1, scheduler.get_lr()))
for phase in ['train', 'val']:
epoch_loss = 0
epoch_correct_items = 0
epoch_items = 0
if phase == 'train':
model.train()
with torch.enable_grad():
for samples, targets in train_dataloader:
samples = samples.to(DEVICE)
targets = targets.to(DEVICE)
optimizer.zero_grad()
outputs = model(samples)
loss = loss_function(outputs, targets)
preds = outputs.argmax(dim=1)
correct_items = (preds == targets).float().sum()
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_correct_items += correct_items.item()
epoch_items += len(targets)
train_loss_array.append(epoch_loss / epoch_items)
train_acc_array.append(epoch_correct_items / epoch_items)
scheduler.step()
elif phase == 'val':
model.eval()
with torch.no_grad():
for samples, targets in val_dataloader:
samples = samples.to(DEVICE)
targets = targets.to(DEVICE)
outputs = model(samples)
loss = loss_function(outputs, targets)
preds = outputs.argmax(dim=1)
correct_items = (preds == targets).float().sum()
epoch_loss += loss.item()
epoch_correct_items += correct_items.item()
epoch_items += len(targets)
val_loss_array.append(epoch_loss / epoch_items)
val_acc_array.append(epoch_correct_items / epoch_items)
if epoch_loss / epoch_items < lowest_val_loss:
lowest_val_loss = epoch_loss / epoch_items
torch.save(model.state_dict(), '{}_weights.pth'.format(model_name))
best_model = copy.deepcopy(model)
print("\t| New lowest val loss for {}: {}".format(model_name, lowest_val_loss))
return best_model, train_loss_array, train_acc_array, val_loss_array, val_acc_array
def visualize_training_results(train_loss_array,
val_loss_array,
train_acc_array,
val_acc_array,
num_epochs,
model_name,
batch_size):
fig, axs = plt.subplots(1, 2, figsize=(14,4))
fig.suptitle("{} training | Batch size: {}".format(model_name, batch_size), fontsize = 16)
axs[0].plot(list(range(1, num_epochs+1)), train_loss_array, label="train_loss")
axs[0].plot(list(range(1, num_epochs+1)), val_loss_array, label="val_loss")
axs[0].legend(loc='best')
axs[0].set(xlabel='epochs', ylabel='loss')
axs[1].plot(list(range(1, num_epochs+1)), train_acc_array, label="train_acc")
axs[1].plot(list(range(1, num_epochs+1)), val_acc_array, label="val_acc")
axs[1].legend(loc='best')
axs[1].set(xlabel='epochs', ylabel='accuracy')
plt.show();
在函数 training() 中,我们在每个 epoch 后检查损失。如果某个时期的验证损失达到新的最小值,那么我们更新最佳模型权重并使用 torch.save() 函数保存它们。
7.训练单个模型
让我们创建数据加载器并为每个模型训练 10 个 epoch:
train_dataloader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=64, shuffle=False)
num_epochs = 15
接下来,我们将训练模型并展示结果:
7.1 训练 DenseNet161
model_densenet161 = models.densenet161(pretrained=True)
for param in model_densenet161.parameters():
param.requires_grad = False
model_densenet161.classifier = torch.nn.Linear(model_densenet161.classifier.in_features, out_features=200)
model_densenet161 = model_densenet161.to(DEVICE)
densenet161_training_results = training(model=model_densenet161,
model_name='DenseNet161',
num_epochs=num_epochs,
train_dataloader=train_dataloader,
val_dataloader=val_dataloader)
model_densenet161, train_loss_array, train_acc_array, val_loss_array, val_acc_array = densenet161_training_results
min_loss = min(val_loss_array)
min_loss_epoch = val_loss_array.index(min_loss)
min_loss_accuracy = val_acc_array[min_loss_epoch]
visualize_training_results(train_loss_array,
val_loss_array,
train_acc_array,
val_acc_array,
num_epochs,
model_name="DenseNet161",
batch_size=64)
print("\nTraining results:")
print("\tMin val loss {:.4f} was achieved during epoch #{}".format(min_loss, min_loss_epoch + 1))
print("\tVal accuracy during min val loss is {:.4f}".format(min_loss_accuracy))

Training results:
Min val loss 0.0195 was achieved during iteration #13
Val accuracy during min val loss is 0.6895
7.2 训练 ResNet152
model_resnet152 = models.resnet152(pretrained=True)
for param in model_resnet152.parameters():
param.requires_grad = False
model_resnet152.fc = torch.nn.Linear(model_resnet152.fc.in_features, 200)
model_resnet152 = model_resnet152.to(DEVICE)
resnet152_training_results = training(model=model_resnet152,
model_name='ResNet152',
num_epochs=num_epochs,
train_dataloader=train_dataloader,
val_dataloader=val_dataloader)
model_resnet152, train_loss_array, train_acc_array, val_loss_array, val_acc_array = resnet152_training_results
min_loss = min(val_loss_array)
min_loss_epoch = val_loss_array.index(min_loss)
min_loss_accuracy = val_acc_array[min_loss_epoch]
visualize_training_results(train_loss_array,
val_loss_array,
train_acc_array,
val_acc_array,
num_epochs,
model_name="ResNet152",
batch_size=64)
print("\nTraining results:")
print("\tMin val loss {:.4f} was achieved during epoch #{}".format(min_loss, min_loss_epoch + 1))
print("\tVal accuracy during min val loss is {:.4f}".format(min_loss_accuracy))
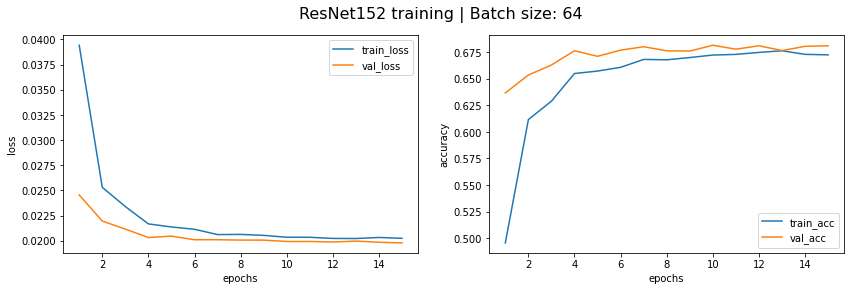
Training results:
Min val loss 0.0198 was achieved during iteration #15
Val accuracy during min val loss is 0.6810
7.3 训练 VGG19
model_vgg19_bn = models.vgg19_bn(pretrained=True)
for param in model_vgg19_bn.parameters():
param.requires_grad = False
model_vgg19_bn.classifier[6] = torch.nn.Linear(in_features=model_vgg19_bn.classifier[6].in_features, out_features=200)
model_vgg19_bn = model_vgg19_bn.to(DEVICE)
vgg19_bn_training_results = training(model=model_vgg19_bn,
model_name='VGG19_bn',
num_epochs=num_epochs,
train_dataloader=train_dataloader,
val_dataloader=val_dataloader)
model_vgg19_bn, train_loss_array, train_acc_array, val_loss_array, val_acc_array = vgg19_bn_training_results
min_loss = min(val_loss_array)
min_loss_epoch = val_loss_array.index(min_loss)
min_loss_accuracy = val_acc_array[min_loss_epoch]
visualize_training_results(train_loss_array,
val_loss_array,
train_acc_array,
val_acc_array,
num_epochs,
model_name="VGG19_bn",
batch_size=64)
print("\nTraining results:")
print("\tMin val loss {:.4f} was achieved during epoch #{}".format(min_loss, min_loss_epoch + 1))
print("\tVal accuracy during min val loss is {:.4f}".format(min_loss_accuracy))
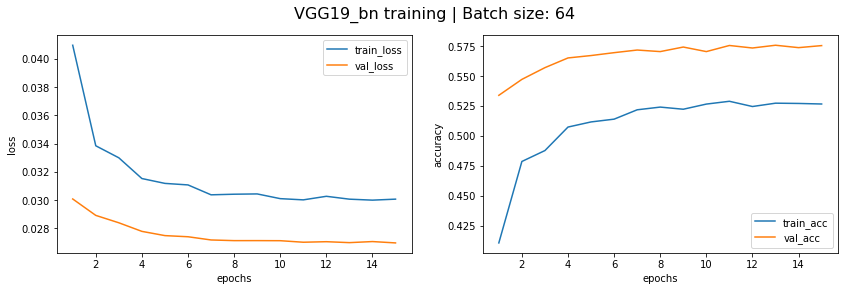
Training results:
Min val loss 0.0270 was achieved during epoch #15
Val accuracy during min val loss is 0.5753
7.4 训练总结
我们看到 DenseNet161、ResNet152 和 VGG19 的验证集准确度分别为 68.95%、68.10%、57.53%。让我们尝试通过将这些模型组合成一个整体来获得更好的准确性。
8.训练模型集成
这是本教程最重要的部分,我们将定义和初始化一个集成模型:
class EnsembleModel(nn.Module):
def __init__(self, modelA, modelB, modelC):
super().__init__()
self.modelA = modelA
self.modelB = modelB
self.modelC = modelC
self.classifier = nn.Linear(200 * 3, 200)
def forward(self, x):
x1 = self.modelA(x)
x2 = self.modelB(x)
x3 = self.modelC(x)
x = torch.cat((x1, x2, x3), dim=1)
out = self.classifier(x)
return out
ensemble_model = EnsembleModel(model_densenet161, model_resnet152, model_vgg19_bn)
for param in ensemble_model.parameters():
param.requires_grad = False
for param in ensemble_model.classifier.parameters():
param.requires_grad = True
ensemble_model = ensemble_model.to(DEVICE)
让我们训练我们的集成模型:
ensemble_training_results = training(model=ensemble_model,
model_name='Ensemble',
num_epochs=20,
train_dataloader=train_dataloader,
val_dataloader=val_dataloader)
ensemble_model, train_loss_array, train_acc_array, val_loss_array, val_acc_array = ensemble_training_results
min_loss = min(val_loss_array)
min_loss_iteration = val_loss_array.index(min_loss)
min_loss_accuracy = val_acc_array[min_loss_iteration]
visualize_training_results(train_loss_array,
val_loss_array,
train_acc_array,
val_acc_array,
num_epochs=20,
model_name="Ensemble model",
batch_size=64)
print("\nTraining results:")
print("\tMin val loss {:.4f} was achieved during iteration #{}".format(min_loss, min_loss_iteration + 1))
print("\tVal accuracy during min val loss is {:.4f}".format(min_loss_accuracy))

Training results:
Min val loss 0.0176 was achieved during iteration #18
Val accuracy during min val loss is 0.7113
集成模型验证集准确率为71.13%,高于独立模型验证集准确率(68.95%、68.10%和57.53%)。
9.分类测试数据集
这部分是可选的,因为本教程的目的是展示如何创建一个神经网络集合,并表明它提供了比单个模型更好的结果。 但是,这里是代码块,它对测试数据集进行分类并将结果保存到 csv 文件中:
test_dataloader = DataLoader(test_dataset, batch_size=64, shuffle=False)
all_preds = []
all_files = []
ensemble_model.eval()
with torch.no_grad():
for samples, f_names in tqdm(test_dataloader):
samples = samples.to(DEVICE)
outputs = ensemble_model(samples)
preds = outputs.argmax(dim=1)
all_preds.extend(preds.tolist())
all_files.extend(f_names)
all_filenames = [f_name[30:] for f_name in all_files]
all_preds_decoded = encoder_labels.inverse_transform(all_preds)
submission_ensemble_df = pd.DataFrame(list(zip(all_filenames, all_preds_decoded)), columns =['File', 'Prediction'])
submission_ensemble_df.to_csv('test_predictions_ensemble.csv', header=False, index=False)
submission_ensemble_df.head(10)

这是一个包含上述所有步骤的 GitHub 存储库和笔记本。
















 284
284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









