










你不干有的是人干
- 参考文献
- 背景
- 开源的2d视觉跟踪算法有哪些?
- 如何用YOLO v5实现目标跟踪?
- 小白学习YOLO算法,应该先学哪个版本?
- 基础
- 文档
- 用官方支持的数据集(如COCO)重新训练YOLO
- 用自己的数据集训练YOLO
- 部署
- 实践
- 常见疑问(FAQ)
- 如何用pip安装YOLO?
- 如何用conda安装YOLO?
- 使用Docker运行YOLO的优势?
- [如何 git clone YOLO仓库?](https://docs.ultralytics.com/quickstart/#how-do-i-clone-the-ultralytics-repository-for-development)
- YOLO11n,YOLO11s,YOLO11m,YOLO11l,YOLO11x的区别是什么?
- [如何在自定义数据集上训练YOLO11 模型?](https://docs.ultralytics.com/zh/tasks/detect/#how-do-i-train-a-yolo11-model-on-my-custom-dataset)
- [如何验证经过训练的YOLO 模型的准确性?](https://docs.ultralytics.com/zh/tasks/detect/#how-can-i-validate-the-accuracy-of-my-trained-yolo-model)
- [YOLO11 模型可以导出成什么格式?](https://docs.ultralytics.com/zh/tasks/detect/#what-formats-can-i-export-a-yolo11-model-to)
参考文献
【1】https://yiyan.baidu.com
【2】https://docs.ultralytics.com/zh#where-to-start
【3】https://blog.csdn.net/gma999/article/details/144694729
背景
在云端部署ViSP,ViSP实现视觉伺服、yolo实现视觉跟踪。
开源的2d视觉跟踪算法有哪些?
开源的2D视觉跟踪算法有很多呢,这里给你推荐一些比较知名和常用的吧。
- ByteTrackV2:这是一个通用2D跟踪算法,提出了分层的数据关联策略来寻找低分检测框中的真实目标,缓解了目标丢失和轨迹不连续的问题。它在MOT(多目标跟踪)任务中表现优秀,适用于各种检测器,并且源码是公开的哦,可以在这个链接找到。
- SORT:这是一种在线实时多目标跟踪算法,以IOU作为前后图像目标关系度量指标,利用卡尔曼滤波器预测当前位置,通过匈牙利算法关联检测目标。它的实现相对简单,且跟踪效果良好。
- DeepSORT:这是SORT算法的改进版,加入了深度学习特征提取和在线更新机制,提高了跟踪的稳定性和准确性。
- CSK:这是首次向世人展示相关滤波潜力的算法,在跟踪速度和精度上取得了很好的平衡,虽然年代稍显久远,但依然是学习相关滤波跟踪算法的经典之作。
此外,MeanShift、CamShift、KCF、MOSSE、TLD、MIL、Struck、CT、ASLA、SCM等也都是比较知名的开源2D视觉跟踪算法哦。这些算法各有优缺点,适用于不同的场景和需求,你可以根据自己的实际情况选择合适的算法进行学习和应用。
如何用YOLO v5实现目标跟踪?
使用YOLOv5实现目标跟踪通常涉及两个主要步骤:首先,使用YOLOv5进行目标检测以获取每一帧中的目标位置和类别;其次,利用这些检测结果在连续帧之间关联或跟踪目标。YOLOv5本身是一个目标检测模型,并不直接提供目标跟踪功能,但你可以结合其他技术或算法来实现跟踪。
以下是一个基本的流程,说明如何使用YOLOv5和其他方法实现目标跟踪:
-
安装YOLOv5:
首先,你需要安装YOLOv5及其依赖项。这通常包括Python、PyTorch以及其他一些库。你可以从YOLOv5的GitHub仓库克隆代码并按照提供的指南进行安装。 -
准备数据集:
如果你有自己的数据集,需要确保它符合YOLOv5的格式,并进行必要的预处理。 -
训练或加载YOLOv5模型:
你可以使用预训练的YOLOv5模型,也可以根据自己的数据集进行训练。预训练模型通常可以在YOLOv5的GitHub仓库中找到。 -
目标检测:
使用YOLOv5模型对视频帧进行目标检测。这将返回每一帧中目标的边界框、类别和置信度。 -
目标跟踪:
目标跟踪算法有很多,如SORT、DeepSORT、ByteTrack等。你可以选择一个适合你的应用场景的跟踪算法,并使用YOLOv5的检测结果作为输入。例如,使用DeepSORT时,你需要提取检测到的目标的特征(通常使用深度学习模型),然后使用这些特征在连续帧之间关联目标。DeepSORT使用卡尔曼滤波器来预测目标的位置,并使用匈牙利算法来匹配检测到的目标和预测的目标。
-
后处理:
跟踪算法可能会产生一些噪声或错误的跟踪结果。你可以通过后处理步骤来清理这些结果,如删除置信度较低的跟踪、合并重叠的跟踪等。 -
可视化:
最后,你可以将跟踪结果可视化,将跟踪的目标在视频帧中用边界框标记出来。
需要注意的是,目标跟踪是一个复杂的问题,特别是当场景中存在多个相似目标、目标遮挡或快速移动时。因此,实现一个鲁棒的目标跟踪系统可能需要大量的调试和优化工作。
此外,还有一些开源的项目将YOLOv5与其他跟踪算法结合起来,提供了一个完整的跟踪解决方案。你可以搜索这些项目,看看它们是如何实现目标跟踪的,并考虑在你的项目中使用它们。
小白学习YOLO算法,应该先学哪个版本?
对于小白来说,学习YOLO算法时,选择哪个版本主要取决于个人的学习目标、时间投入以及资源获取情况。不过,一般来说,从较新的版本开始学习可能更有助于了解YOLO算法的最新进展和优化。但是,考虑到新版本的算法可能包含了更多的复杂性和技术细节,这可能会增加学习难度。
因此,对于初学者来说,YOLOv5可能是一个相对合适的选择。以下是几个推荐YOLOv5作为入门版本的理由:
-
文档和社区支持:YOLOv5拥有较为完善的文档和活跃的社区支持,这有助于初学者在遇到问题时快速找到解决方案。
-
易用性和灵活性:YOLOv5相对容易上手,同时提供了多种配置选项,可以根据实际需求调整模型的复杂度和检测速度。
-
性能表现:YOLOv5在多个公开数据集上表现优异,能够满足大多数应用场景的需求。
-
开源和可定制性:YOLOv5是开源的,这意味着初学者可以自由地下载、修改和扩展代码,以满足特定的应用需求。
当然,在学习YOLOv5的基础上,随着对算法理解的加深,可以逐渐过渡到更高版本的YOLO算法(如YOLOv7、YOLOv8或YOLOv11),以了解最新的技术进展和优化方法。
在学习过程中,建议遵循以下步骤:
-
阅读文档:首先阅读YOLOv5的官方文档,了解算法的基本原理、网络结构、训练方法和测试流程。
-
动手实践:通过编写代码来实践所学知识。可以从简单的示例开始,逐步增加难度和复杂性。
-
参与社区:加入YOLO算法的社区或论坛,与其他学习者交流心得和经验,共同解决问题。
-
持续学习:随着技术的不断发展,YOLO算法也在不断更新和优化。因此,建议持续关注YOLO算法的最新进展,以保持学习的连贯性和前沿性。
基础
https://docs.ultralytics.com/zh#where-to-start
一、版本
参考:https://docs.ultralytics.com/#yolo-a-brief-history
- YOLOv2 2016 年发布,通过纳入批量归一化、锚框和维度集群改进了原始模型。
- YOLOv3 2018 年推出的,使用更高效的骨干网络、多锚和空间金字塔池进一步增强了模型的性能。
- YOLOv4 于 2020 年发布,引入了 Mosaic数据增强、新的无锚检测头和新的损失函数等创新技术。
- YOLOv5 进一步提高了模型的性能,并增加了超参数优化、集成实验跟踪和自动导出为常用导出格式等新功能。
- YOLOv6 于 2022 年由美团开源,目前已用于该公司的许多自主配送机器人。
- YOLOv7 增加了额外的任务,如 COCO 关键点数据集的姿势估计。
- YOLOv8 Ultralytics YOLOv8 引入了新的功能和改进,以提高性能、灵活性和效率,支持全方位的视觉人工智能任务、
- YOLOv9 引入了可编程梯度信息 (PGI) 和广义高效层聚合网络 (GELAN) 等创新方法。
- YOLOv10 是由清华大学的研究人员使用该软件包创建的。 UltralyticsPython 软件包创建的。该版本通过引入端到端头(End-to-End head),消除了非最大抑制(NMS)要求,实现了实时目标检测的进步。
- YOLO11 由 Ultralytics 团队开发。Ultralytics YOLO 可实现检测、分割、姿势估计、跟踪和分类等多项任务中提供最先进的 (SOTA) 性能,充分利用各种人工智能应用和领域的能力。
二、安装
方式:pip、 conda、Docke、github
参考:Install Ultralytics
三、运行方式
-
在命令窗口中使用CLI运行YOLO
CLI:YOLO command line interface
例如:yolo TASK MODE ARGS Where TASK (optional) is one of [detect, segment, classify, pose, obb] MODE (required) is one of [train, val, predict, export, track, benchmark] ARGS (optional) are any number of custom 'arg=value' pairs like 'imgsz=320' that override defaults. -
在python脚本中调用YOLO
from ultralytics import YOLO # Create a new YOLO model from scratch model = YOLO("yolo11n.yaml") # Load a pretrained YOLO model (recommended for training) model = YOLO("yolo11n.pt") # Train the model using the 'coco8.yaml' dataset for 3 epochs results = model.train(data="coco8.yaml", epochs=3) # Evaluate the model's performance on the validation set results = model.val() # Perform object detection on an image using the model results = model("https://ultralytics.com/images/bus.jpg") # Export the model to ONNX format success = model.export(format="onnx")
四、一些概念(YOLO v11 为例)
参考:https://docs.ultralytics.com/quickstart
Ultralytics
Ultralytics 是 YOLO 的创始团队。
Modes
- Train mode
使用数据集训练YOLO;
支持公开数据集如coco(训练时自动下载到本地)。
支持自定义数据集(需要提前准备好数据集、格式、标注)。- 在预训练模型上用自定义数据集训练模型;
- 新建一个空白模型用于训练自定义数据集;
- Val mode
用于在训练后验证YOLO模型;
模型在验证集上进行评估;
此模式可用于调整模型的超参数以提高其性能;
输入:已标注的数据集。
可计算交并比IoU. - Predict mode
使用训练好的YOLO模型对新数据(图像或视频)进行预测、推理、检测;
输入:未经标注的新数据
Predict mode和Val mode的最大区别是,Val mode的输入数据必须经过标注,可算IoU,但是Predict mode的输入数据是为未标注的,不可算IoU,仅可得到检测的精度(概率)。 - Export mode
用于将YOLO模型导出为可用于部署的格式; - Track mode
用于使用YOLO11模型实时跟踪对象;
适用于监控系统或自动驾驶汽车等应用;
输入:checkpoint file; - Benchmark mode
基准模式
用于分析YOLO11各种导出格式的速度和准确性。基准测试提供了有关导出格式的大小、其mAP50-95指标(用于对象检测、分割和姿态)或accuracy_top5指标(用于分类)的信息,以及ONNX、OpenVINO、TensorRT等各种格式的每张图像的推理时间(毫秒)。这些信息可以帮助用户根据他们对速度和准确性的要求,为他们的特定用例选择最佳的导出格式。
Tasks
YOLO11 支持以下机器视觉任务:
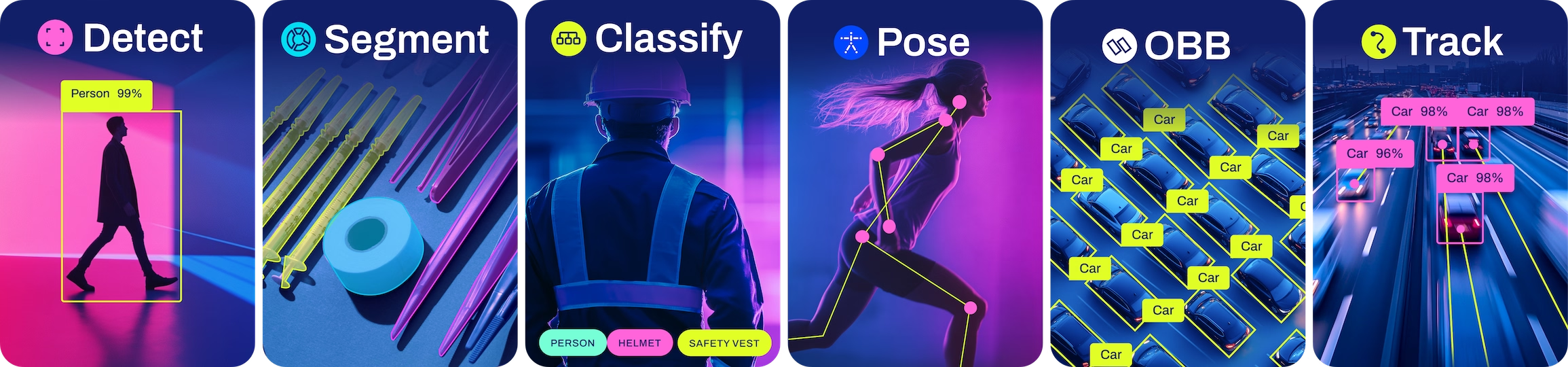
目标检测 Detect
目标分割 Segment
目标分类 Classify
目标姿态估计 Pose
目标边框回归 OBB
参考:https://docs.ultralytics.com/tasks
Models
参考:https://docs.ultralytics.com/models
支持的DNN网络模型。
模型即网络结构。
不同模型的性能对比:
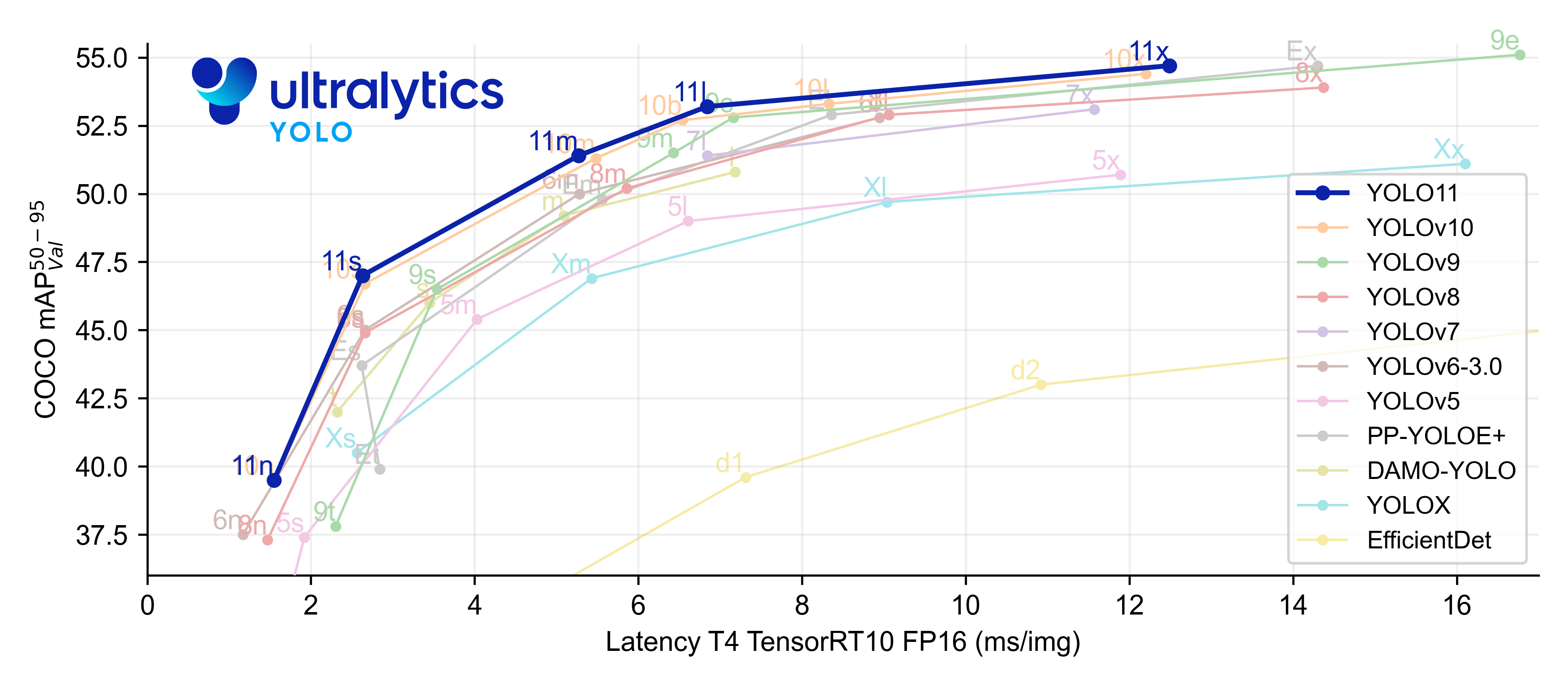
目前支持的模型:
- YOLOv3
- YOLOv4
- YOLOv5
- YOLOv6
- YOLOv7
- YOLOv8
- YOLOv9
- YOLOv10
- YOLO11 🚀 NEW
- SAM (Segment Anything Model)
- SAM 2 (Segment Anything Model 2)
- MobileSAM (Mobile Segment Anything Model)
- FastSAM (Fast Segment Anything Model)
- YOLO-NAS (Neural Architecture Search)
- RT-DETR (Realtime Detection Transformer)
- YOLO-World (Real-Time Open-Vocabulary Object Detection)
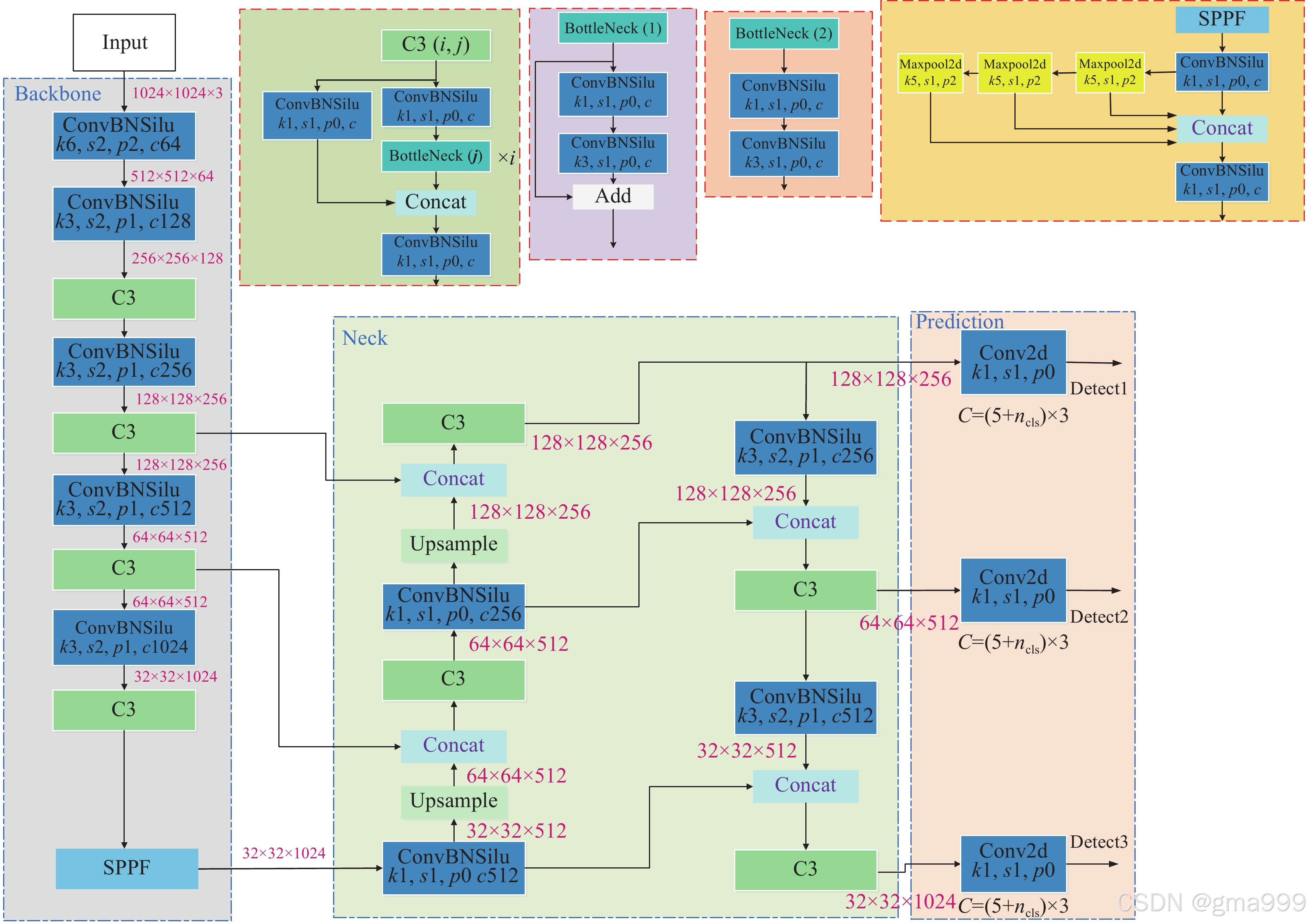
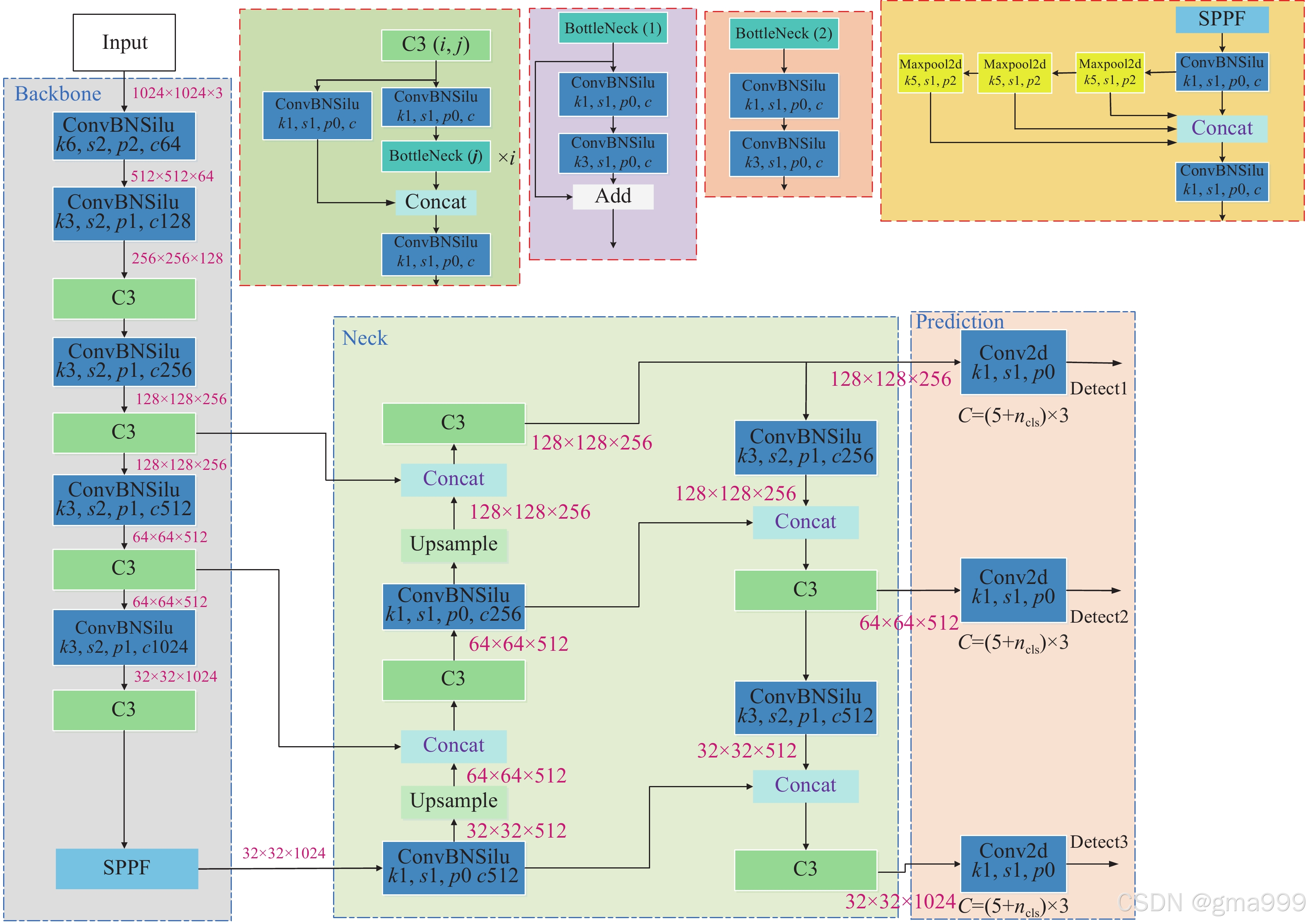
YOLOv5的网络结构:
数据集
参考:https://docs.ultralytics.com/datasets
官方提供的公开数据集;
用官方提供的公开数据集训练模型时,数据集会自动下载。
如何手动下载这些公开数据集到本地计算机?
Based on the documentation, there are two main ways to download datasets:
- Through Ultralytics HUB:
- Navigate to the Dataset page of the dataset you want to download
- Open the dataset actions dropdown and click on the “Download” option (1)
- Using the Ultralytics SDK:
from ultralytics import YOLO
from ultralytics.hub import Datasets
# Initialize dataset client
dataset = Datasets()
# Get download link
download_link = dataset.get_download_link()
Note: Some datasets like xView require manual downloading from their respective websites due to licensing requirements (3) .
The downloaded datasets should follow this structure:
dataset/
├── train/
│ ├── images/
│ └── labels/
└── val/
├── images/
└── labels/
(4) https://docs.ultralytics.com/datasets
回调函数
Ultralytics YOLO11支持运行用户的回调函数,在训练、验证、导出和预测模式模式下都可以调用回调函。
例如,在predict模式运行结束后调用一个用户回调函数:
from ultralytics import YOLO
def on_predict_batch_end(predictor):
"""Handle prediction batch end by combining results with corresponding frames; modifies predictor results."""
_, image, _, _ = predictor.batch
# Ensure that image is a list
image = image if isinstance(image, list) else [image]
# Combine the prediction results with the corresponding frames
predictor.results = zip(predictor.results, image)
# Create a YOLO model instance
model = YOLO("yolo11n.pt")
# Add the custom callback to the model
model.add_callback("on_predict_batch_end", on_predict_batch_end)
# Iterate through the results and frames
for result, frame in model.predict(): # or model.track()
pass
所有支持的回调函数请参考这里。
Configuration
设置(settings )
超参数(hyperparameters )
YOLO设置和超参数在模型的性能、速度和准确性中起着至关重要的作用。
(一)语法
- CLI
yolo TASK MODE ARGS - python
from ultralytics import YOLO # Load a YOLO11 model from a pre-trained weights file model = YOLO("yolo11n.pt") # Run MODE mode using the custom arguments ARGS (guess TASK) model.MODE(ARGS)
(一)参数
- Train Settings
详细参考此处。
影响范围:training process
重要参数如:- batch size
- learning rate
- momentum
- weight decay
- optimizer
- loss function
- training dataset
- …
- Predict Settings
详细参考此处。
影响范围:new data
调整和实验这些设置对于实现最佳性能至关重要。
重要参数如:- 数据源(source)
- 置信阈值(confidence threshold)
- 非最大抑制阈值(Non-Maximum Suppression threshold,NMS)
- 类别数量(number of classes)
- 输入数据大小和格式( input data size and format)
- Visualization 参数(例如是否在窗口中显示带注释的图像或视频)
- …
- Validation Settings
详细参考此处。
影响范围:validation dataset
重要参数如:
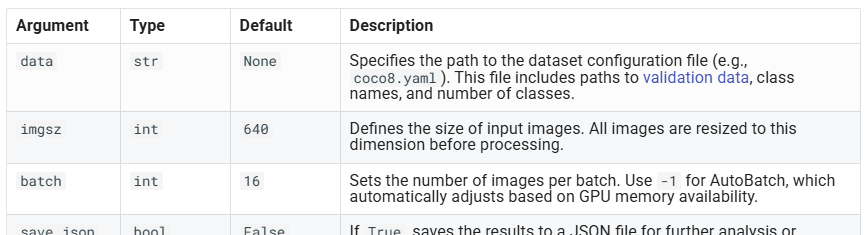
- Export Settings
YOLO模型的导出设置包括与保存或导出模型以在不同环境或平台中使用相关的配置和选项。这些设置可能会影响模型的性能、大小以及与各种系统的兼容性。
详细参考此处。
重要参数如:- 模型格式
与部署的软件环境有关- onnx
- torchscript
- tensorflow
- others
- device
与部署的硬件平台有关- GPU (device=0),
- CPU (device=cpu),
- MPS for Apple silicon (device=mps)
- DLA for NVIDIA Jetson (device=dla:0 or device=dla:1).

- 模型格式
- Solutions Settings
针对不同的Solutions的参数。
针对不同的tasks的参数,如object counting, heatmap creation, workout tracking, data analysis, zone tracking, queue management, and region-based counting。
参考这里。

- Augmentation Settings
提高YOLO模型的鲁棒性和泛化能力的相关参数。
参考:augmentation-settings - Logging, Checkpoints and Plotting Settings
参考:logging-checkpoints-and-plotting-settings
Solutions
参考:https://docs.ultralytics.com/solutions/#solutions
例如:
- 目标检测
- 区域跟踪
- 距离计算
- …
集成、Integrations
参考:https://docs.ultralytics.com/integrations
与第三方软件、框架、应用的集成。
包括:
- Datasets Integrations
如:使用深度学习标注工具Roboflow为数据集标注。 - Training Integrations
如:YOLO 的 VS Code 扩展程序。 - Deployment Integrations
如ONNX、TensorRT、TorchScrip等。 - Export Formats
如:PyTorch、ONNX、TensorRT、TF GraphDef等。
网络结构
与模型概念相似。
训练完成的模型 = 结构参数 + 权重参数 + labels 参数
以 ONNX 格式为例:yolov5n.onnx、coco_classes.txt
模型结构(网络结构):
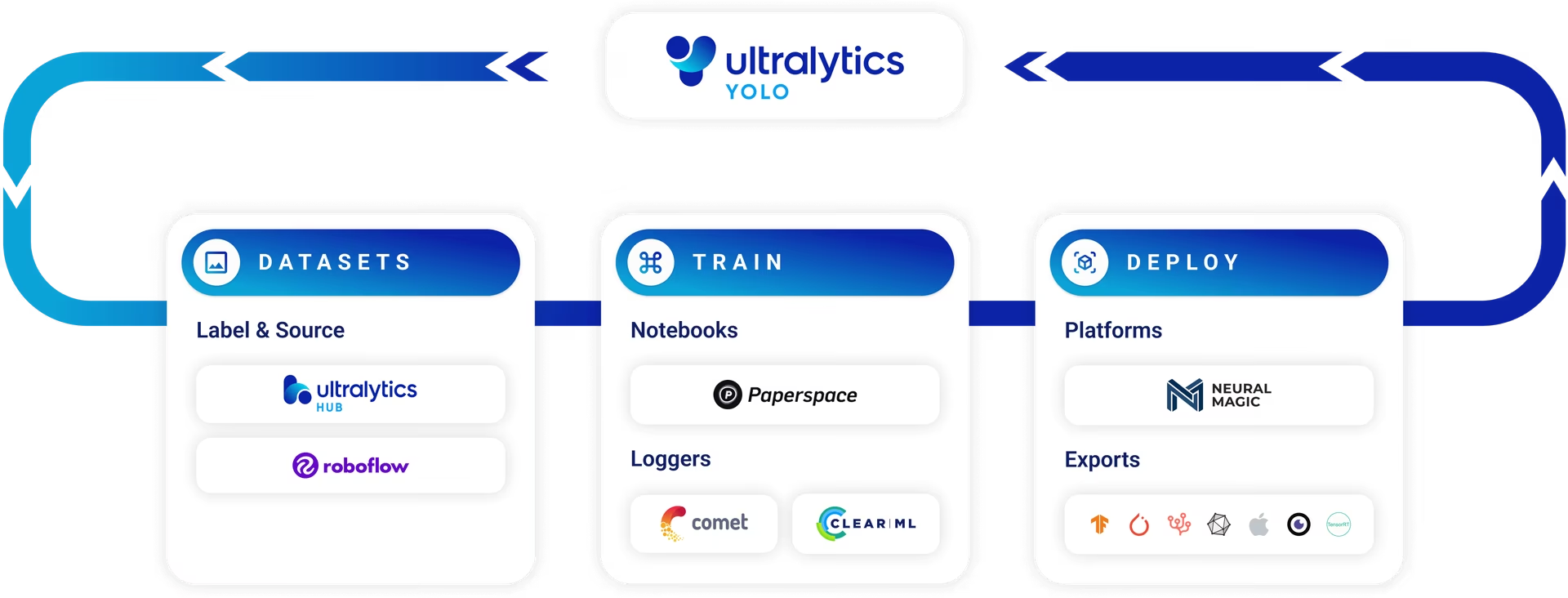
Ultralytics HUB
Ultralytics HUB 是一个直观的、可视化的、无需代码的、允许用户快速上传他们的数据集并训练YOLO 模型的在线网页,是一个在线训练工具。它还提供了一系列预先训练的模型供用户选择,使用户非常容易上手。
Ultralytics HUB的功能:
- 用户友好界面、无需编码。
- 提供免费的公共数据集,如:
- 提供预训练模型(各种格式以供下载)。
- 云训练(上传自己的数据集,然后云训练)。
- 下载训练之后的模型。
- 云部署(可以将训练完的模型部署到Ultralytics HUB提供的云端服务器上)。
- 移动端部署(仅IOS、Android)。
HUB可以将训练完的(云训练或本地训练)模型生成一个app,以供IOS、Android端下载和安装。 - 团队协作:通过团队功能与您的团队高效协作。
部署
部署即deploy。
https://docs.ultralytics.com/zh/guides/model-deployment-practices/
.yaml文件
.yaml文件是一种使用YAML(YAML Ain’t Markup Language)语言编写的文件,YAML是一种直观、简洁且易于人类阅读的数据序列化格式。它最初设计的目的是提供一种易于书写和阅读的文件格式,常用于配置文件、数据存储和交换。YAML文件通常以“.yaml”或“.yml”为扩展名。
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco8 # dataset root dir
train: images/train # train images (relative to 'path') 4 images
val: images/val # val images (relative to 'path') 4 images
test: # test images (optional)
# Classes (80 COCO classes)
names:
0: person
1: bicycle
2: car
# ...
77: teddy bear
78: hair drier
79: toothbrush
交并比IoU
IoU,全称Intersection over Union,即交并比,是目标检测中使用的一个概念,用来衡量预测框和真实框的重叠程度。它是预测框(Predicted Bounding Box)和真实框(Ground Truth Bounding Box)的交集面积与并集面积的比值。具体来说,IoU的计算公式为:
IoU = 交集面积 / 并集面积
这个指标在目标检测领域中非常重要,因为它可以直观地反映预测框的定位准确性。IoU的值域为[0,1],当两个框完全重合时,IoU值为1;当两个框没有交集时,IoU值为0。在目标检测的训练和评估过程中,通常会设定一个IoU阈值,只有当预测框与真实框的IoU大于这个阈值时,才认为检测是正确的。
YOLO11 模型验证有哪些指标?
YOLO11 模型验证为评估模型性能提供了几个关键指标。这些指标包括
mAP50(IoU 阈值为 0.5 时的平均精度平均值)
mAP75(在 IoU 临界值为 0.75 时的平均平均精度)
mAP50-95(从 0.5 到 0.95 的多个 IoU 阈值的平均精度平均值)
文档
一、Quickstart
参考:https://docs.ultralytics.com/quickstart
二、Guides
参考:https://docs.ultralytics.com/guides
- Model Deployment Options
- Raspberry Pi
- NVIDIA Jetson
- Conda Quickstart
- ROS Quickstart
- YOLOv5 Quickstart
- 如何部署?
- …
三、参考手册
参考:Reference
ultralytics/cfg/init.py
ultralytics/data/build.py
ultralytics/engine/model.py
ultralytics/models/yolo/classify/train.py
ultralytics/models/yolo/detect/predict.py
ultralytics/nn/tasks.py
ultralytics/utils/loss.py
ultralytics/utils/plotting.py
…
用官方支持的数据集(如COCO)重新训练YOLO
- 使用公开数据集训练YOLO时,数据集会在第一次运行训练时自动下载到本地。
- 步骤
用自己的数据集训练YOLO
-
一、使用Ultralytics HUB云训练。
-
二、本地训练
参考:how-do-i-train-a-yolo11-model-on-my-custom-dataset
How can I train a YOLOv8 model on custom data?
yolo train model=yolov8n.pt data='custom_data.yaml' epochs=100 imgsz=640
How do I train a YOLO11 model for object detection?
yolo train model=yolo11n.pt data=coco8.yaml epochs=100 imgsz=640 -
准备数据(3要素):
- xx.yaml
- 数据集
- 标签
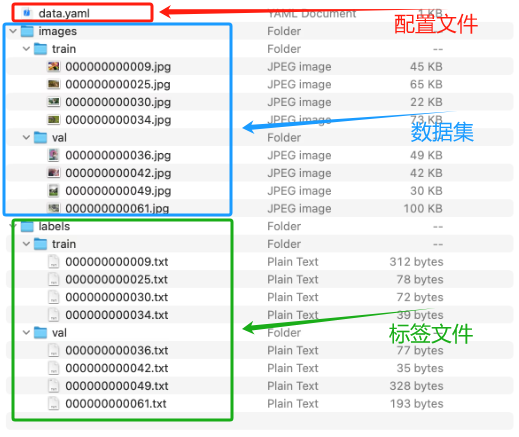
-
要点:
- 参考:https://docs.ultralytics.com/zh/datasets/detect/
- 每个
xx.jpg对应一个xx.txt。 xx.txt是标签文件包含了类别、中心坐标、边框尺寸信息。- 对于 detect 问题
xx.txt中列的含义是:class,x,y,w,h。
其中:
class 是类别;
x,y 分别是目标中心的x,y坐标的归一值;
w,h 分别是目标边框宽、高的归一值;
例如:

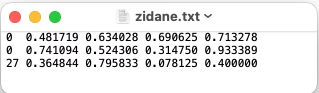
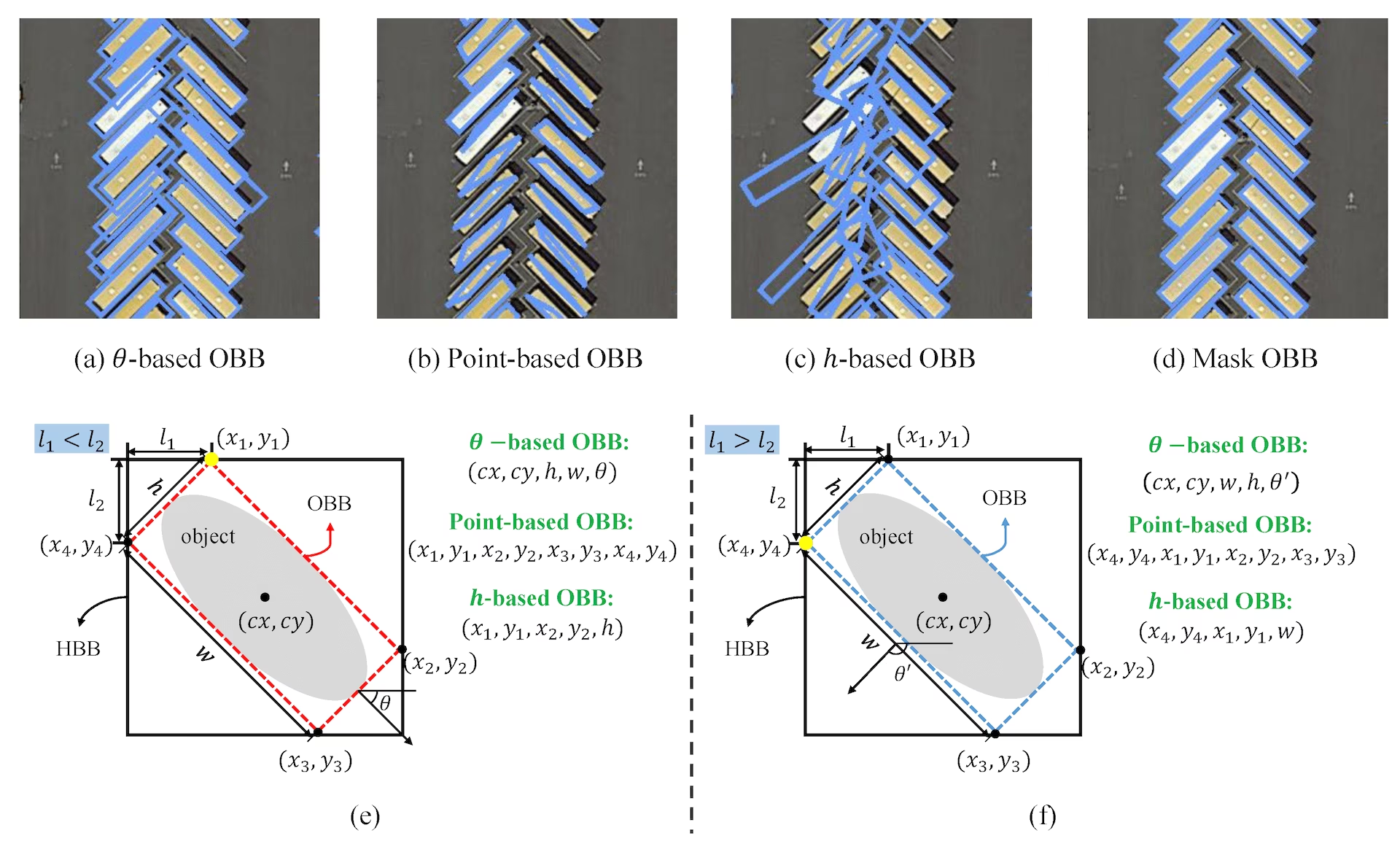
对于 OBB 问题:数据集格式
通过四个角点指定边界框,其坐标在 0 和 1 之间归一化:
class_index x1 y1 x2 y2 x3 y3 x4 y4
例如:0 0.780811 0.743961 0.782371 0.74686 0.777691 0.752174 0.776131 0.749758
- 需不需要调整数据集图像尺寸到统一尺寸?
不需要,train 的参数 imgsz:所有图像在输入模型前都会被调整到这一尺寸。影响模型精度和计算复杂度。
-
目录结构
data
xxx.yaml
images
train
val
labels
train
val

-
数据集标注工具
| 工具名称 | 平台 | 特点 | 适合场景 |
|---|---|---|---|
| LabelImg | 跨平台 | 简单易用,支持YOLO格式 | 初学者、小型项目 |
| LabelMe | 跨平台 | 功能强大,支持多种标注类型 | 复杂标注任务 |
| CVAT | 在线/本地 | 团队协作,支持多种标注类型 | 大规模标注任务 |
| Roboflow | 在线 | 自动标注、数据增强、团队协作 | 快速标注和数据集管理 |
| VIA | 浏览器 | 无需安装,支持多种标注类型 | 小型项目 |
| MakeSense | 浏览器 | 免费、简单易用 | 小型项目 |
| YOLO Mark | 本地 | 专为YOLO设计 | YOLO用户 |
| SuperAnnotate | 在线 | 功能强大,支持团队协作 | 大规模标注任务 |
| RectLabel | macOS | macOS平台专用 | macOS用户 |
| 自定义脚本 | 本地 | 灵活,适合已有标注数据的转换 | 数据格式转换 |
xx.yaml格式
以 datasets/coco8.yaml 为例:# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..] path: ../datasets/coco8 # dataset root dir train: images/train # train images (relative to 'path') 4 images val: images/val # val images (relative to 'path') 4 images test: # test images (optional) # Classes (80 COCO classes) names: 0: person 1: bicycle 2: car # ... 77: teddy bear 78: hair drier 79: toothbrush
部署
部署训练完成的模型。
deploy即部署。
https://docs.ultralytics.com/datasets
训练完成的模型 = 结构参数 + 权重参数 + labels 参数
以 ONNX 格式为例:yolov5n.onnx、coco_classes.txt
模型结构(网络结构):
几种部署方式:
参考:https://docs.ultralytics.com/zh/guides/model-deployment-practices/
- 云端部署
- 边缘部署: 移动端部署,如部署在手机、平板。
- 本地部署: 常用于数据保密、不可联网场景。
Example Deployment Steps
For AWS deployment, here are the basic steps (2) :
git clone https://github.com/ultralytics/yolov5 # clone repository
cd yolov5
pip install -r requirements.txt # install dependencies
After setup, you can train, validate, and perform inference:
# Train a model on your data
python train.py
# Validate the trained model for Precision, Recall, and mAP
python val.py --weights yolov5s.pt
# Run inference using the trained model on your images or videos
python detect.py --weights yolov5s.pt --source path/to/images
# Export the trained model to other formats for deployment
python export.py --weights yolov5s.pt --include onnx coreml tflite
使用 OpenCV 和YOLO 读取视频帧进行推理:
import cv2
from ultralytics import YOLO
# Load the YOLO model
model = YOLO("yolo11n.pt")
# Open the video file
video_path = "path/to/your/video/file.mp4"
cap = cv2.VideoCapture(video_path)
# Loop through the video frames
while cap.isOpened():
# Read a frame from the video
success, frame = cap.read()
if success:
# Run YOLO inference on the frame
results = model(frame)
# Visualize the results on the frame
annotated_frame = results[0].plot()
# Display the annotated frame
cv2.imshow("YOLO Inference", annotated_frame)
# Break the loop if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
# Break the loop if the end of the video is reached
break
# Release the video capture object and close the display window
cap.release()
cv2.destroyAllWindows()
部署环境:
根据环境,几种常见的部署方式:
1. 在支持NVIDIA GPU的系统上部署
- 环境配置:需要安装CUDA工具包(如CUDA 11.8)和TensorRT(如TensorRT 8.6.1.6)以加速推理过程。同时,还需要配置OpenCV用于图像和视频处理。
- 软件依赖:包括各种库文件和依赖项,如cudnn、cublas、cuda、cudadevrt、cudart等CUDA库,以及TensorRT的nvinfer、nvinfer_plugin、nvonnxparser等库。
- 部署步骤:通常涉及将YOLO V11模型导出为ONNX格式,然后使用TensorRT进行优化和部署。这包括设置包含目录和库目录,以及验证所有依赖项是否正确安装。
2. 使用PyTorch环境部署
- 环境安装:通过PyTorch官网下载与CUDA版本兼容的PyTorch安装包,并安装torch、torchvision和torchaudio等库。
- YOLO V11安装:使用如
pip install ultralytics等命令安装Ultralytics提供的YOLO库。 - 推理代码:编写Python代码来加载预训练的YOLO V11模型,并对输入图像进行推理。这通常涉及创建YOLO对象,加载模型权重,并使用
model.predict方法进行推理。
3. 一键部署方案
- 环境适应性:YOLO V11可以部署在多种环境中,包括边缘设备、云平台以及支持NVIDIA GPU的系统。
- 一键部署工具:有些教程或工具提供了一键部署YOLO V11的方案,这通常涉及克隆相关仓库、配置环境变量和依赖项,然后直接运行API地址进行模型推理。
- 多功能性:一键部署方案通常支持多种计算机视觉任务,如物体检测、实例分割、图像分类、姿态估计和定向物体检测等。
4. 在C#等其他编程语言中部署
- 模型转化:首先需要将YOLO V11模型转化为ONNX格式,以便在其他编程语言中使用。
- 环境配置:在C#等编程语言中,需要配置相应的ONNX运行时库,如OnnxRuntime。
- 部署代码:编写C#代码来加载ONNX模型,并对输入数据进行推理。这通常涉及加载模型、预处理输入数据、执行推理和后处理输出结果等步骤。
5. 在OpenCV中调用YOLO?在ViSP中调用YOLO?
待续…
6. ONNX模型及YOLO部署
训练完成之后的YOLO模型一般为yolo11n.pt格式,模型的官方使用方法为:
(1)安装依赖ultralytics包:pip install ultralytics
(2)在Linux的Python环境中运行:
model = YOLO("yolo11n.pt")
results = model("xxx.jpg")
可知,这样pt模型不便于平台的兼容性、移植性。
可将YOLO的官方模型(yolo11.pt 或 yolo11.yaml)转换为 ONNX 模型。
ONNX 是 Facebook 和Microsoft 最初开发的一个社区项目。该项目旨在创建一种开放文件格式,用于表示机器学习模型,使其能够在不同的人工智能框架和硬件中使用。ONNX 模型可用于在不同框架之间无缝转换。
ONNX 模型可与ONNX Runtime 配合使用。ONNX Runtime是机器学习模型的通用跨平台加速器,与PyTorch 等框架兼容、 TensorFlow、TFLite、scikit-learn 等框架兼容。ONNX 运行时(Runtime)通过利用特定硬件功能优化ONNX 模型的执行。通过这种优化,模型可以在各种硬件平台(包括 CPU、GPU 和专用加速器)上高效、高性能地运行。
参考:https://docs.ultralytics.com/zh/integrations/onnx/#onnx-and-onnx-runtime
待续…
实践
How to use YOLO11 to achieve target tracking?

安装
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm ~/miniconda3/miniconda.sh
在当前bash激活conda
source ~/miniconda3/bin/activate
conda create --name yolo11
conda activate yolo11
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda-repo-wsl-ubuntu-11-8-local_11.8.0-1_amd64.deb
sudo dpkg -i cuda-repo-wsl-ubuntu-11-8-local_11.8.0-1_amd64.deb
sudo cp /var/cuda-repo-wsl-ubuntu-11-8-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda
dpkg -l cuda
nvidia-smi
官网下载cudnn-local-repo-ubuntu2004-8.6.0.163_1.0-1_amd64.deb
sudo dpkg -i cudnn-local-repo-ubuntu2004-8.6.0.163_1.0-1_amd64.deb
sudo cp /var/cudnn-local-repo-ubuntu2004-8.6.0.163/cudnn-local-B0FE0A41-keyring.gpg /usr/share/keyrings/
sudo apt-get install libcudnn8=8.6.0.*-1+cuda11.8
sudo apt-get install libcudnn8-dev=8.6.0.*-1+cuda11.8
sudo apt-get install libcudnn8-samples=8.6.0.*-1+cuda11.8
conda install -c pytorch -c nvidia -c conda-forge pytorch torchvision pytorch-cuda=11.8 ultralytics
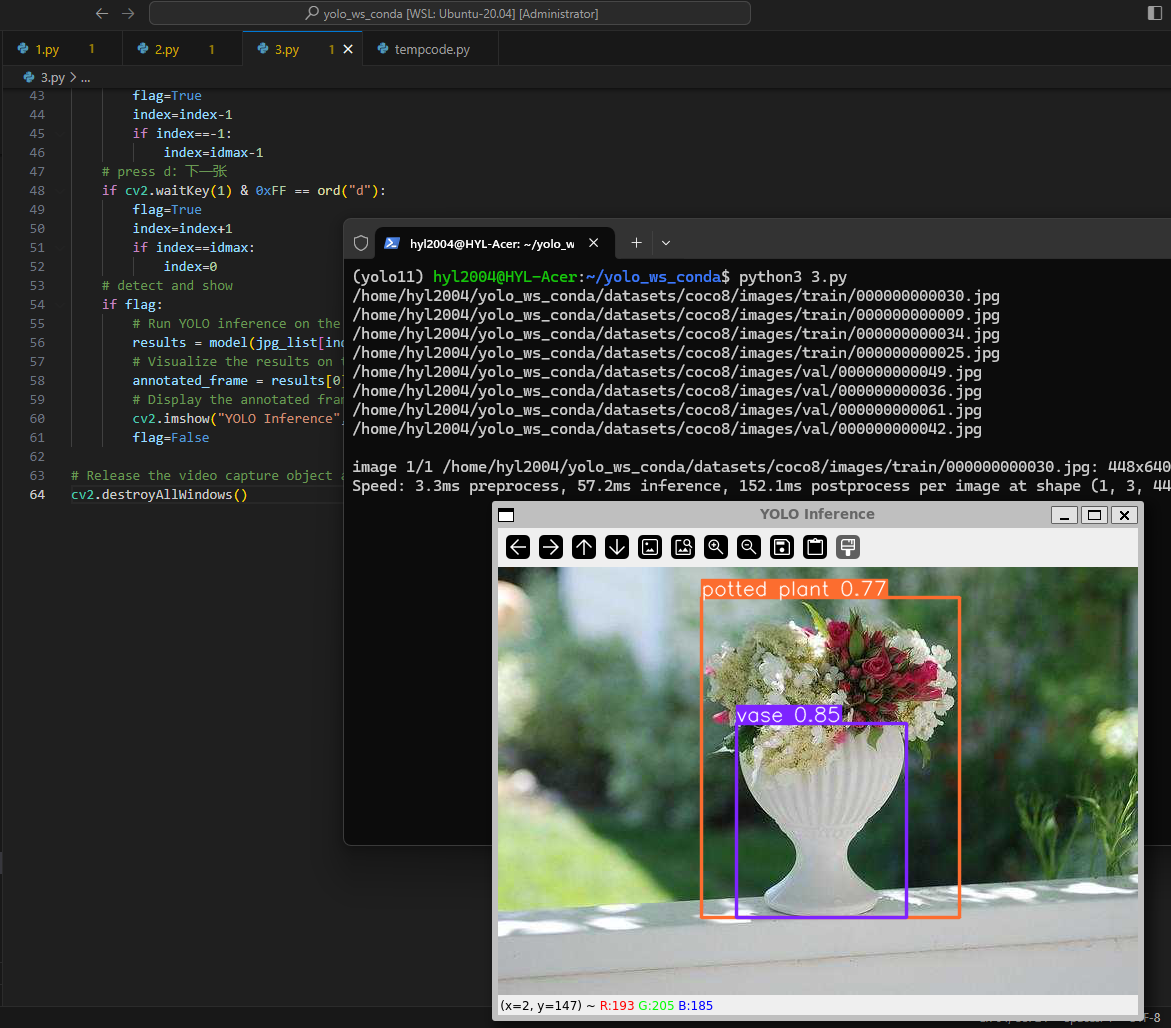
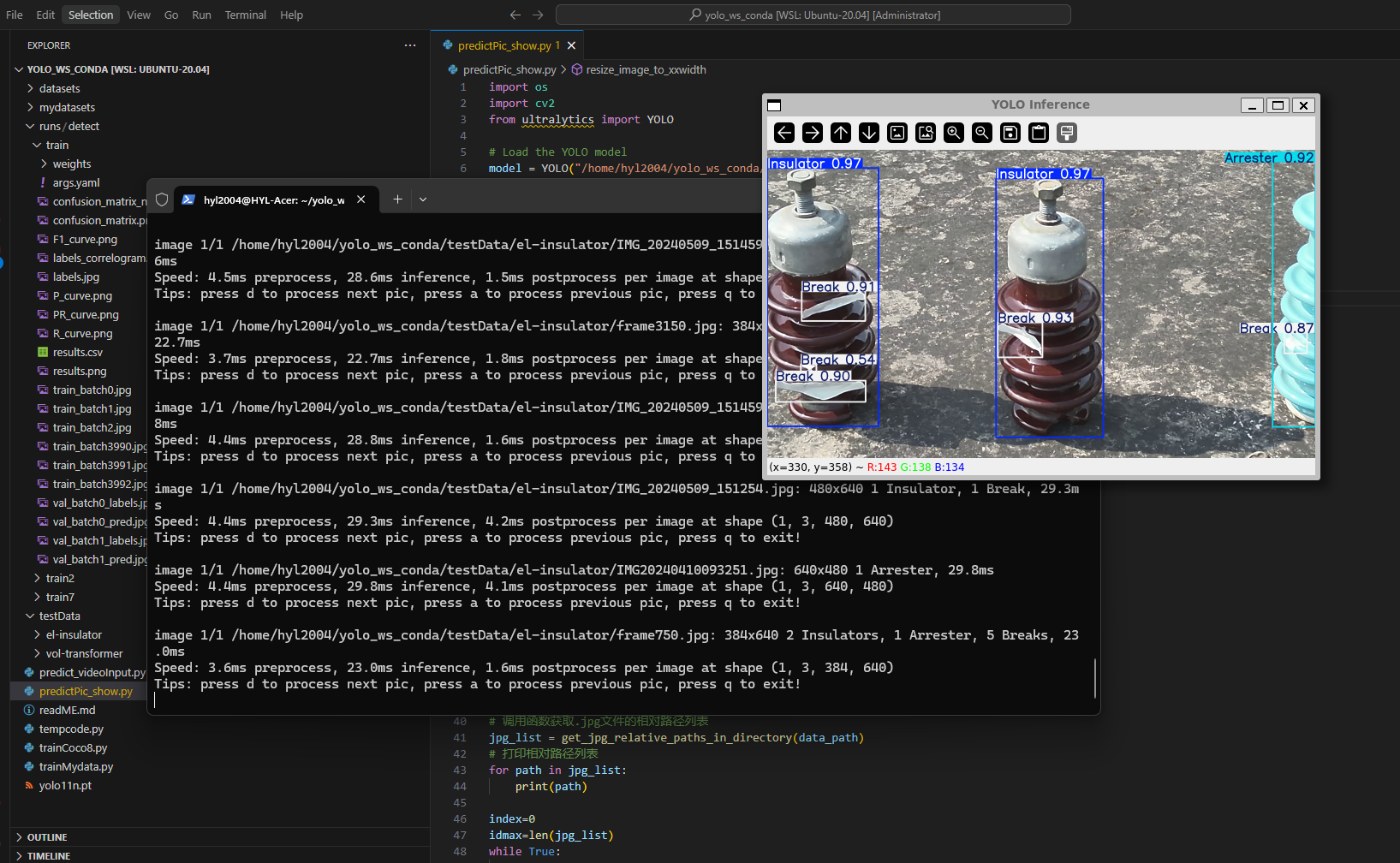
逐个检测并显示,按a/d键处理上/下一张pic(coco8)
import os
import cv2
from ultralytics import YOLO
# Load the YOLO model
# model = YOLO("/home/hyl2004/yolo_ws_conda/runs/detect/train7/weights/best.pt")
model = YOLO("yolo11n.pt")
flag = True
# 输入数据目录路径
# data_path = '/home/hyl2004/yolo_ws_conda/testData/vol-transformer'
data_path = '/home/hyl2004/yolo_ws_conda/testData/el-insulator'
# 调整图像尺寸,保持图像的宽高比
def resize_image_to_xxwidth(image, new_width):
# 获取原始图像的尺寸
original_height, original_width = image.shape[:2]
# 计算宽高比
aspect_ratio = original_width / original_height
# 根据宽高比计算新的高度
new_height = int(new_width / aspect_ratio)
# 使用cv2.resize()调整图像尺寸
resized_image = cv2.resize(image, (new_width, new_height), interpolation=cv2.INTER_AREA)
return resized_image
def get_jpg_relative_paths_in_directory(directory):
# 初始化一个空列表来保存相对路径
jpg_relative_paths = []
# 遍历指定目录下的所有文件和文件夹
for root, dirs, files in os.walk(directory):
# 遍历当前目录下的所有文件
for file in files:
# 检查文件扩展名是否为.jpg(不区分大小写)
if file.lower().endswith('.jpg'):
# 构建相对路径并添加到列表中
#print(root)
relative_path = os.path.join(root, file)
jpg_relative_paths.append(relative_path)
return jpg_relative_paths
# 调用函数获取.jpg文件的相对路径列表
jpg_list = get_jpg_relative_paths_in_directory(data_path)
# 打印相对路径列表
for path in jpg_list:
print(path)
index=0
idmax=len(jpg_list)
while True:
# Break the loop if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord("q"):
break
# press a:上一张
if cv2.waitKey(1) & 0xFF == ord("a"):
flag=True
index=index-1
if index==-1:
index=idmax-1
# press d:下一张
if cv2.waitKey(1) & 0xFF == ord("d"):
flag=True
index=index+1
if index==idmax:
index=0
# detect and show
if flag:
# Run YOLO inference on the frame
results = model(jpg_list[index])
# Visualize the results on the frame
annotated_frame = results[0].plot()
# Display the annotated frame
resized_image = resize_image_to_xxwidth(annotated_frame, 640)
cv2.imshow("YOLO Inference", resized_image)
flag=False
print("Tips: press d to process next pic, press a to process previous pic, press q to exit!")
# Release the video capture object and close the display window
cv2.destroyAllWindows()
变压器数据集训练
- 代码
import os
from ultralytics import YOLO
# Load a pretrained YOLO model (recommended for training)
model = YOLO("yolo11n.pt")
# Train the model using the 'coco8.yaml' dataset for 3 epochs
results = model.train(data="/home/hyl2004/yolo_ws_conda/dtv1/data.yaml", epochs=200, device=0)
# Evaluate the model's performance on the validation set
results = model.val()
# Export the model to ONNX format
success = model.export(format="onnx")
- 结果

- 数据集下载
江波龙移动硬盘 - 文件
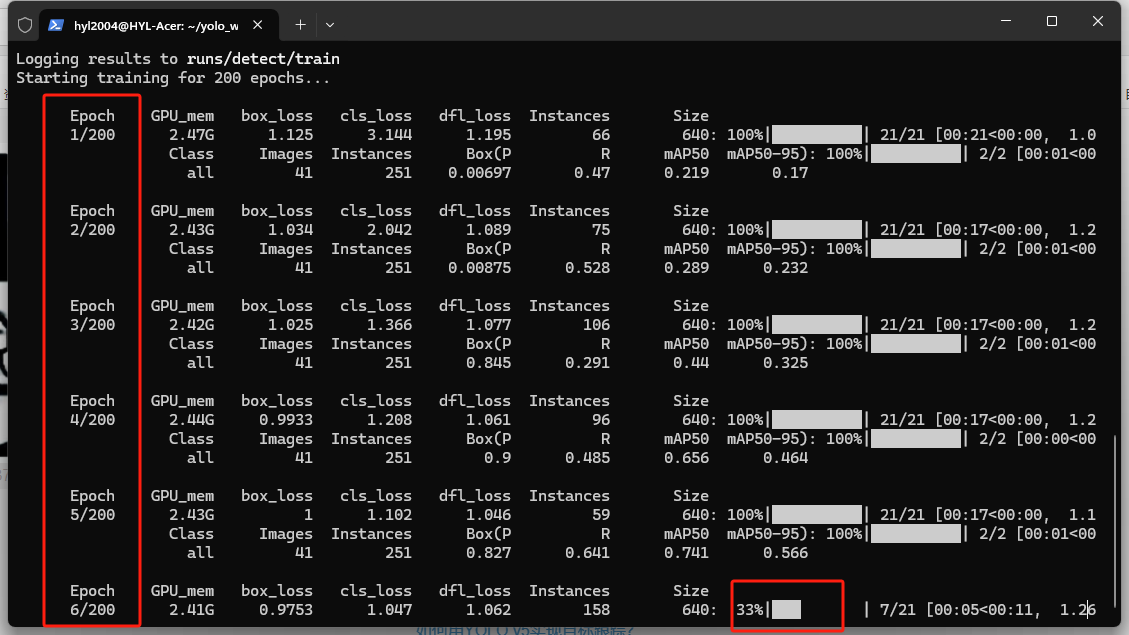
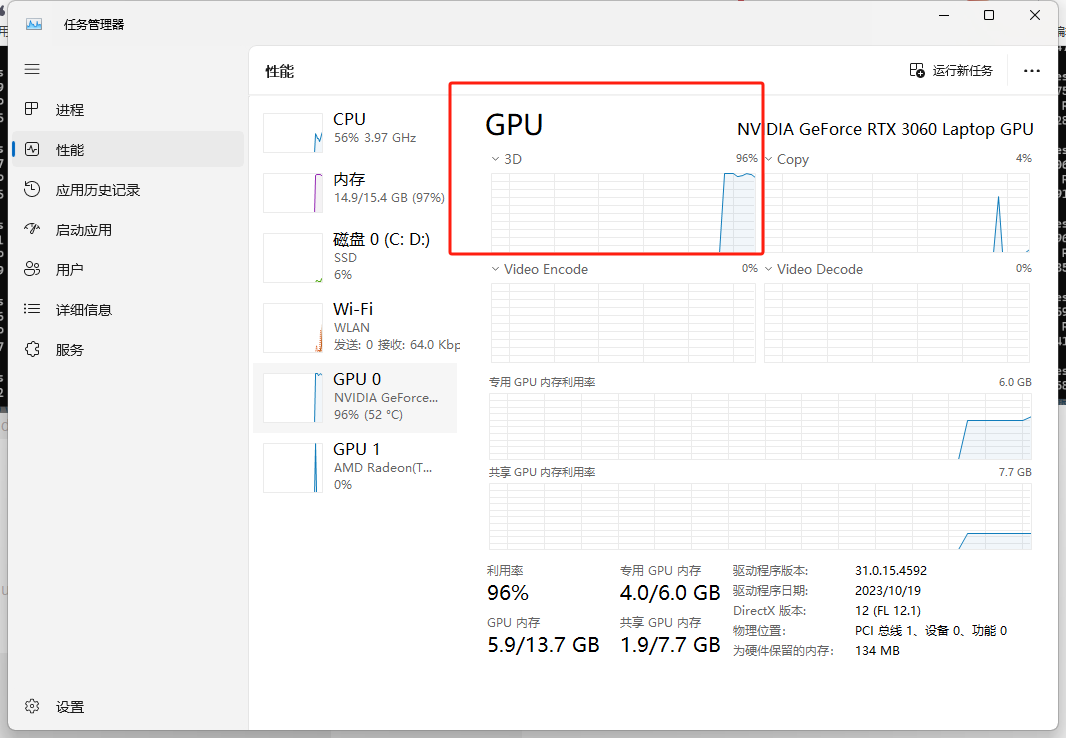
- 训练中
绝缘子训练
OBB实践
- 如何标定数据集?用哪个工具?
https://docs.ultralytics.com/zh/datasets/obb/ - 使用后缀为
_obb的模型训练
在线标注推荐使用 Roboflow
本地离线标注推荐使用 Labelimg(离线标注更有利于数据集保密)
OBB: Oriented Bounding Box 定向边界框
deepseek 搜索“在视觉目标检测领域中,常用的OBB标注工具都有哪些?”
常见疑问(FAQ)
如何用pip安装YOLO?
如何用conda安装YOLO?
使用Docker运行YOLO的优势?
如何 git clone YOLO仓库?
YOLO11n,YOLO11s,YOLO11m,YOLO11l,YOLO11x的区别是什么?
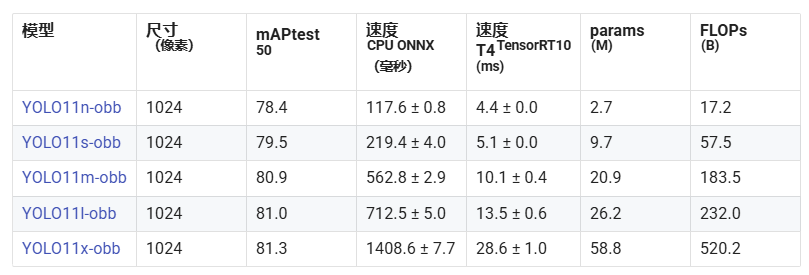
YOLO11n、YOLO11s、YOLO11m、YOLO11l和YOLO11x是YOLO11系列中不同参数规模的模型,他们的主要不同之处如下:
YOLO11n (Nano):
- Size: 2.6M parameters (1)
- mAP: 39.5
- CPU Speed(处理速度): 56.1 ± 0.8 ms
- T4 TensorRT Speed: 1.5 ± 0.0 ms
YOLO11s (Small):
- Size: 9.4M parameters
- mAP: 47.0
- CPU Speed(处理速度): 90.0 ± 1.2 ms
- T4 TensorRT Speed: 2.5 ± 0.0 ms
YOLO11m (Medium):
- Size: 20.1M parameters
- mAP: 51.5
- CPU Speed(处理速度): 183.2 ± 2.0 ms
- T4 TensorRT Speed: 4.7 ± 0.1 ms
YOLO11l (Large):
- Size: 25.3M parameters
- mAP: 53.4
- CPU Speed(处理速度): 238.6 ± 1.4 ms
- T4 TensorRT Speed: 6.2 ± 0.1 ms
YOLO11x (Extra Large):
- Size: 56.9M parameters
- mAP: 54.7
- CPU Speed(处理速度): 462.8 ± 6.7 ms
- T4 TensorRT Speed: 11.3 ± 0.2 ms


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









