









可能逃不了课了!如何使用paddleX来点人头?
原项目链接:https://aistudio.baidu.com/aistudio/projectdetail/2297394

项目背景
大学经常会出现逃课现象,老师就会在每节课之前点一次名,但是点名又浪费时间,而且也不排除有同学中途离开的情况。那么如何做到老师点名方便,学生也不能中途离开呢?
直到看了这个视频【教室人头检测 人头计数】我找到了答案!其实我们可以使用目标检测算法实时或定时检测课堂人数呀。
本项目分为三部分,具体如下:
- 设计头部目标检测模型,实现单张图片的目标检测。
- 实现对视频流的目标检测
- 部署并进行实时检测
今天要做的就是第一部分,之后两部分会慢慢更新,敬请期待。
思维发散:实现了目标检测来计数,其实也可以通过人脸识别来进行人物判断是否为该同学,再一个是头部姿态检测查看是否有同学上课睡觉、玩手机等。其实可发散的点还很多…
技术介绍
PaddleX目前提供了FasterRCNN和YOLOv3两种检测结构,多种backbone模型,可满足开发者不同场景和性能的需求。
- Box MMAP: 模型在COCO数据集上的测试精度
- 预测速度:单张图片的预测用时(不包括预处理和后处理)
- "-"表示指标暂未更新
| 模型(点击获取代码) | Box MMAP | 模型大小 | GPU预测速度 | Arm预测速度 | 备注 |
|---|---|---|---|---|---|
| YOLOv3-MobileNetV1 | 29.3% | 99.2MB | 15.442ms | - | 模型小,预测速度快,适用于低性能或移动端设备 |
| YOLOv3-MobileNetV3 | 31.6% | 100.7MB | 143.322ms | - | 模型小,移动端上预测速度有优势 |
| YOLOv3-DarkNet53 | 38.9% | 249.2MB | 42.672ms | - | 模型较大,预测速度快,适用于服务端 |
| PPYOLO | 45.9% | 329.1MB | - | - | 模型较大,预测速度比YOLOv3-DarkNet53更快,适用于服务端 |
| FasterRCNN-ResNet50-FPN | 37.2% | 167.7MB | 197.715ms | - | 模型精度高,适用于服务端部署 |
| FasterRCNN-ResNet18-FPN | 32.6% | 173.2MB | - | - | 模型精度高,适用于服务端部署 |
| FasterRCNN-HRNet-FPN | 36.0% | 115.MB | 81.592ms | - | 模型精度高,预测速度快,适用于服务端部署 |
本项目中采用 YOLOv3作为检测模型进行人头计数检测。模型优点是模型小,移动端上预测速度有优势。因为之后要部署到移动端所以我选择了这个模型。
YOLOv3 on Pasacl VOC
| 骨架网络 | 输入尺寸 | 推理时间(fps) | Box AP | 下载 |
|---|---|---|---|---|
| MobileNet-V1 | 608 | - | 75.2 | 下载链接 |
| MobileNet-V3 | 608 | - | 79.6 | 下载链接 |
| MobileNet-V1-SSLD | 608 | - | 78.3 | 下载链接 |
| MobileNet-V3-SSLD | 608 | - | 80.4 | 下载链接 |
采用paddleX进行训练
PaddleX 集成飞桨智能视觉领域图像分类、目标检测、语义分割、实例分割任务能力,将深度学习开发全流程从数据准备、模型训练与优化到多端部署端到端打通,并提供统一任务API接口及图形化开发界面Demo。开发者无需分别安装不同套件,以低代码的形式即可快速完成飞桨全流程开发。
PaddleX 经过质检、安防、巡检、遥感、零售、医疗等十多个行业实际应用场景验证,沉淀产业实际经验,并提供丰富的案例实践教程,全程助力开发者产业实践落地。
安装PaddleX
!pip install paddlex==2.0rc
数据集准备
数据集介绍
地址:https://github.com/HCIILAB/SCUT-HEAD-Dataset-Release
描述
SCUT-HEAD是一个大规模的头部检测数据集,包括4405张标有111251个头部的图像。该数据集由两部分组成。我们用xmin、ymin、xmax和ymax坐标标记了每个可见的头像,并确保注释覆盖整个头像,包括被遮挡的部分,但没有额外的背景。PartA和PartB都被分为训练和测试部分。我们的数据集遵循Pascal VOC的标准。
- PartA包括从一所大学的教室监控视频中抽出的2000张图像,其中有67321个头部的标记。PartA的1500张图片用于训练,500张用于测试。因为大学的教室通常看起来很相似,而且人们的姿势变化较小,所以我们仔细选择有代表性的图像,以获得差异性并减少相似性。
- PartB包括2405张图像,有43940个头部分标记。PartB的1905张图片用于训练,500张用于测试。这些图片都是从互联网上抓取的。数据集中还提供了图片的URL。
代表性的图像和注释以及人头数的直方图显示如下。

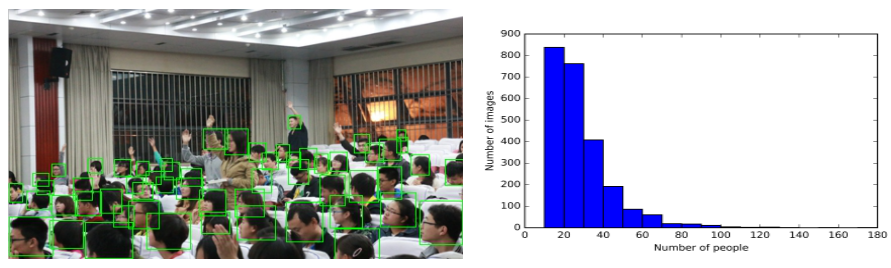
原数据集是分为A和B两部分,我将两个数据集合进行了合并。
数据集结构
本项目使用的头部检测据集已经按VOC格式进行标注,数据集按照如下方式进行组织:
MyDataset/ # 目标检测数据集根目录
|--Annotations/ # 标注文件所在目录
| |--PartA_00000.xml
| |--PartB_00000.xml
| |--...
| |--...
|--JPEGImages/ # 原图文件所在目录
| |--PartA_00000.jpg
| |--PartB_00000.jpg
| |--...
| |--...
|
使用paddleX的数据划分后,会在MyDataset下生成labels.txt, train_list.txt, val_list.txt和test_list.txt,分别存储类别信息,训练样本列表,验证样本列表,测试样本列表
MyDataset/ MyDataset/
├── Annotations/ --> ├── Annotations/
├── JPEGImages/ ├── JPEGImages/
├── labels.txt
├── test_list.txt
├── train_list.txt
├── val_list.txt
解压数据集
# 解压数据集到MyDataset文件夹中
!unzip data/data104969/SCUT_HEAD_Part_A_B.zip
数据切分
使用paddlex命令即可将数据集随机划分成70%训练集,20%验证集和10%测试集:
划分好的数据集会额外生成labels.txt, train_list.txt, val_list.txt, test_list.txt四个文件,之后可直接进行训练。
# 数据划分
!paddlex --split_dataset --format VOC --dataset_dir MyDataset --val_value 0.2 --test_value 0.1
模型训练
PaddleX提供了丰富的视觉模型,通过查阅PaddleX模型库,在目标检测中提供了RCNN和YOLO系列模型。在本项目中采用YOLOv3-MobileNetV3作为检测模型进行钢材缺陷检测。
import paddlex as pdx
from paddlex import transforms as T
# 定义训练和验证时的transforms
# API说明:https://github.com/PaddlePaddle/PaddleX/blob/release/2.0-rc/paddlex/cv/transforms/operators.py
train_transforms = T.Compose([
T.MixupImage(mixup_epoch=250), T.RandomDistort(),
T.RandomExpand(im_padding_value=[123.675, 116.28, 103.53]), T.RandomCrop(),
T.RandomHorizontalFlip(), T.BatchRandomResize(
target_sizes=[320, 352, 384, 416, 448, 480, 512, 544, 576, 608],
interp='RANDOM'), T.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
eval_transforms = T.Compose([
T.Resize(
608, interp='CUBIC'), T.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 定义训练和验证所用的数据集
# API说明:https://github.com/PaddlePaddle/PaddleX/blob/release/2.0-rc/paddlex/cv/datasets/voc.py#L29
train_dataset = pdx.datasets.VOCDetection(
data_dir='MyDataset',
file_list='MyDataset/train_list.txt',
label_list='MyDataset/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.VOCDetection(
data_dir='MyDataset',
file_list='MyDataset/val_list.txt',
label_list='MyDataset/labels.txt',
transforms=eval_transforms,
shuffle=False)
# 初始化模型,并进行训练
# 可使用VisualDL查看训练指标,参考https://github.com/PaddlePaddle/PaddleX/tree/release/2.0-rc/tutorials/train#visualdl可视化训练指标
num_classes = len(train_dataset.labels)
model = pdx.models.YOLOv3(num_classes=num_classes, backbone='MobileNetV3_ssld')
因为训练时间比较久所以我将项目生成了版本并添加到任务中,大概训练了两天多,最后出现了运行超时的情况。项目保存了240epoch中最好的模型参数,以下是代码和最后运行结果显示。你可以选择不运行,我已经将结果的文件保存在了output文件夹下面,可以直接调用来预测。
# API说明:https://github.com/PaddlePaddle/PaddleX/blob/release/2.0-rc/paddlex/cv/models/detector.py#L155
# 各参数介绍与调整说明:https://paddlex.readthedocs.io/zh_CN/develop/appendix/parameters.html
model.train(
num_epochs=300,
train_dataset=train_dataset,
train_batch_size=8,
eval_dataset=eval_dataset,
learning_rate=0.001 / 8,
warmup_steps=1000,
warmup_start_lr=0.0,
save_interval_epochs=20,
lr_decay_epochs=[216, 243, 275],
save_dir='output/yolov3_mobilenet')
2021-08-23 18:13:24 [INFO] [TRAIN] Epoch=250/300, Step=75/385, loss_xy=38.430443, loss_wh=8.015266, loss_obj=29.320236, loss_cls=0.007324, loss=75.773270, lr=0.000001, time_each_step=2.42s, eta=13:12:14
2021-08-23 18:13:39 [INFO] [TRAIN] Epoch=250/300, Step=85/385, loss_xy=35.997726, loss_wh=7.326252, loss_obj=32.159790, loss_cls=0.004576, loss=75.488342, lr=0.000001, time_each_step=1.42s, eta=7:46:4
2021-08-23 18:14:11 [INFO] [TRAIN] Epoch=250/300, Step=95/385, loss_xy=38.658329, loss_wh=7.843961, loss_obj=44.429062, loss_cls=0.006634, loss=90.937988, lr=0.000001, time_each_step=3.21s, eta=17:26:54
2021-08-23 18:14:37 [INFO] [TRAIN] Epoch=250/300, Step=105/385, loss_xy=33.023216, loss_wh=6.180038, loss_obj=32.681091, loss_cls=0.011938, loss=71.896286, lr=0.000001, time_each_step=2.64s, eta=14:20:22
2021-08-23 18:14:56 [INFO] [TRAIN] Epoch=250/300, Step=115/385, loss_xy=45.044044, loss_wh=9.812833, loss_obj=36.387749, loss_cls=0.009715, loss=91.254341, lr=0.000001, time_each_step=1.89s, eta=10:17:11
2021-08-23 18:15:24 [INFO] [TRAIN] Epoch=250/300, Step=125/385, loss_xy=46.961983, loss_wh=8.801168, loss_obj=41.595387, loss_cls=0.011555, loss=97.370094, lr=0.000001, time_each_step=2.75s, eta=14:56:28
2021-08-23 18:15:56 [INFO] [TRAIN] Epoch=250/300, Step=135/385, loss_xy=38.750313, loss_wh=7.347077, loss_obj=31.950573, loss_cls=0.007189, loss=78.055145, lr=0.000001, time_each_step=3.21s, eta=17:26:35
训练可视化
由于官方还在更新可视化套件,notebook的可视化插件暂时不能使用,我是通过本地调用visualdl来显示模型的。代码和可视化图如下:
visualdl --logdir output/yolov3_mobilenet/vdl_log --port 8001
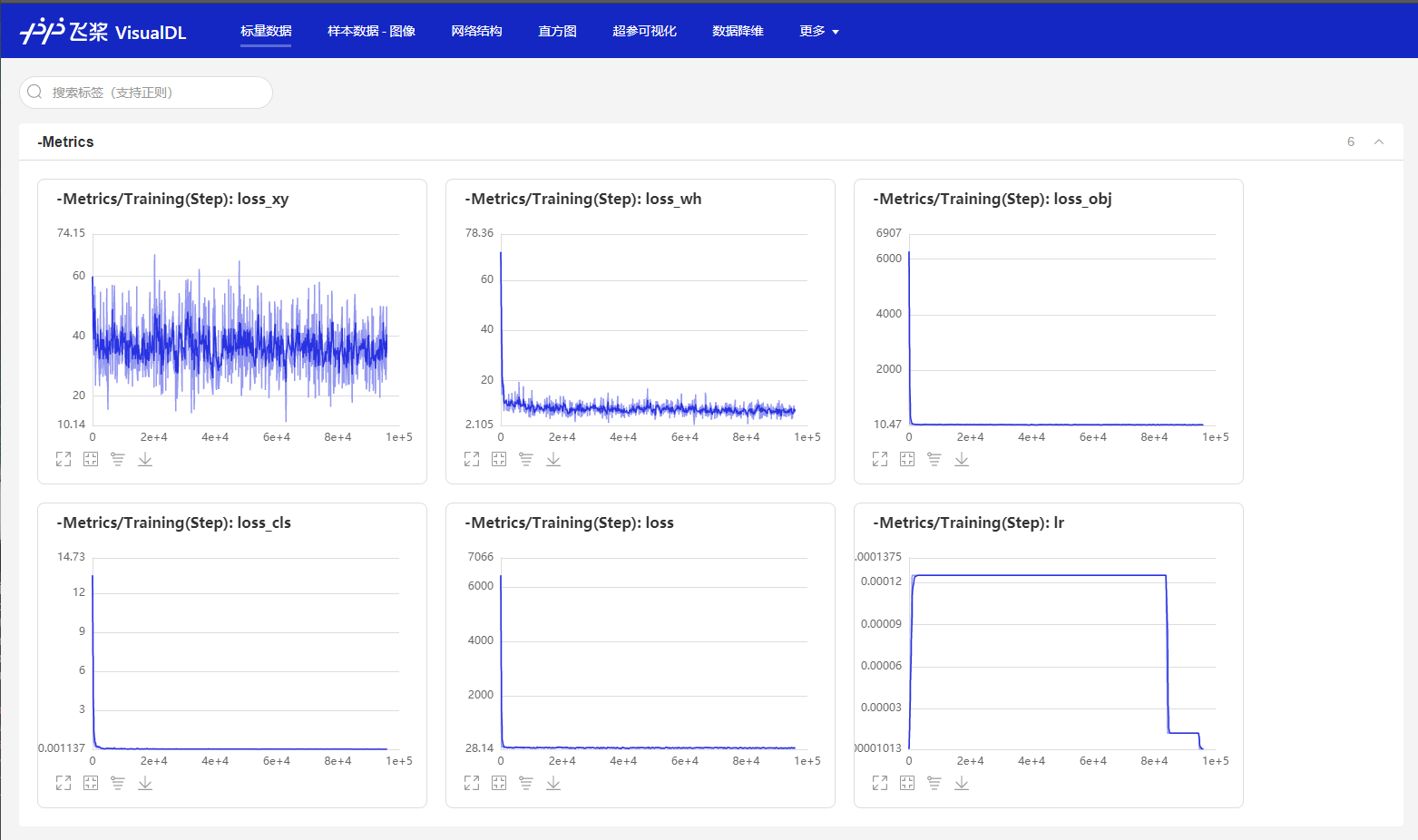
模型导出
模型训练后保存在output文件夹,如果要使用PaddleInference进行部署需要导出成静态图的模型,运行如下命令,会自动在output文件夹下创建一个inference_model的文件夹,用来存放导出后的模型。
#!paddlex --export_inference --model_dir=output/yolov3_mobilenet/best_model --save_dir=output/inference_model --fixed_input_shape=608,608
注意:设定 fixed_input_shape 的数值需与 eval_transforms 中设置的 target_size 数值上保持一致。
模型预测
单张图片预测
import glob
import numpy as np
import threading
import time
import random
import os
import base64
import cv2
import json
import paddlex as pdx
# 可以修改为自己图片路径
image_name = 'MyDataset/JPEGImages/PartB_00234.jpg'
model = pdx.load_model('output/yolov3_mobilenet/best_model')
img = cv2.imread(image_name)
result = model.predict(img)
keep_results = []
areas = []
f = open('result.txt','a')
count = 0
for dt in np.array(result):
cname, bbox, score = dt['category'], dt['bbox'], dt['score']
if score < 0.5:
continue
keep_results.append(dt)
count+=1
f.write(str(dt)+'\n')
f.write('\n')
areas.append(bbox[2] * bbox[3])
areas = np.asarray(areas)
sorted_idxs = np.argsort(-areas).tolist()
keep_results = [keep_results[k]
for k in sorted_idxs] if len(keep_results) > 0 else []
print(keep_results)
print(count)
f.write("the total number is :"+str(int(count)))
f.close()
2021-08-24 00:35:12 [INFO] Model[YOLOv3] loaded.
[{'category_id': 0, 'category': 'person', 'bbox': [393.8019104003906, 377.0484619140625, 78.72943115234375, 98.293212890625], 'score': 0.7811394929885864}, {'category_id': 0, 'category': 'person', 'bbox': [1.057403564453125, 400.1436462402344, 59.849395751953125, 117.39389038085938], 'score': 0.5846558213233948}, {'category_id': 0, 'category': 'person', 'bbox': [428.771728515625, 265.0635681152344, 74.36968994140625, 87.94879150390625], 'score': 0.7089531421661377}, {'category_id': 0, 'category': 'person', 'bbox': [681.1305541992188, 262.43829345703125, 68.670166015625, 86.78857421875], 'score': 0.6637181043624878}, {'category_id': 0, 'category': 'person', 'bbox': [131.41738891601562, 308.42169189453125, 67.57061767578125, 85.93670654296875], 'score': 0.6480881571769714}, {'category_id': 0, 'category': 'person', 'bbox': [165.4634552001953, 236.5949249267578, 57.139984130859375, 74.31608581542969], 'score': 0.823858380317688}, {'category_id': 0, 'category': 'person', 'bbox': [35.94823455810547, 174.2455596923828, 57.02870178222656, 72.42282104492188], 'score': 0.8691303133964539}, {'category_id': 0, 'category': 'person', 'bbox': [620.3713989257812, 218.96636962890625, 52.7181396484375, 74.57086181640625], 'score': 0.8356168866157532}, {'category_id': 0, 'category': 'person', 'bbox': [337.5766906738281, 172.527587890625, 55.636962890625, 65.50875854492188], 'score': 0.6792547106742859}, {'category_id': 0, 'category': 'person', 'bbox': [812.6361083984375, 223.4636688232422, 54.3773193359375, 66.04664611816406], 'score': 0.8799186944961548}, {'category_id': 0, 'category': 'person', 'bbox': [898.570068359375, 273.6473388671875, 50.9766845703125, 69.44610595703125], 'score': 0.6156781315803528}, {'category_id': 0, 'category': 'person', 'bbox': [401.0967102050781, 236.1007843017578, 51.164306640625, 65.96574401855469], 'score': 0.5787891149520874}, {'category_id': 0, 'category': 'person', 'bbox': [93.36703491210938, 138.9623260498047, 42.55851745605469, 58.77044677734375], 'score': 0.6309292316436768}, {'category_id': 0, 'category': 'person', 'bbox': [22.433521270751953, 103.44639587402344, 43.950801849365234, 54.501495361328125], 'score': 0.9007895588874817}, {'category_id': 0, 'category': 'person', 'bbox': [529.7369384765625, 181.55055236816406, 40.388916015625, 56.044036865234375], 'score': 0.8154793977737427}, {'category_id': 0, 'category': 'person', 'bbox': [369.97784423828125, 136.90512084960938, 41.36529541015625, 51.54119873046875], 'score': 0.7091591358184814}, {'category_id': 0, 'category': 'person', 'bbox': [722.8265991210938, 173.65138244628906, 39.9769287109375, 53.15435791015625], 'score': 0.902118444442749}, {'category_id': 0, 'category': 'person', 'bbox': [221.68804931640625, 143.0503692626953, 41.972320556640625, 49.5223388671875], 'score': 0.8067881464958191}, {'category_id': 0, 'category': 'person', 'bbox': [948.3322143554688, 186.35934448242188, 40.339111328125, 46.993133544921875], 'score': 0.7051878571510315}, {'category_id': 0, 'category': 'person', 'bbox': [504.7279357910156, 128.1268310546875, 37.934539794921875, 49.834747314453125], 'score': 0.6175071597099304}, {'category_id': 0, 'category': 'person', 'bbox': [221.52951049804688, 96.32772827148438, 37.9188232421875, 47.86006164550781], 'score': 0.7919147610664368}, {'category_id': 0, 'category': 'person', 'bbox': [208.81674194335938, 61.368385314941406, 34.755126953125, 37.581634521484375], 'score': 0.8184848427772522}, {'category_id': 0, 'category': 'person', 'bbox': [547.1865234375, 118.64674377441406, 32.0355224609375, 40.592803955078125], 'score': 0.6190125346183777}, {'category_id': 0, 'category': 'person', 'bbox': [72.35171508789062, 61.84477233886719, 32.53839111328125, 38.659271240234375], 'score': 0.9074193835258484}, {'category_id': 0, 'category': 'person', 'bbox': [661.9373779296875, 166.0024871826172, 32.559814453125, 37.87042236328125], 'score': 0.7100493311882019}, {'category_id': 0, 'category': 'person', 'bbox': [352.2589111328125, 81.90768432617188, 29.9991455078125, 36.46635437011719], 'score': 0.565405011177063}, {'category_id': 0, 'category': 'person', 'bbox': [939.8696899414062, 127.50442504882812, 29.649658203125, 36.87042236328125], 'score': 0.8237748742103577}, {'category_id': 0, 'category': 'person', 'bbox': [273.9945068359375, 45.615928649902344, 28.577392578125, 38.03173828125], 'score': 0.7798858284950256}, {'category_id': 0, 'category': 'person', 'bbox': [859.7190551757812, 118.81365966796875, 30.4107666015625, 35.351776123046875], 'score': 0.7583639025688171}, {'category_id': 0, 'category': 'person', 'bbox': [310.47760009765625, 92.9588623046875, 28.640869140625, 37.0657958984375], 'score': 0.7358092665672302}, {'category_id': 0, 'category': 'person', 'bbox': [566.467041015625, 97.97348022460938, 28.71533203125, 34.86753845214844], 'score': 0.8879408836364746}, {'category_id': 0, 'category': 'person', 'bbox': [438.48822021484375, 98.06320190429688, 27.95550537109375, 34.44622802734375], 'score': 0.8004835247993469}, {'category_id': 0, 'category': 'person', 'bbox': [481.4981384277344, 64.09996032714844, 27.21075439453125, 34.36772155761719], 'score': 0.7442010641098022}, {'category_id': 0, 'category': 'person', 'bbox': [389.46478271484375, 71.48014831542969, 26.5023193359375, 35.07884216308594], 'score': 0.7341712713241577}, {'category_id': 0, 'category': 'person', 'bbox': [84.6544189453125, 37.09909439086914, 27.35589599609375, 31.406993865966797], 'score': 0.7632529139518738}, {'category_id': 0, 'category': 'person', 'bbox': [783.1365966796875, 119.30937957763672, 25.93212890625, 30.99799346923828], 'score': 0.687127947807312}, {'category_id': 0, 'category': 'person', 'bbox': [536.3561401367188, 79.31047058105469, 24.01123046875, 32.87025451660156], 'score': 0.8570495247840881}, {'category_id': 0, 'category': 'person', 'bbox': [669.9501953125, 77.16580200195312, 24.0716552734375, 29.246749877929688], 'score': 0.7641267776489258}, {'category_id': 0, 'category': 'person', 'bbox': [643.5778198242188, 59.733699798583984, 22.159423828125, 31.242542266845703], 'score': 0.7732596397399902}, {'category_id': 0, 'category': 'person', 'bbox': [753.4708862304688, 92.65911865234375, 23.6214599609375, 28.358245849609375], 'score': 0.5029441714286804}, {'category_id': 0, 'category': 'person', 'bbox': [715.93212890625, 59.21143341064453, 22.752685546875, 28.11431884765625], 'score': 0.7938010692596436}]
41
pdx.visualize_detection(image_name, result, threshold=0.5, save_dir='./output/yolov3_mobilenet')
2021-08-24 00:35:17 [INFO] The visualized result is saved at ./output/yolov3_mobilenet/visualize_demo9.png
显示预测结果
预测结果保存在了
./output/yolov3_mobilenet目录下,我在网上找了一些图片来预测人数,从预测结果可以看出效果还算不错,如果你有兴趣还可以尝试修改上方的模型参数或是模型的backbone进行预测。




参考资料
个人介绍
CSDN地址:https://blog.csdn.net/weixin_43267897?spm=1001.2101.3001.5343
Github地址:https://github.com/KHB1698
我在AI Studio上获得黄金等级,点亮5个徽章,来互关呀~ https://aistudio.baidu.com/aistudio/personalcenter/thirdview/791590















 1664
1664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









