






摘要
与现有的复杂方法相比,该方法通常用于从老师那里提取知识给学生,该方法展示了一种简单而强大的方法,可以利用精细的特征映射来转移注意力。事实证明,该方法在提取丰富信息方面是有效的,在作为密集预测任务的语义分割方面优于现有方法。所提出的注意力引导特征蒸馏(AttnFD)方法采用卷积块注意模块(CBAM),该模块通过考虑通道特征信息和空间信息内容来细化特征映射。通过仅使用教师和学生的精细化特征图之间的均方误差(MSE)损失函数,AttnFD在语义分割方面表现出出色的性能。
介绍
虽然逐像素KD有利于图像分类,但由于其捕获像素之间上下文相关性的能力有限,在增强语义分割任务方面面临挑战。
随着研究的进展,已经转向基于特征的蒸馏和对齐教师和学生网络之间的中间特征映射。为了实现这一点,许多方法提出了复杂的损失函数来增强知识蒸馏,因为用简单的距离度量复制特征图有局限性。虽然这些方法是有效的,但最近的研究表明,通过新的模块转换学生特征映射,同时保留基本损失函数,可以使网络更简单,性能更高。
注意机制是为了模仿人类观看视觉场景的方式设计的。事实上,人类倾向于选择具有重要信息的区域(忽略图像的其他地方),而不是一次处理完整的图像。考虑到注意力的长距离上下文语义信息的聚合能力,将其集成到基于特征的KD中有望产生重要影响。尽管有潜力,但这种方法目前在很大程度上未被探索。
与之前的工作不同,之前的工作要么定义复杂的损失来考虑成对关系,要么依赖原始特征,而本研究利用CBAM中的注意机制。这种机制结合了通道和空间信息来产生精细的特征,然后从老师那里提炼出来给学生。图1所命令原始特征和精炼特征之间的区别。

如图所示,经过改进的特征突出了图像的重要区域,并减少了背景噪声,使其成为具有显著蒸馏潜力的强大候选图像。这是因为它迫使学生网络模仿教师强调的重要区域。
贡献
(1)提出一种简单有效的基于注意力的语义分割特征蒸馏方法。通过利用来自教师和学生网络的原始特征图,通道和空间注意力被用来生成精细化的特征图进行蒸馏,通过使用该模块引入了一种新的KD方法。
(2)超越现有的KD语义分割方法。所提出的注意力引导特征蒸馏方法显著提高了紧凑模型在广泛使用的基准数据集上的最先进性能。
相关工作
面向语义分割的知识蒸馏
逐像素KD对于语义分割任务是不够的,因为它们需要关于场景空间结构的更高级别的信息。[41]中的工作建议将学生的8个邻居边界对齐。SKDS使用广告序列运算,并在网络的每个特征映射的通道之前提出成对KD。[39]采用对抗性训练,使用类内特征变异而不是两两蒸馏。此外,还在各个级别提出了进一步的成对蒸馏方法,包括实例级、类级和通道级。最近,人们开始考虑其他形式的关系。DIST通过关注类内和类间的相关性,解决了使用更强教师的挑战。CIRKD提取图像间的关系,以更好地获取关于像素依赖性的全局知识。BPKD对身体和边缘使用单独的蒸馏损失来提高边缘的区分。
尽管这些方法已经被证明是有效的,但它们定义和提取知识的新方法通常会导致复杂的模型,这需要先验知识和仔细的特征提取过程。因此,一些研究倾向于设计模块来转换特征并从中提取丰富的信息。MGD中提出的方法设计掩盖学生特征的随机像素,并训练其复制教师的特征。最近的一些作品也展示了通过直接使用原始特征或通过简单的转换来提高性能。MLP通过使用简单的通道转换,跨通道维度对齐特征来实现这一点。LAD表明,使用教师和学生的原始特征之间的MSE损失可以显著提高性能。
注意力机制
注意机制用于计算机视觉,以帮助模仿人类在处理场景时对图像区域的选择性注意。这种机制允许模型更准确地从图像中提取局部上下文信息,同时降低计算成本。一些方法,如SE-NET和SGE-NET,在通道间水平计算注意力,CBAM表明,在多个维度上获取注意力可以获得更高的准确性,并提出了沿着通道方面的关注利用空间注意力的策略。在KD的背景下,[1]通过结合[9]的概念并在蒸馏过程中使用空间自注意,利用了一种注意力机制。
在这项工作中,我们使用CBAM注意机制改进原始特征,因为它自适应地执行空间和通道注意。据我们所知,这是第一次同时利用空间和通道注意力进行知识蒸馏。
所提出的方法
在本节中,描述了提出的注意引导特征蒸馏的公式。所建议方法的概述如图2所示。
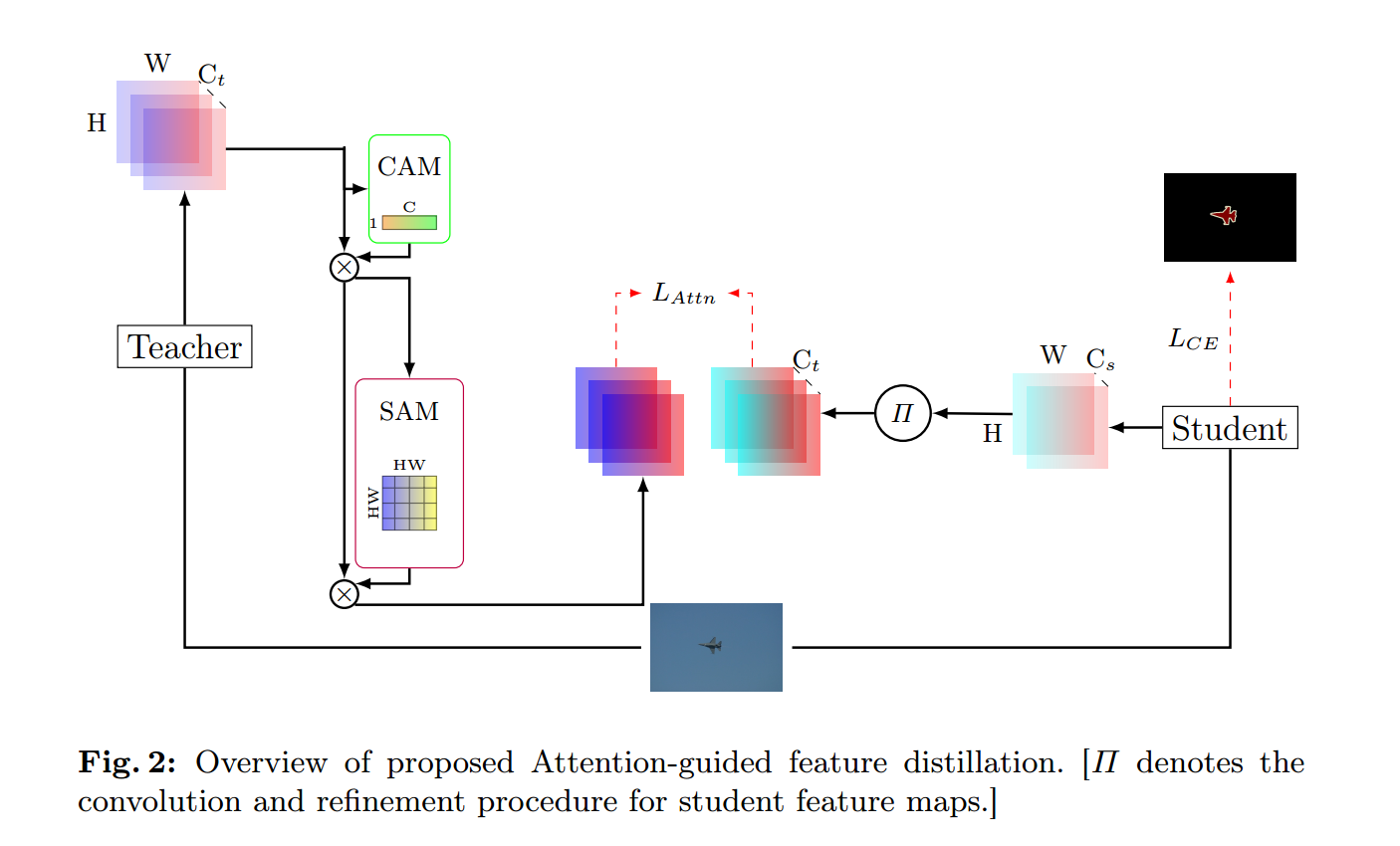
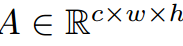 为从教师或学生网络中获得的中间特征映射,空间维度为hxw,通道维度C。在网络的不同阶段,两个注意力模块聚合了中间特征的空间和通道描述符
为从教师或学生网络中获得的中间特征映射,空间维度为hxw,通道维度C。在网络的不同阶段,两个注意力模块聚合了中间特征的空间和通道描述符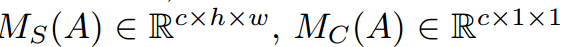 。然后这些空间和通道注意力描述符与原始特征图A相乘,生成新的丰富上下文特征图
。然后这些空间和通道注意力描述符与原始特征图A相乘,生成新的丰富上下文特征图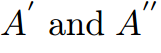 ,将类间和空间间的信息引入原始特征图。特征细化的总体公式为:
,将类间和空间间的信息引入原始特征图。特征细化的总体公式为:

 表示逐像素乘法。在乘法过程中,空间注意力沿通道传播,通道注意图沿空间维度传播。通道注意模块和空间注意模块的方法分贝见图3和图4.
表示逐像素乘法。在乘法过程中,空间注意力沿通道传播,通道注意图沿空间维度传播。通道注意模块和空间注意模块的方法分贝见图3和图4.
通道注意图
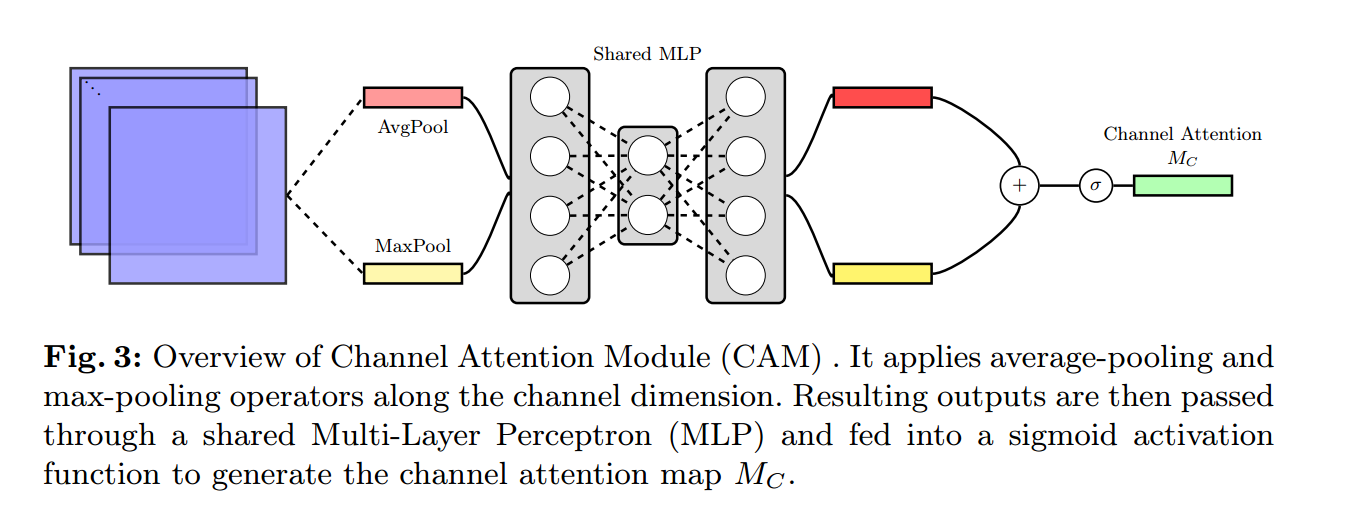
如图3所示,通道注意模块(CAM)通过对中间特征映射A应用最大池化和平均池化算子来聚合空间信息。这些操作产生上下文描述符,然后由多层感知器处理以生成通道注意图Mc(A)。该图突出显示图像的有意义区域,同时模糊与分割任务无关的区域,如背景。中间特征映射A的通道感知描述符定义为:
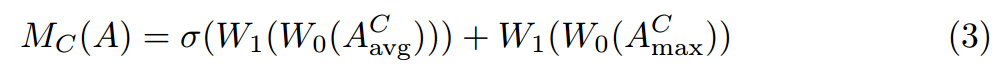
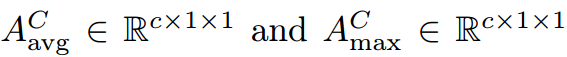 是对中间特征映射。
是对中间特征映射。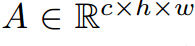 应用平均池化和最大池化算子生成的特征映射。
应用平均池化和最大池化算子生成的特征映射。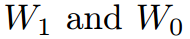 是两个池化特征映射之间的共享MLP的权重。
是两个池化特征映射之间的共享MLP的权重。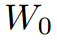 后接ReLU激活函数,
后接ReLU激活函数,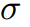 为sigmoid函数。
为sigmoid函数。
空间注意模块
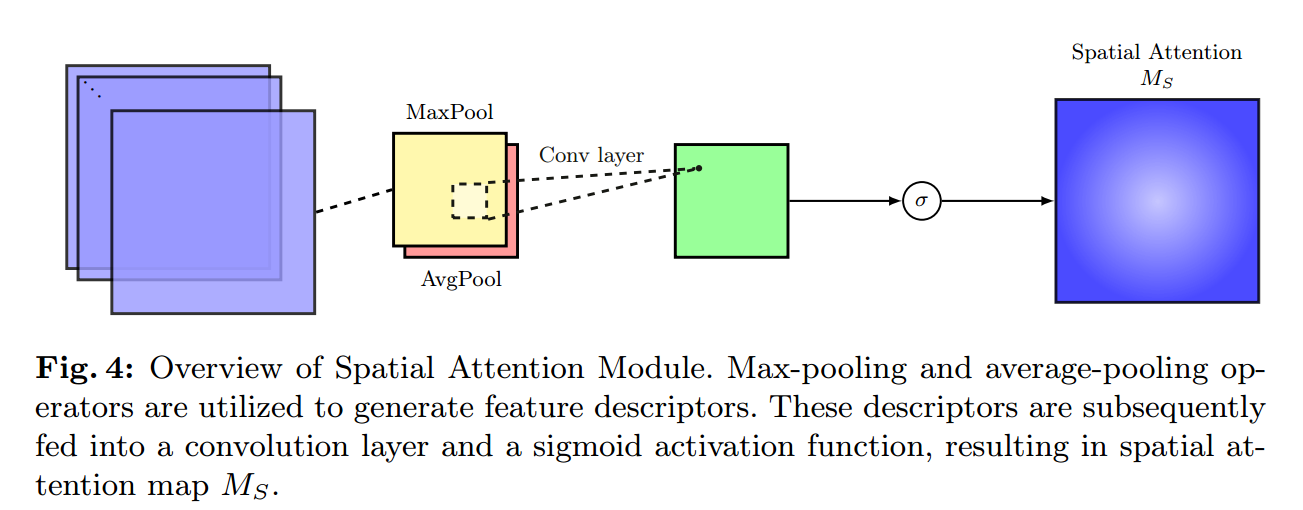
如图4所示,空间注意模块(SAM)的操作与CAM非常相似。中间特征映射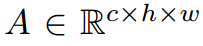 的空间信息通过使用max和averge池化运算符进行聚合,生成两个不同的空间上下文描述符
的空间信息通过使用max和averge池化运算符进行聚合,生成两个不同的空间上下文描述符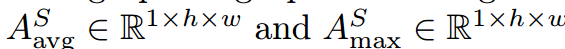 。然后,计算特征映射A的空间上下文描述符为:
。然后,计算特征映射A的空间上下文描述符为:
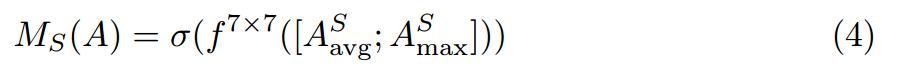
其中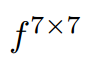 表示一个7x7的卷积核。利用新获得的特征,建议的损失计算为:
表示一个7x7的卷积核。利用新获得的特征,建议的损失计算为:
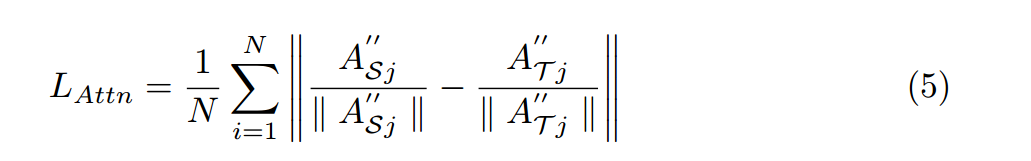
其中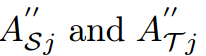 分别表示学生网络和教师网络的第j个中间丰富的上下文特征映射。在计算不同矩阵之前,每个特征映射沿着其通道进行归一化。
分别表示学生网络和教师网络的第j个中间丰富的上下文特征映射。在计算不同矩阵之前,每个特征映射沿着其通道进行归一化。
整体损失函数是的加权和,由:
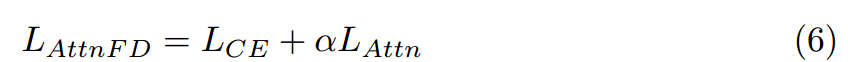
其中是一个权重系数,如4.2中所述进行了微调。在这种情况下,使用众所周知的交叉熵损失函数作为学生网络预测和ground truth标签之间的分割损失。















 973
973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









