







2023年第十三届MathorCup高校数学建模挑战赛
D题 航空安全风险分析和飞行技术评估问题
原题再现
飞行安全是民航运输业赖以生存和发展的基础。随着我国民航业的快速发展,针对飞行安全问题的研究显得越来越重要。2022 年 3 月 21 日,“3.21”空难的发生终结了中国民航安全飞行 1 亿零 59 万飞行小时的历史最好安全记录。严重飞行事故的发生,不仅会给航空公司带来巨大的经济损失,更会对乘客造成极大的生命威胁。因而需要聚焦飞行安全问题,强化航空安全研究,综合利用现有数据强化科学管理,通过有针对性、系统性的管控手段有效提升从业人员的素质,监测和预警风险,进而降低飞行事故的发生几率。
航空安全大数据主要包括快速存取记录器(Quick Access Recorder,QAR)数据,该数据主要记录飞机在飞行过程中的各项飞行参数;在飞行品质监控(Flight Operational Quality Assurance,FOQA)中,QAR 中超出人为设定限制值的数据记为超限数据。除此之外,在实际研究过程中,还会涉及到飞行中的舱音数据等。本问题主要涉及的是 QAR 数据,QAR 数据相对比较规范。
在飞行品质监控具体研究和应用方面,目前我国民航业内的研究主要分为两个方面,一是针对超限事件的研究、分析和应用;二是对非超限数据的统计分析和应用。对于超限事件的研究,一般是通过规定飞行参数的集中区域设置超限阈值,将超出阈值部分的飞行记录找出来,进行重点分析,防范潜在隐患造成严重飞行事故。目前此类分析是飞行品质监控工作的主体,较好地保证了现阶段的安全工作,其不足之处在于缺少对超限原因的分析。由于超限并非全部是人为因素引发,例如许多是由于特殊环境条件造成的,甚至有可能是飞机本身的设计、制造因素所致,因此仅通过单纯的超限分析很难识别出来;如果仅基于超限事件对飞行机组进行管理,很容易误入歧途。QAR 超限可用于航空安全管理和飞行训练的数据支持。目前并不倾向于仅以少量的 QAR 超限数据为依据开展飞行训练工作,因此飞行品质监控工作逐渐衍生出另外一种倾向性,即通过挖掘 QAR 全航段数据开展分析,形成特定人员的飞行品质记录。基于不同飞行机组、飞行航线、机场、特定飞行条件下的飞行记录,通过对数据进行建模、分析,计算评估风险倾向性,开展有针对性的安全管理,排查安全隐患,改进安全绩效。目前类似研究主要是大规模读取飞行数据,并进行存储和分析,形成飞行品质服务平台,为风险评估和趋势分析提供数据基础。G 值是飞机飞行过程中过载情况的直接反应,在着陆安全分析中,G 值通常是描述落地瞬间安全性的重要指标。着陆瞬间 G 值指的是飞机接地瞬间前 2 秒和后5 秒数据的最大 G 值。
基于以上背景,请你们团队解决以下问题:
问题 1:有些 QAR 数据存在错误,需要对数据进行预处理,去伪存真,以减少错误数据对研究分析带来的影响。请你们的队伍对附件 1 的数据质量开展可靠性研究,提取与飞行安全相关的部分关键数据项,并对其重要程度进行分析。
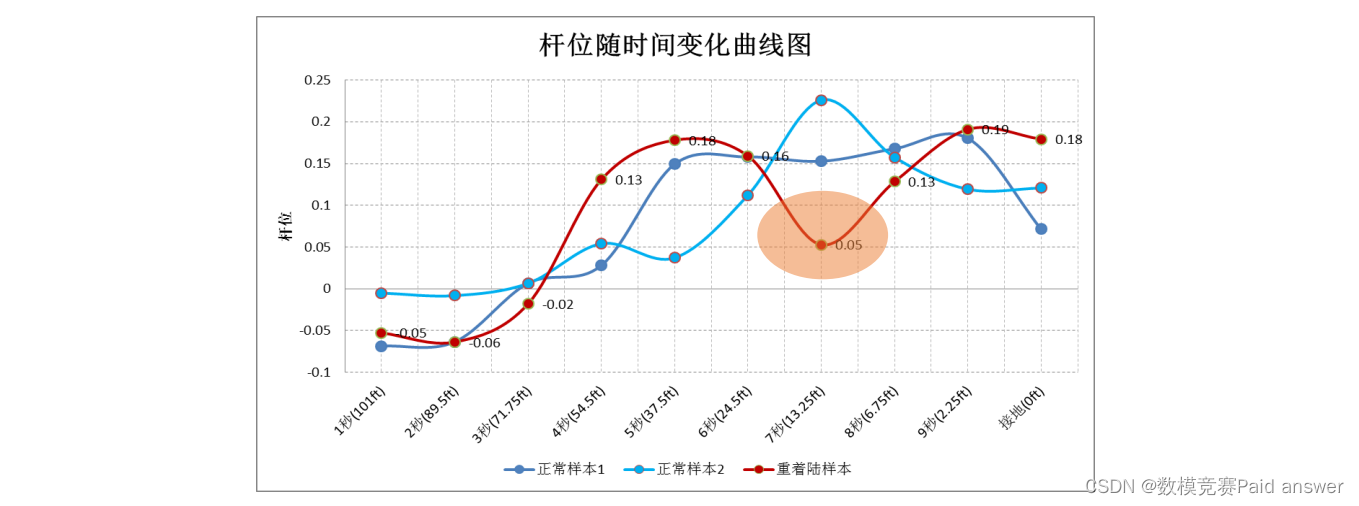
问题 2:飞机在从起飞到着陆的整个飞行过程中,通过一系列的飞行操纵确保飞行安全,这些操纵主要包括横滚操纵、俯仰操纵等。目前,国内航空公司通过超限监控飞行操纵动作,这种监控方法虽然能够快速分辨出飞机的状态偏差,但是只能告诉安全管理人员发生了什么,而不能立刻得出发生这种偏差的原因。为此,可以通过操纵杆的过程变化情况来分析产生这种偏差的原因。根据附件 1,请你们对飞行操纵进行合理量化描述。下图为 3 次着陆过程中的杆位变化曲线,其中红色曲线描述了一次重着陆(着陆 G 值超过给定限制值)过程,该重着陆主要是由于飞行机组在低空有一次不当松杆操纵所致,红色曲线中的接地前 5 秒有一个明显下凸,这就是需要进行量化描述的一次松杆操纵。
问题 3:导致不同超限发生的原因各不相同,有时是特定机场容易出现特定的超限,有时是特定的天气容易出现特定的超限,有时是特定的飞行员容易出现特定的超限。请研究附件 2 的数据,对超限的不同情况进行分析,研究不同超限的基本特征,如分析飞机在哪些航线或者在哪些机场容易出现何种超限等。
问题 4:飞机运行数据的研究一般分为两大类,一类是通过航线运行安全检查(Line Operations Safety Audit,LOSA)获取的飞行员的运行表现,另外一类是根据相关学者建议,基于飞行参数开展飞行技术评估。根据附件 3,请你们建立数学模型,探讨一种基于飞行参数的飞行技术评估方法,分析飞行员的飞行技术,数据表中的“不同资质”代表飞行员的不同技术级别。
问题 5:随着技术的进步,未来在民航客机上安装实时传输的 QAR 数据记录系统已成为可能,这种“实时飞行数据”技术,可以在接近实时的情况下把航班飞行数据传输到地面分析系统,极大地提高风险识别能力和预防水平。假设飞行数据已能实现陆空实时传输,如果你是该航空公司的安全管理人员,请建立航空公司实时自动化预警机制,预防可能的安全事故发生,结合附件 1 的数据,给出仿真结果。
整体求解过程概述(摘要)
本题主要是开发一个基于航空安全风险分析及飞行技术评估的预警模型等问题,展开深入研究。通过熵权法、随机森林等数学模型,使用 Python、Matlab、Spsspro 等软件,对操作进行量化描述,超限不同情况进行统计分析,最后,基于参数评估飞行技术建立一个自动化预警模型。从而降低我国航空事故的发生。
对于问题一,首先使用拉伊达法则和箱线图对附件 1 数据进行预处理,再用 Python对于附件 1 中异常的 QAR 数据进行去除,之后用 Python 可视化[1]对数据进行可靠性研究,最后用熵权法得出来每个影响因素的具体权重,其中影响最大的因素是飞机重量,其余前五项关键数据项,分别是风速、无线电高度、风向、右发油门杆位置、左发油门杆位置。
对于问题二,首先用线性回归分析 F 值,验证结果后,可以显着拒绝总回归系数为0 的原假设(P<0.05)。表明之间存在着线性关系并且通过 R²值分析模型拟合情况,同时对 VIF 值进行分析,模型出现共线性后 X 呈现显著性,结合 B 值探究 X、Y 之间关系并确定模型公式。最终得出结论:CAP CLM 1 POSN 和 CAP WHL 1 POSN 的和作为表征量,在其和较大时,说明操作不平稳,反之平稳。
对于问题三,首先对于附件 2 中数据进行超限分析,得到不同情况下的超限类型(下滑道偏差过高或过低、俯仰角率过高或过低等),随后,利用频数分析算法和智能分析对于超限数据进行频数分析,使用 spsspro 对于飞行超限频数所占比例进行绘图。得出频数分析图表,最终可以得出飞机最容易出现的超限类型为:50 英尺至接地距离远,在飞行阶段为 6 时,目的机场为 68 时,最容易出现超限。
对于问题四,首先对附件 3 数据进行预处理,去除无关数据以及空白数据等。随后,基于飞行参数评估飞行技术,建立随机森林、逻辑回归、LGBM 等数学模型,运用机器学习算法来衡量训练集准确度和测试集准确度以及平均绝对误差进行模型评估,从两种方法来评估飞行员的飞行技术(训练分数、交叉验证)。从模型最终结果来看,LGBM 模型对于数据的预测精度良好。
对于问题五,首先进行挖掘学习行为特征的时间序列,设计了一种基于时间记忆增强模型的预警机制,挖掘和预测决策和干预机制。随后选取三种临近最优算法进行对比实验,经过充分的数据训练和测试,计算了图中三个典型数据子集的精度。随着预测戳数的增加,ILA + GAN 的优势更加明显。
模型假设:
结合本题实际,为确保模型求解准确性和合理性,提出以下几点假设:
1. 假设本题中给出所有附件中的数据都真是可信。
2. 假设本题考虑到因素外,其他未考虑的因素都不影响本题的计算。
3. 假设本题中的样本互不影响、互不关联、相互独立,各指标之间互不干扰。
问题分析:
针对问题一的分析
需要我们对 QAR 数据预处理,去伪取真,减少错误数据对研究的影响和误差,根据附件 1 数据进行可靠性研究并且运行数据分析。初步数据处理是指在分类或分组之前,对收集到的数据进行必要的审查、筛选和整理。本题首先我们利用拉依达和箱线图进行数据预处理,去除已知 QAR 数据里的错误数据,进行更深程度的分析,使用熵权法和 python 的可视化[2]计算出权重,对各指标的权重进行分析,得到权重可视化图形,最终得出结论:权重值所在越高,重要程度越高;反之越低。
针对问题二的分析
在整个飞行过程中,从起飞到着陆,飞行安全都受到飞行控制(主要包括横滚操纵、俯仰操纵等)的影响,航空公司只能监测飞行操纵动作从而告诉管理者发生了什么,却不能立刻得出这种偏差的原因无法立即确定。因此,我们必须根据附件 1 对飞行控制进行合理描述,通过操纵杆的变化来分析偏差的原因。本题我们采用线性回归(最小二乘法),进行分析 F 的值,分析 F 值能否明显的拒绝总体回归系数为 0 的原始假设(P<0.05),如呈现显著性,则表示 F 值与其存在线性关系并且经过 R²值分析模型拟合状况,并且对VIF 的值开展分析,(VIF 大于 5 或者 10)如若模型呈现出共线性,则使用逐步回归法。开展 X 显著性的分析;(P<0.05)若呈现显著性,则使用其分析 X 对 Y 的影响关系。结合回归因子 B,比较分析 X 对 Y 的影响。确定模型模式(在应用线性回归之前,可以通过正态性检验或残差数据处理等统计方法对数据进行验证和纯化)。
针对问题三的分析
本题要求我们根据附件 2,对于不同的超限情况进行分析,分析不同超限时的特征。首先我们对附件 2 数据进行超限分析,得出不同超限情况的不同超限类型,之后,利用频数分析算法对不同机场和不同超限类型进行频数分析,得到频数分析图和分析表,最终得出不同地点和时间出现的不同超限特征。
针对问题四的分析
本题要求我们基于飞行参数进行飞行评估并根据附件 3 建立数学模型,使用飞行技术评估方法分析飞行员的飞行技术水平。并且我们基于对给出的附件 3 数据进行预处理,去除了较多无关数据以及附件 3 中空缺数据。随之,我们建立了随机森林、逻辑回归、LGBM 回归等数学模型,运用机器学习算法来衡量训练集准确度和测试集准确度以及平均绝对误差进行模型评估,从飞行员训练分数和交叉验证的评估方法来分析飞行员的飞行技术。
针对问题五的分析
对于问题五的分析,我们根据问题一的飞行安全相关的部分关键数据项,问题二的重着陆分析,问题三的不同超限情况的分析,问题四的飞行技术评估,设计了一种基于时间记忆增强模型的预警机制。通过大量的数据训练和测试,该方法对学习行为特征的分析有效,具有较强的有效性和可靠性。其次,挖掘和预测决策和干预机制。本研究分析了三种密度的特征,计算特征之间的相关性,将强相关系数≥0.85的特征聚类。当一个聚类中的特征数量超过总特征的60%时,该数据子集被标记为典型,否则被定义为非典型。选取三种临近最优算法进行对比实验,分别是:(1)将原始行为与递归神经网络(OB + RNN)相结合,(2)基于总频率行为和递归神经网络(TF + RNN)的预警算法,(3)基于LSTM-Autoencoder和注意机制(LA + AM)的预警算法。
模型的建立与求解整体论文缩略图


全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
程序代码:(代码和文档not free)
import numpy
import pandas
from spsspro.algorithm import statistical_model_analysis
#生成案例数据
data_x1 = pandas.DataFrame({
"A": numpy.random.random(size=100),
"B": numpy.random.random(size=100)
} 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1325
1325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









