







目录
Computeshader用了很久了,可是用了忘,忘了学,还是做个笔记吧。。
个人笔记只为自己看得懂,文章跳跃性很强,初次接触的朋友还是去找其他资料吧,末尾会附注一些参考资料。
理论
怎么写一个Computeshader
对我而言,Computeshader其实就是用来在GPU计算的一个工具,既然是计算,那么就得有输入+输出+算法。接下来就按这个思路来写。
输入
通常来说Computeshader只做计算工作,所以输入得由其他语言的业务代码来提供,具体到Unity上就是C#脚本文件来设置Computeshader所需的计算资源,而在HLSL语言中则需要用DirectX提供的一系列API设置计算资源(我不会D3D所以不说了)。
资源类型
SRV(Shader Resource View):只读不可写。
UAV(Unordered Access View):可读可写,线程访问顺序随机。在读的同时还可以被写入(但有Race Condition的问题,稍后会讲到)。
以上只是GPU端对计算资源的一个逻辑上的分类,但我们写Computeshader代码的时候并不是直接写一个SRV s = new SRV()这样子,而是使用相当于一个SRV/UAV的一些子类来存储资源。
我们常用的SRV包括:StructuredBuffer<Type>,Texture2D<Type>
我们常用的UAV包括:RWStructuredBuffer<Type>,RWTextured2D<Type>
其中Type可以是基本类型,如int,float,uint,float2等等,也可以是自定义的结构体。
Computeshader声明资源的代码如下。
struct MyType{
float f1;
float f2;
float f3;
float f4;
};
RWStructuredBuffer<MyType> outData;
StructuredBuffer<int> inData;
RWTexture2D<float4> Result;然而我们说过,GPU的计算资源需要由CPU设置,那么在CPU端自然需要有同等实体与之对应,一般的,与Texture2D/RWTexture2D对应的是Unity中的Texture2D/RenderTexture类型,与StructuredBuffer/RWStructuredBuffer对应的是ComputeBuffer类型。
以下是Unity使用C#设置StructuredBuffer/RWStructuredBuffer的方式
//首先要在C#代码里声明结构体,这个结构体要与Computeshader中的结构体对应
//变量名可以不一样,但是对应的变量类型应该要一样,因为GPU是通过算字节偏移量找数据的
struct MyTypeInCPU
{
float f1;
float f2;
float f3;
float f4;
}
void AssignComputeBuffer()
{
int num = 10;
//ComputeBuffer有五种类型,一般用默认类型即可,其他参数我没用过
ComputeBuffer buffer = new ComputeBuffer(num, sizeof(float) * 4);
MyTypeInCPU[] array = new MyTypeInCPU[num];
buffer.SetData(array);
//先找到Kernel
int kernel = shader.FindKernel("KernalName");
//使用SetBuffer()方法设置buffer,第二个参数是Computeshader里Buffer的名字
shader.SetBuffer(kernel, "outData", buffer);
}而对于Texture2D这种资源也是类似
void AssignTexture2D()
{
//格式千万要注意,格式不同画面效果完全不一样
RenderTexture tex = new RenderTexture(1280, 1024, 0, RenderTextureFormat.ARGB64);
//一定要开启tex的这个选项才能允许GPU写入数据
tex.enableRandomWrite = true;
int kernel = shader.FindKernel("KernalName");
shader.SetTexture(kernel, "Result", tex);
}输出
当Computeshader运行结束后,CPU端可以从GPU端获取运行结果,但这是一个非常耗时的操作,CPU与GPU传输速度大概只有GPU访问VRAM速度的百分之一。
代码如下,注意,只有UAV资源才可以获得运行结果(因为只有UAV可被写入)。
MyTypeInCPU[] mies = new MyTypeInCPU[10];
buffer.GetData(mies);而对于RWTexture2D等类型在Computeshader运行结束后就已经被改变了,不需要GetData()之类的操作,在C#代码里直接访问即可。
算法/执行
并不是真的要讲Computeshader的并行算法,这里主要是讲如何让GPU执行代码,或者叫分派线程,具体术语和原理略过,末尾有参考,这里放两张图和一段代码就行。

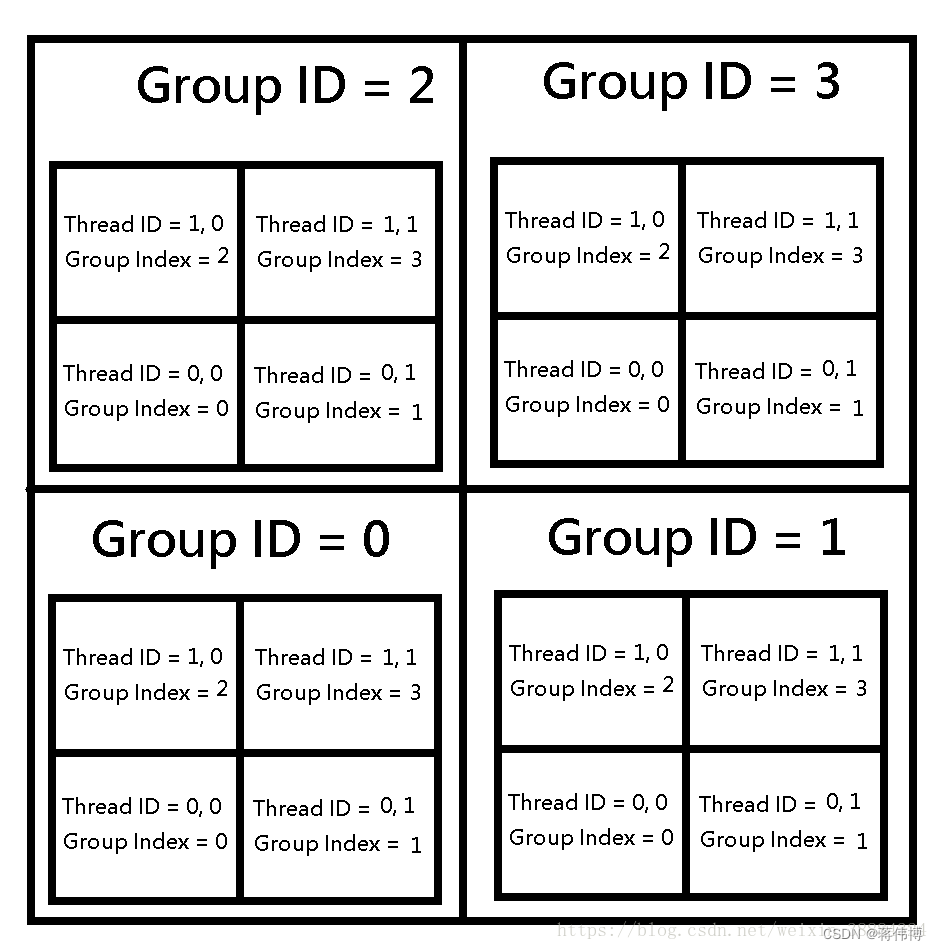
//C#代码
int kernel = shader.FindKernel("CSMain");
shader.Dispatch(kernel, width/8, height/8, 1);//Computeshader代码
#pragma kernel CSMain
[numthreads(8,8,1)]
void CSMain (uint3 id : SV_DispatchThreadID,uint groupIndex : SV_GroupIndex)
{
//Do something...
}注意事项
同步机制
在Computeshader中,越界写入是no-op(无操作),越界读取的值是0
首先非常可惜的一点,GPU不存在全局同步(哪天存在了请给我烧纸),最多只有同一个线程组内可以同步。
同一个线程组的线程,必然同时执行。
不同线程组的线程,可能同时执行,可能不同时执行。
线程之间同时Access一块数据,通过一个叫做bank layout的东西,如果多个线程同时访问这个同一个地址,就产生了bank冲突,因此,可以得出结论:任何时候,尽量减少Access。如果一块shared memory非要多次访问,甚至可以用一个临时变量保存/复制出来,而不是直接访问这个显存。
以上是基本结论,下面补充一下Race Condition的概念。
First of all, a race condition happens whenever one thread writes to a memory location while another thread reads OR writes from/to that same location. So, yes,
+=is already causing a race condition, and there is no "easy" way to fix this. (Btw:+=implicitly reads the value, because you can't calculate the sum of two values without knowing them)
而在Computeshader中也存在Race Condition(之前提到的Bank Layout可以算Race Condition的特殊情况)的概念,但情况稍微有点点不同。
当不同线程同时向同一处Memory写入相同数据时不会有问题(但是性能会下降);当不同线程同时向同一处Memory写入不同数据时发生Race Condition。
言归正传,Computeshader的同步机制据我所知有三种。
第一,groupshared关键字。用groupshared修饰的资源(无论是UAV还是SRV)在同一个线程组内部都是共享的,还可以用GroupMemoryBarrierWithGroupSync()来使线程组同步,如下
#pragma kernel CSMain
groupshared int si[64];
[numthreads(8,8,1)]
void CSMain (uint3 id : SV_DispatchThreadID,uint groupIndex : SV_GroupIndex)
{
si[groupIndex]++;
//在所有该线程组内的线程运行到GroupMemoryBarrierWithGroupSync()这行代码之前
//暂停该线程的运行
GroupMemoryBarrierWithGroupSync();
//Do something else...
}第二种,原子操作+循环。
下面的代码可以实现原子操作的对浮点数的加法。
void InterlockedAddFloat(RWByteAddressBuffer buf, uint addr, float value)
{
uint i_val = asuint(value);
uint tmp0 = 0;
uint tmp1;
while(true)
{
buf.InterlockedCompareExchange(addr, tmp0, i_val, tmp1);
if(tmp1 == tmp0)
break;
tmp0 = tmp1;
i_val = asuint(value + asfloat(tmp1));
}
}慎重使用,极难DEBUG,出现死循环就得关机重启。
第三种,原子操作+全局变量。
RWStructuredBuffer<data> outData;
RWStructuredBuffer<uint> maxBuffer;
[numthreads(8,8,1)]
void CSMain (uint3 id : SV_DispatchThreadID,uint groupIndex : SV_GroupIndex)
{
InterlockedAdd(maxBuffer[0],1);
if(maxBuffer[0]>30) outData[id.y*8+id.x].i1=500;
}这段代码并不能实现所有线程的互斥操作,但可以实现在一次分派线程(Dispatch)中,对maxBuffer的访问是全局且互斥的。
实例
略过。
参考
上面两篇对于入门选手非常值得一看。https://gamedev.net/forums/topic/452857-changing-global-variables-in-hlsl/3991607/![]() https://gamedev.net/forums/topic/452857-changing-global-variables-in-hlsl/3991607/ Variable Syntax - Win32 apps | Microsoft DocsUse the following syntax rules to declare HLSL variables.
https://gamedev.net/forums/topic/452857-changing-global-variables-in-hlsl/3991607/ Variable Syntax - Win32 apps | Microsoft DocsUse the following syntax rules to declare HLSL variables.![]() https://docs.microsoft.com/en-us/windows/win32/direct3dhlsl/dx-graphics-hlsl-variable-syntax
https://docs.microsoft.com/en-us/windows/win32/direct3dhlsl/dx-graphics-hlsl-variable-syntax
HLSL InterLockedAdd Float - 知乎HLSL 的 InterlockedAdd 只提供了 uint/int 类型的原子相加 HLSL interlockedAdd function但是有的时候需要用到 float 类型数据的原子加法, InterlockedAddFloatvoid InterlockedAddFloat(RWByteAddressBuffer bu…![]() https://zhuanlan.zhihu.com/p/376313103Unity中Compute Shader的基础介绍与使用_UWA的博客-CSDN博客_compute shader前言Compute Shader是如今比较流行的一种技术,例如之前的《天刀手游》,还有最近大火的《永劫无间》,在分享技术的时候都有提到它。Unity官方对Compute Shader的介绍如下:Unity - Manual: Compute shadersCompute Shader和其他Shader一样是运行在GPU上的,但是它是独立于渲染管线之外的。我们可以利用它实现大量且并行的GPGPU算法,用来加速我们的游戏。在Unity中,我们在Project中右键,即可创建出一个Comput.
https://zhuanlan.zhihu.com/p/376313103Unity中Compute Shader的基础介绍与使用_UWA的博客-CSDN博客_compute shader前言Compute Shader是如今比较流行的一种技术,例如之前的《天刀手游》,还有最近大火的《永劫无间》,在分享技术的时候都有提到它。Unity官方对Compute Shader的介绍如下:Unity - Manual: Compute shadersCompute Shader和其他Shader一样是运行在GPU上的,但是它是独立于渲染管线之外的。我们可以利用它实现大量且并行的GPGPU算法,用来加速我们的游戏。在Unity中,我们在Project中右键,即可创建出一个Comput.https://blog.csdn.net/UWA4D/article/details/120821195Unity | 浅谈 Compute Shader - 知乎之前Compute Shader入门过一次,太久不用就给忘了,希望这次可以学得扎实。 目录: Part1: Compute Shader入门 - Kyle Halladay Part2: 如何使用贴图来Debug Compute Shader - 十笔 再次感谢Kyle Halladay,本篇文…
![]() https://zhuanlan.zhihu.com/p/113482286ComputeShader – Cheney Shen
https://zhuanlan.zhihu.com/p/113482286ComputeShader – Cheney Shen![]() https://cheneyshen.com/category/all/gpu/compute-shader/
https://cheneyshen.com/category/all/gpu/compute-shader/
《DirectX12 3D游戏开发实战》















 1549
1549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









