







title: Emote Portrait Alive (EMO): Generating Videos with A Photo + Audio Clip
- 英文标题:Emote Portrait Alive: Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
- 中文标题:在弱条件下利用音频到视频的扩散模型生成富有表现力的肖像视频
- 作者:林瑞天 王琪 张棒 薄列峰
- 机构出处:阿里巴巴集团智能计算研究所
- 发布时间:240217
- Paper:[https://arxiv.org/pdf/2402.17485](https://arxiv.org/pdf/2402.17485)
- GitHub:[https://github.com/HumanAIGC/EMO](https://github.com/HumanAIGC/EMO) 7.1k stars (开源但空仓)
- Demo:[https://www.youtube.com/watch?v=VlJ71kzcn9Y](https://www.youtube.com/watch?v=VlJ71kzcn9Y)
薄列峰:是目前的阿里巴巴通义实验室 XR 实验室负责人。博士毕业于西安电子科技大学,先后在芝加哥大学丰田研究院和华盛顿大学从事博士后研究,研究方向主要是 ML、CV 和机器人。其谷歌学术被引数超过 13000 次。
加入阿里前,先是在亚马逊西雅图总部任首席科学家,后又加入京东数字科技集团 AI 实验室任首席科学家。是在 2022 年 9 月,加入阿里
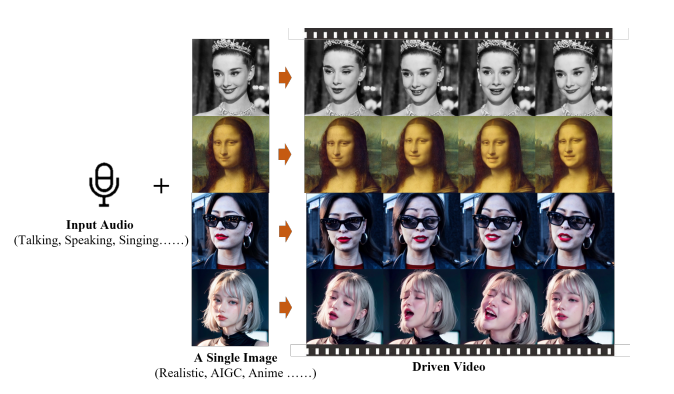
【一个赫本唱perfect的视频,可在官方给出的demo上看到】
示例:Character:Audrey Kathleen Hepburn-Ruston Vocal Source: Ed Sheeran-Perfect. Covered by Samantha Harvey
研究背景:Diffusion 模型在图像和视频生成中的应用
扩散模型用于图像生成的研究很多,且生成图像的能力也一直在迭代,其应用不仅限于静态图像,对视频生成、动态图像也有好多工作一直在研究,比如 DreamTalk,还有之前阿里发的让全世界小猫小狗都在跳洗澡舞的 AnimateAnyone 等等,都突显了扩散模型在视频生成领域的可操作性。

AnimateAnyone
在通用视频合成之外,生成以人为中心的视频才是这类工作的焦点,比如 talking head 视频。talking head 的目标是从用户提供的音频剪辑中生成面部表情。制作这些表情涉及捕捉人类面部动作的微妙性和多样性,在视频合成这类工作中就不那么容易。传统方法通常对最终视频输出施加约束来简化这项工作。例如,一些方法使用 3D 模型限制面部关键点,而其他方法则从基础视频中提取头部运动序列来指导整体运动,虽然这些约束能降低视频生成的复杂性,但同时也会限制最终面部表情的自然性和丰富性。
EMO 方法概述
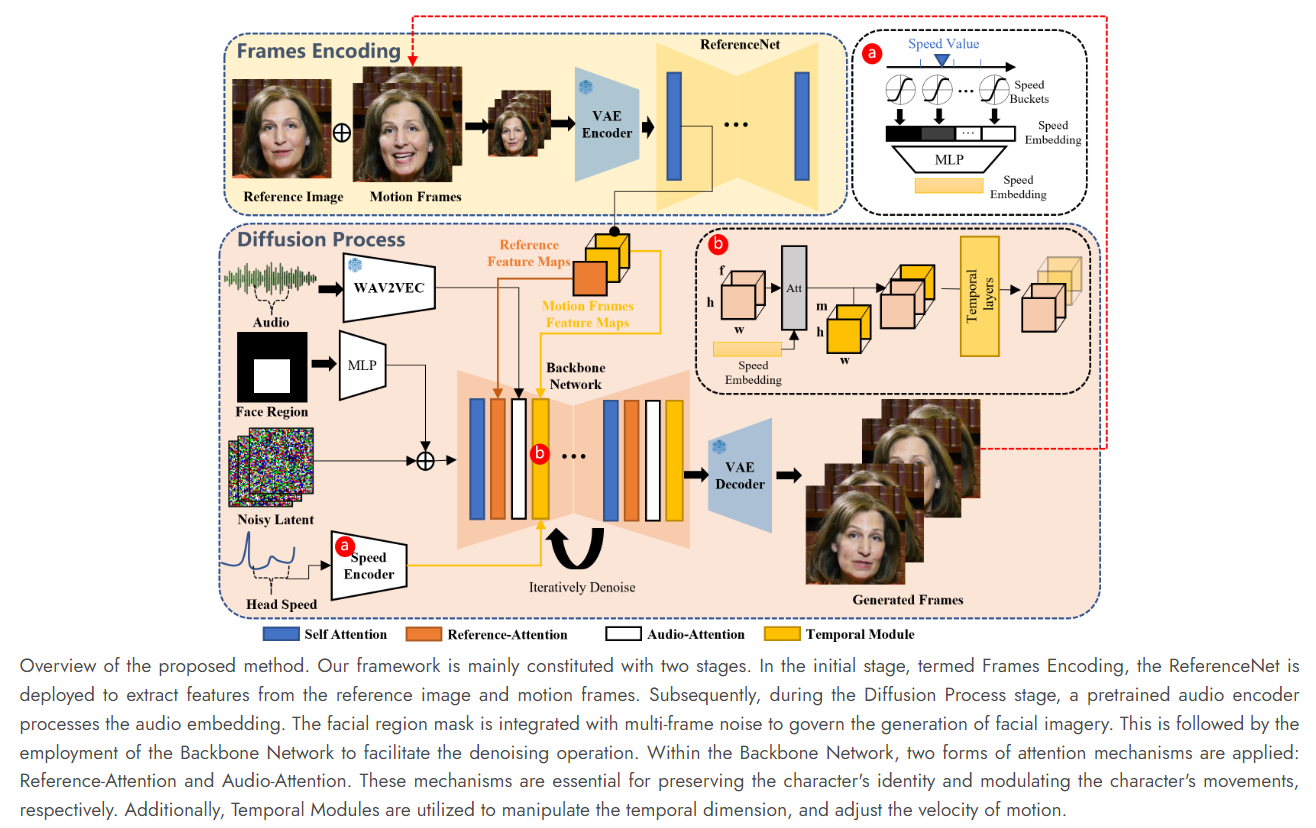
EMO 工作流程
1. 从音频到视频:EMO 的工作原理
论文提出的 EMO 方法旨在建立一个创新的 talking head 框架,旨在捕捉一系列真实的面部表情,包括微妙的微表情,并促进自然的头部运动,从而赋予生成的头部视频前所未有的表现力。为实现这一目标,作者提出了一种利用 Diffusion 模型的生成能力的方法,能够直接从给定的图像和音频剪辑合成角色头部视频。这种方法消除了对中间表示或复杂预处理的需求,简化了创造高度视觉和情感真实性的 talking head 视频的过程,与音频输入中的细微差别紧密对齐。音频信号在理论上富含与面部表情相关的信息,使模型能够生成多样化的表情动作。然而,将音频与 Diffusion 模型结合并非易事,因为音频和面部表情之间的映射存在固有的模糊性。这个问题可能导致模型产生的视频不稳定,表现为面部扭曲或视频帧之间的抖动,在严重的情况下,甚至可能导致视频完全垮掉。为了解决这一挑战,作者在模型中加入了稳定的控制机制,即速度控制器和面部区域控制器,以增强生成过程中的稳定性。这两个控制器作为超参数,充当微妙的控制信号,不会影响最终生成视频的多样性和表现力。
2. 创新点:无需强控制信号的生成策略
EMO方法的创新之处在于,它不需要强控制信号来生成视频。传统的方法可能会使用3D 模型或其他中间表示来控制角色的运动,但这些控制信号的自由度有限,且在训练阶段的标记不足以捕捉面部动态的全部范围。此外,相同的控制信号可能导致不同角色之间的差异,未能考虑到个体差异。因此,我们选择了一种“弱”控制信号方法。具体来说,我们使用一个面部区域掩码作为控制面部应该生成的位置的手段。此外,为了在不同片段之间创建一致和平滑的运动,我们将目标头部运动速度纳入生成过程。通过这种方式,我们可以同步生成角色头部的旋转速度和频率,与面部定位器提供的面部位置控制相结合,生成的输出既稳定又可控。
EMO 框架解读
EMO 整体框架
0.帧编码和扩散处理
- 帧编码(Frames Encoding)是利用 ReferenceNet 从参考图像和运动帧中提取特征,主要目的是为了和视频中角色保持一致性
- 扩散处理(Diffusion Process)云训练的音频编码器处理音频嵌入,面部区域掩码和多帧噪声相结合,用来控制面部图像的生成,是利用 Backbone Network 进行去噪
1. 基础网络与 ReferenceNet 的结合
作者采用了一个名为 ReferenceNet 的 UNet 结构,与基础网络(Backbone Network)并行运行。ReferenceNet 的主要作用是输入参考图像以提取参考特征,这些特征将在生成过程中用于保持角色身份的一致性。基础网络和 ReferenceNet 都源自原始的 Stable Diffusion(SD)1.5 UNet 架构,因此它们在某些层次上生成的特征图很可能相似,这有助于基础网络整合 ReferenceNet 提取的特征。此外,ReferenceNet 和基础网络都继承了原始 SD UNet 的权重,确保了目标对象身份的一致性。采用 SD 模型作为基础框架的优势在于既能降低计算成本,又能保持较高的视觉保真度。
2. 音频层和注意力机制的应用
音频层通过预训练的 wav2vec 模型对输入音频序列进行特征提取,生成的音频表示嵌入用于驱动角色的口型运动。为了考虑未来/过去音频片段对运动的影响,还定义了每个生成帧的语音特征,通过连接附近帧的特征来实现。在基础网络的每个参考注意力层之后,我们添加了音频注意力层,这些层在潜在代码和音频特征之间执行交叉注意力机制,以将语音特征注入生成过程中。
3. 时间模块与连贯性生成
为了维持生成帧之间的连续性和一致性,在基础网络中嵌入了时间模块。这些模块通过自注意力层对帧内特征进行操作,以捕捉视频的动态内容。作者还采用了前一视频片段的最后 n 帧(称为“运动帧”)来增强跨片段的一致性。在去噪过程中,我们将时间层的输入与相应分辨率的预提取运动特征合并,从而确保了不同片段之间的连贯性。
4. 对 a 的解读
-
速度值和速度桶:
- 根据音频内容中的情绪强度或者节奏,我们可以计算出相应的速度值。
- 这些速度值会被分配到不同的速度桶中,每个桶代表了一个特定的速度范围。
- 这种划分方式有助于我们在生成面部动画时,根据音频内容中的情绪变化灵活调整动画的速度。
-
速度嵌入:
- 最终,所有的速度信息都会被整合成一个速度嵌入向量,这个向量会作为额外的输入传递给我们的模型,从而影响生成的面部表情。
概括说,EMO 的原理就是利用 ReferenceNet 和 BackboneNet 两个网络相结合,前一个网络从图像中提取人物面部图像特征,后一个网络从音频中提取"情绪"的波动,通过语音识别模型 Wav2vec 进行连接+前一个网络传进来的面部特征+再加一些噪声都给到 Backbone 网络,这个网络跟 SD 1.5 的结构类似,里面掺着两种注意力机制:参考注意力(Reference-Attention)和音频注意力(Audio-Attention)这两种机制在图像和语音特征之间交叉执行,一个用来保证人物身份,另一个用来调节人物动作。然后还有一个时间模块用于操控时间维度和调整运动速度,不“张冠李戴”,生成与音频输入动态相匹配的视频,进一步增强动画的真实感
一个比较好的地方是,虽然说基础网络需要反复多次对噪声进行去噪处理,但是目标图像和运动帧只需要连接一次并传给 ReferenceNet,因此,提取的特征会在整个过程中重复使用,确认推理过程中的计算时间不会大幅度增加。
训练策略和数据集构建
1. 三阶段训练过程
训练过程分为三个阶段。第一阶段是图像预训练阶段,此时基础网络、ReferenceNet 和面部定位器(Face Locator)进入训练。第二阶段引入了视频训练,此时加入了时间模块和音频层。最后一个阶段,集成了速度层,仅训练时间模块和速度层。这种策略是有意识的选择,因为作者发现同时训练速度和音频层会削弱音频对角色运动的驱动能力。
2. 高质量多样化数据集的构建
为了训练我们的模型,构建了一个庞大而多样化的音视频数据集,包含超过250小时的视频和超过1.5亿张图像。这个数据集包含了演讲、电影和电视剧片段以及歌唱表演,并涵盖了多种语言,如中文和英文。此外还补充了大型户外高分辨率视听数据集 HDTF 和高质量的视频人脸数据集 VFHQ 的内容。这种丰富多样的训练材料确保了作者提出的模型能够捕捉到广泛的人类表情和声音风格,为 EMO 的开发提供了坚实的基础。
实验设置和定量评估
1. 实验设计和比较方法
为了评估 EMO 框架的性能,构建了一个包含250小时视频资料和超过1.5亿图像的广泛多样的音视频数据集。这个数据集包含了演讲、电影和电视剪辑以及歌唱表演,并涵盖了中文和英文等多种语言。在 HDTF 数据集上进行了广泛的实验和比较,将 EMO 与现有的最先进方法(包括 DreamTalk、Wav2Lip 和 SadTalker)进行了对比。在实验设置中,将 HDTF 数据集分为两部分,10%作为测试集,其余90%用于训练,确保训练集和测试集之间没有角色 ID 的重叠。
2. 定量评估指标的选择与意义
采用了多个定量评估指标来衡量生成视频的质量。这些指标包括 Fréchet Inception Distance (FID)、SyncNet、Facial Similarity (F-SIM)和 Fréchet Video Distance (FVD)。FID 用于评估生成帧的质量,SyncNet 评分用于评估嘴唇同步的质量,F-SIM 通过提取和比较生成帧与参考图像之间的面部特征来计算,用于评估 EMO 在保持身份方面的表现。FVD 用于视频级别的评估。此外,还引入了表情 FID (E-FID)指标,通过面部重建技术提取表情参数,然后计算这些表情参数的 FID,以量化衡量合成视频中的表情与真实数据集中的表情之间的差异。
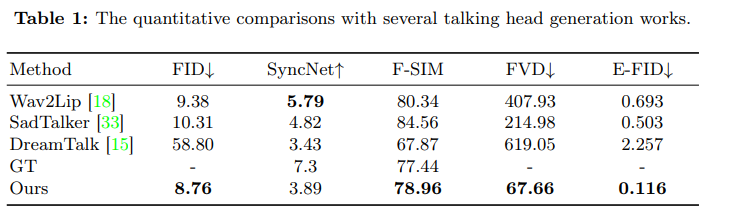
*FID 和 E-FID 越小,表明合成视频表情与真实表情越像,SyncNet 越小说明生成的说话视频中唇部运动与对应语音的同步性越好,F-SIM 衡量面部特征相似性,FVD 是对视频的整体评估
定性分析与用户研究
1. 不同风格人像视频的生成效果
EMO 模型不仅能够生成逼真的说话视频,还能够生成各种风格的唱歌视频。即使模型仅是在真实视频上进行训练,它也能够处理多种不同的肖像风格,包括现实、动漫和3D 风格的角色。通过使用相同的声音输入,这些不同风格的角色都能够实现大致一致的嘴唇同步。此外 EMO 模型还能够根据输入音频的长度生成任意时长的视频,保持角色身份的一致性,即使在大幅度运动中也能保持。
2. 用户研究和定性评价
作者还进行了全面的用户研究和定性评估,结果表明 EMO 模型能够生成高度自然和富有表现力的说话和唱歌视频。用户研究揭示了作者提出的方法在生成具有不同音调和表情的视频方面的能力。例如,高音调的声音会激发角色更加强烈和生动的表情。通过使用运动帧,EMO 还能够生成更长时间的视频,根据输入音频的长度,就可以生成延长的视频序列。
论文局限性和贡献
1. 局限性
尽管 EMO 框架在生成音频驱动的人像视频方面取得了显著的进步,但仍存在一些局限性。首先,与不依赖扩散模型的方法相比,论文的方法在时间上更为耗费。其次,由于是没有使用任何显式的控制信号来控制角色的动作,这可能导致在视频中无意中生成其他身体部位,如手部,从而在视频中产生人为的视觉效果。此外,由于本研究的速度桶框架的设计,生成的头部运动只能大致接近指定的速度级别,这可能会限制表达的自然性和连贯性。
2. 贡献
EMO 框架的核心贡献在于创新性的将扩散模型应用于音频驱动的人像视频生成中,实现了从单张参考图像和音频片段直接合成具有高度表现力和真实感的人像视频。该框架通过引入稳定控制机制,如速度控制器和面部区域控制器,增强了生成过程的稳定性,同时保留了视频的多样性和表现力。
此外,EMO 框架通过构建一个庞大且多样化的音视频数据集,包含超过 250 小时的视频和超过 1.5 亿张图像,涵盖了包括演讲、电影电视剪辑和歌唱表演在内的多种内容,以及包括中文和英文在内的多种语言。丰富的数据集为模型的训练提供了坚实的基础。
在 HDTF 数据集上进行的广泛实验和比较表明,EMO 框架在多个指标上超越了当前的最先进方法,包括 DreamTalk,Wav2Lip 和 SadTalker,无论是在表现力还是真实感方面,都取得了显著的提升。此外,通过客户研究和定性评估,证明了该方法能够生成高度自然和富有表现力的人像视频,包括说话和唱歌视频,达到了目前最好的效果。
“弱条件”:意味着只需最低限度的输入就能生成质量很高的视频
直接音视频合成:不借助三维模型或面部点的检测,就意味着不需要额外建模或者面部点映射,简化了生成过程并减少了潜在的不确定性
…
目前 EMO 已被集成到通义千问中,在聊天框中输入 EMO 就会跳到“全民唱演/舞王”,点击“立即体验”就行,目前已经支持“自定义唱演”,需要做 2 个任务,还有让兵马俑唱从军行的,上传的图片有限制,要正面照,还不能露手,尝试传入一个卡通头像(就正在用的微信头像)会显示识别不到人脸
title: VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis
- 英文标题:VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis# VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis
- 中文标题:VLOGGER:多模态扩散的化身头像合成技术
- 作者:xx(外国人)
- 机构出处:Google Research
- 发布时间:240308
- Paper:[https://enriccorona.github.io/vlogger/paper.pdf](https://enriccorona.github.io/vlogger/paper.pdf)
- Demo:[https://enriccorona.github.io/vlogger/](https://enriccorona.github.io/vlogger/)
VLOGGER 是什么
VLOGGER AI 是谷歌的研究团队开发的一个多模态扩散模型,专门用于从单一输入图像和音频样本生成逼真的、连贯的人像动态视频。该模型的主要功能在于使用人工智能模型,将一张静态图片转换为一个动态的视频角色,同时保持照片中人物的逼真外观。此外,VLOGGER 还能够根据音频来控制人物动作,不仅仅是面部动作和嘴唇同步,还包括头部运动、目光、眨眼以及上身和手部手势,从而将音频驱动的视频合成有了新的进展。
VLOGGER 的工作原理
VLOGGER 的目标是生成一个可变长度的逼真视频,来描绘目标人物的讲话行为(如头部和手势等)。VLOGGER 是基于 Generative Diffusion Models (一个当时效果挺好的视频生成扩散模型)的基础上构建的,用于对从语音到视频的一对多映射进行建模。
VLOGGER 的工作原理主要基于一个两阶段的流程,结合了音频驱动的运动生成和时间连贯的视频生成。
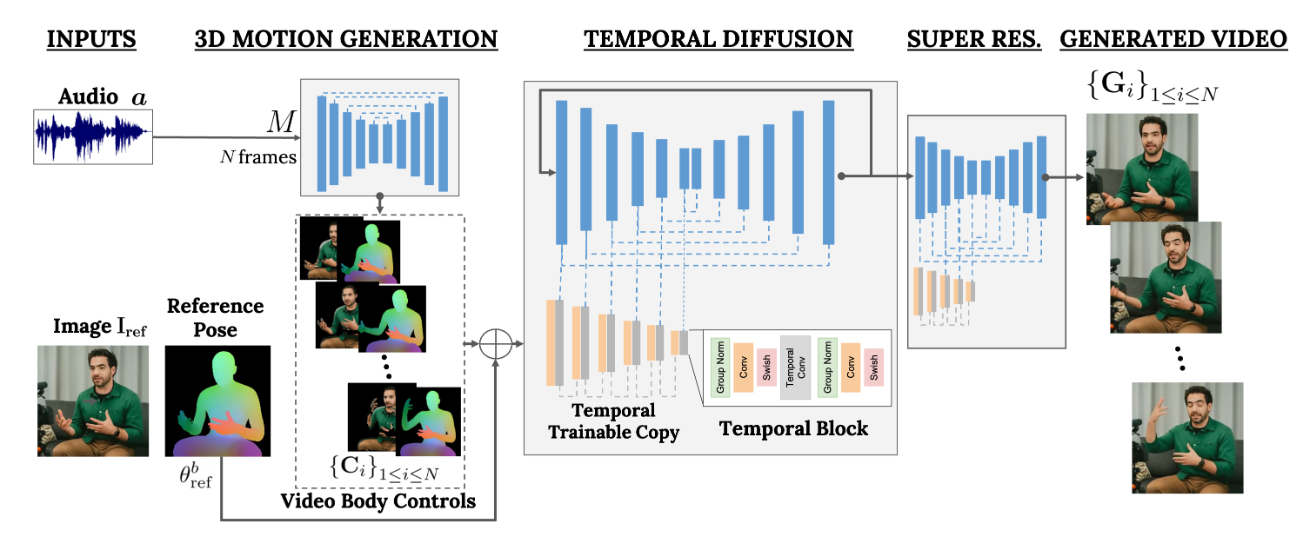
第一阶段:音频驱动的运动生成
音频处理: VLOGGER 首先接收一段音频输入,这段音频可以是语音或音乐。如果输入是文本,它也会通过文本到语音(TTS)模型转换为音频波形
3D 运动预测: 然后,系统使用一个基于变换器(Transformer)架构的网络来处理音频输入。这个网络用来从输入的音频中预测与音频同步的 3D 面部表情和身体动作。网络使用多步注意力层来捕捉音频的时间特征,并生成一系列的 3D 姿势参数,作者说这是“模拟语音与姿势、目光与表情之间微妙的(一对多)映射所必需的”
生成控制表示: 网络输出的一系列预测的面部表情和身体姿势的残差。这些参数随后用于生成控制视频生成过程的 2D 表示
以音频作为输入来生成中间身体动作特征,负责控制人物在视频中的动作(比如注视、面部表情和姿势等)。通过从单个图像扩散来合成动态人物动作,捕获语音与人物动作各个方面的细微映射,从而实现逼真的动画生成。
第二阶段:时间连贯的视频生成
视频生成模型: VLOGGER 的第二个阶段是一个时间扩散模型,它接收第一阶段生成的 3D 运动和一张参考图像(即输入的单一人物图像)
条件化视频生成: 视频生成模型是一个基于扩撒的图像到图像翻译模型,它利用预测的 2D 控制来生成一系列帧,这些帧按照输入的音频和 3D 运动擦书进行动画处理
超分辨率: 为了提高视频质量,VLOGGER 还包括一个超分辨率扩散模型,它将基础视频的分辨率从 128 x 128 提高到更高的分辨率,如 256 x 256 或 512 x 512
时间外延: VLOGGER 使用时间外延(temporal outpainting)的技术来生成任意长度的视频。它首先生成一定数量的帧,然后基于前一帧的信息迭代的生成新的帧,从而扩展视频的长度
以预测的身体动作作为输入,生成相对应的视频帧。这个架构有助于生成可变长度的高质量视频,同时解决远离面部区域的画面模糊和缺乏连贯性等问题。此外,通过对生成的身体动作的控制,可以调节视频生成过程,从而获得更真实和多样化的效果。
数据集和训练
为了训练和评估 VLOGGER,作者专门构建了 MENTOR 数据集。该数据集是从一个大型内部视频库中筛选出来的,视频中包含单个说话者,大部分时间面向摄像头,主要使用英文交流。视频每秒包含 24 帧,每个视频片段为 10 秒钟,音频采样率为 16kHz。
为了建模视频中交流的人物动作,作者预测了 3D 身体关节和手部信息,并通过最小化投影误差和连续帧之间的时间差来适配 3D 身体模型。为了保证视频质量,作者过滤了以下几种不符合要求的视频:
-
背景变化明显
-
面部或身体只被部分检测到或关节和手部信息预估结果不稳定
-
手部完全无法检测到
-
音频质量较差
最终,得到了一个包含超过 800 多万秒(2000 多小时)和 80 多万个不同人物的训练集,以及一个包含 120 小时和 4000 多个不同人物的测试集。从人物和长度来看,这是目前为止最大的高分辨率视频数据集。此外,MENTOR 数据集包含了广泛的主题多样性(如肤色、年龄)、观点和身体展现姿势,更能代表现实世界的人物行为。 -
VLOGGER 在三个公共基准测试中超越了以往的最先进图像质量、身份保留和包含生成上半身手势的情况下能生成时序一致的结果;
VLOGGER 能干什么
图像和音频驱动的视频生成: VLOGGER 能够根据单张人物图像和相应的音频输入生成人类说话的视频。用户只需要提供一张图片和一段音频,VLOGGER 将生成一个视频中的人物,其面部标签、嘴唇动作和身体语言与音频同步。
多样性和真实性: VLOGGER 生成的视频具有高度的多样性,能够展示原始主体的不同动作和表情,同时保持背景的一致性和视频的真实性
视频编辑: VLOGGER 可以用于编辑现有视频,例如改变视频中人物的表情,使其与原始视频的未改变像素保持一致
生成移动和说话的人物: VLOGGER 可以从单张输入图像和驱动音频生成说话面部的视频,即使没用视频中人物的原始视频资料
视频翻译: VLOGGER 能够将一种语言的视频转换为另一种语言的视频,通过编辑唇部和面部区域以匹配新的音频,实现跨语言的视频内容匹配
两篇论文异同
同:
- 都是基于扩散模型,都不需要对每个人物进行特定的训练,甚至提到的创新点都是不依赖于脸部检测和剪裁,而是直接生成完整的图像视频
- 工作原理也很像,两步,一步提取图像特征,一步处理音频,然后杂糅,边交叉处理,边有一个东东去控制,五官和声音不要乱飞
- VLOGGER 和 EMR 在效果评价方面都很像,图像质量、身份保留等等
- 都构建了一个超巨大的数据集
- 两者的应用可以来回串
异:
- VLOGGER 的 demo 里有一个人的耳边边虚化,一眼假,EMO 的 demo 就很完整,甚至还借了 Sora 的东风–“东京街头的女士唱歌”
- VLOGGER 没有落地,EMO 集成在了通义千问中
- VLOGGER 是关注手部动作的,而 EMO 没有这一项,甚至使用的时候都要求不漏手
【免责声明】为了帮助理解,过程中参考了其他作者的文章,但由于没有及时记录参考链接导致找不着了/(ㄒoㄒ)/,故如有雷同实属必然,介意可联系添加

















 129
129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









