






第5周学习:ShuffleNet +EfficientNet + AI艺术鉴赏
一、ShuffleNet
-
- 提出channel shuffle的思想:
GConv虽然能够减少参数计算量,但GConv中不同组之间信息没有交流,可以看到channelShuffle的效果如下。
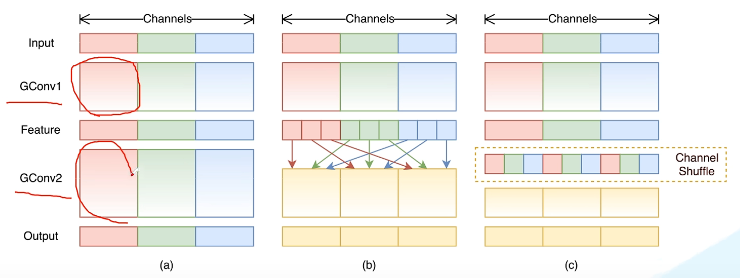
- 提出channel shuffle的思想:
-
- V2版本
相较于MobileNet对应的几个版本,其FLOPs差不多,但是错误率更低。
- 影响模型推理速度的因素
FLOPs,复杂度
MAC,内存访问消耗memory access cost
并行等级
平台GPU或者ARM - 提出了计算复杂度不能只看FLOPs,要遵循以下四条高效网络设计的准则:
(1)保持FLOPs不变,当卷积层的输入特征矩阵与输出特征矩阵channel相等时,MAC最小。

(2)保持FLOPs不变,当GConv的groups数量增大时,MAC也会增大。

(3)网络设计的碎片化程度越高,速度越慢。
(4)Element-wise操作带来的影响是不可忽视的。 - block设计,图(左)为v1,图(右)为v2,注意通过concat连接后再进行channel shuffle。
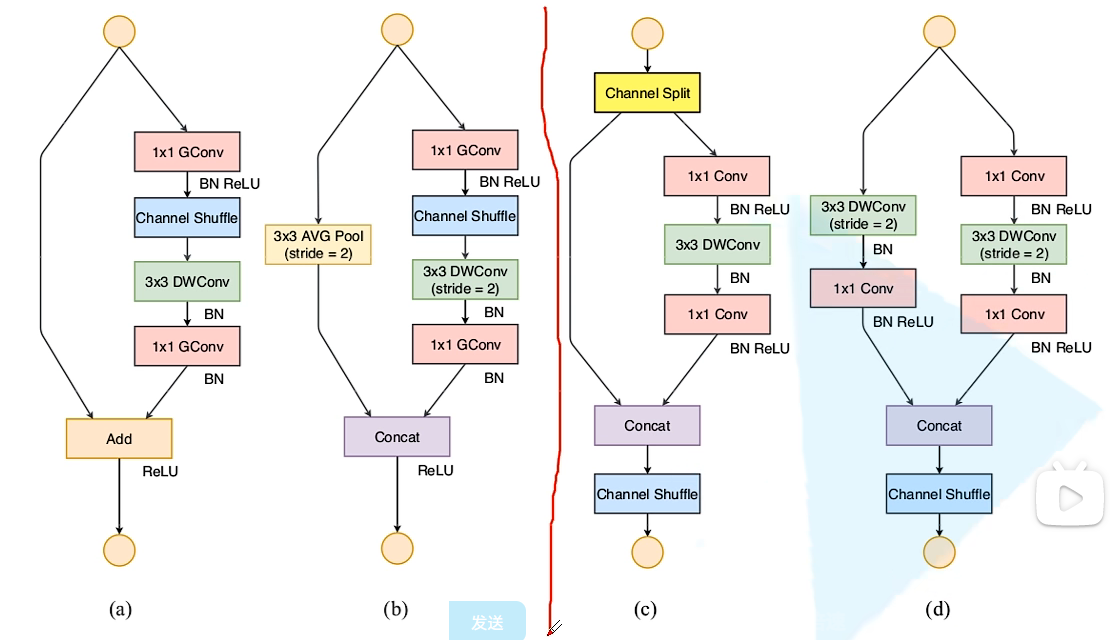
- 网络结构
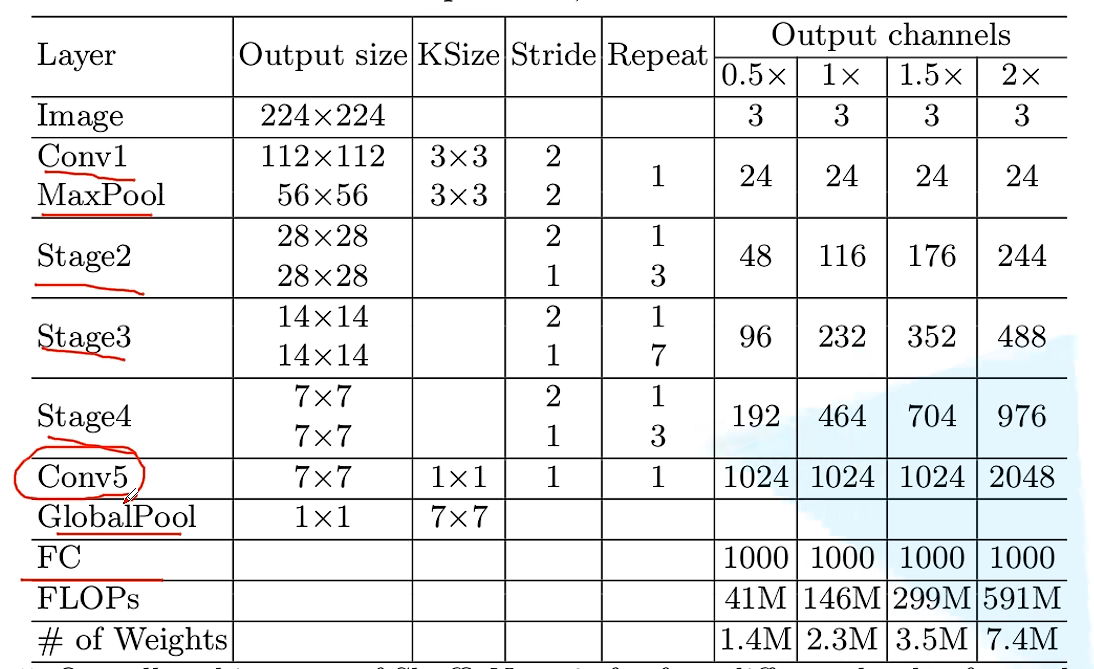
- V2版本
二、EfficientNet
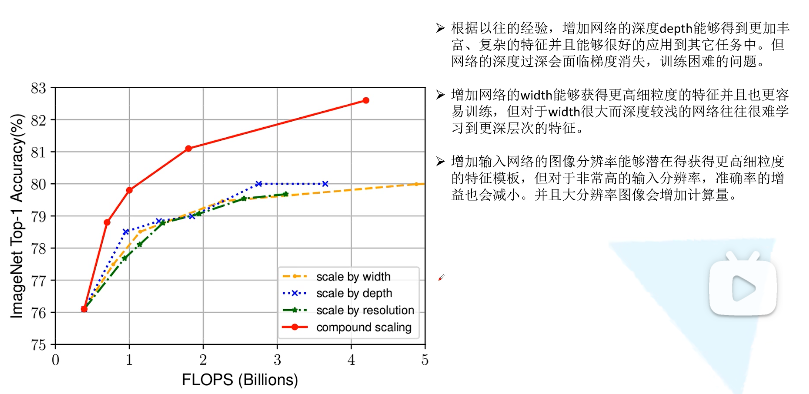
在论文中提到,本文提出的EfficientNet-B7在Imagenet top-1上达到了当年最高准确率84.3%,与之前准确率最高的GPipe相比,参数量仅为1/8.4,推理速度提升了6.1倍。
网络的深度指的是out_channel维度
EfficientNet-B0版本网络结构如下
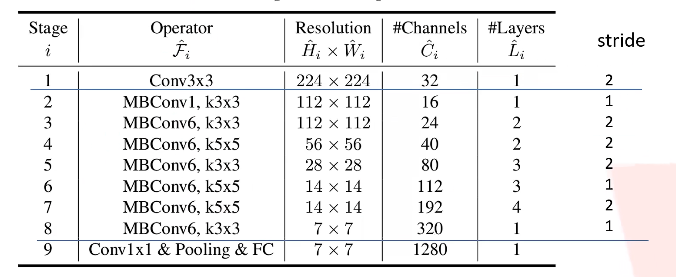
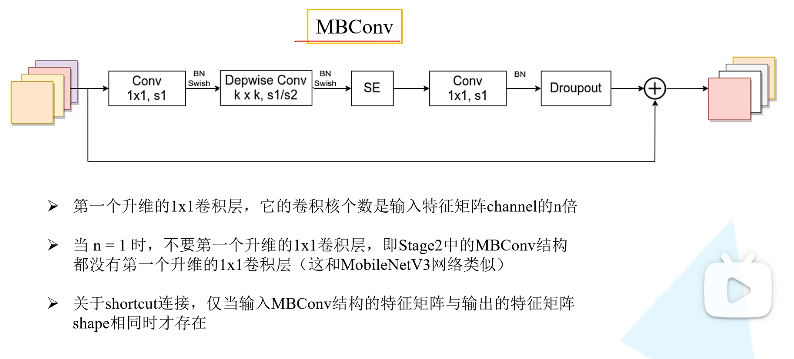
可以看到MBConv融合了SE、DW、residual等模块
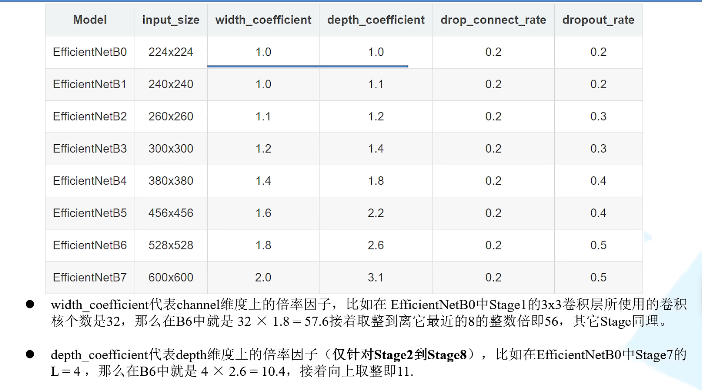
三、VGG_demo猫狗大战
所提供的代码示例使用迁移学习
#修改最后一层,冻结前面层的参数.我们的目标是使用预训练好的模型,因此,需要把最后的 nn.Linear 层由1000类,替换为2类。为了在训练中冻结前面层的参数,需要设置 required_grad=False。这样,反向传播训练梯度时,前面层的权重就不会自动更新了。训练中,只会更新最后一层的参数。
model_vgg = models.vgg16(pretrained=True)
model_vgg_new = model_vgg;
for param in model_vgg_new.parameters():
param.requires_grad = False
model_vgg_new.classifier._modules['6'] = nn.Linear(4096, 2)
model_vgg_new.classifier._modules['7'] = torch.nn.LogSoftmax(dim = 1)
model_vgg_new = model_vgg_new.to(device)
print(model_vgg_new.classifier)
'''
第一步:创建损失函数和优化器
损失函数 NLLLoss() 的 输入 是一个对数概率向量和一个目标标签.
它不会为我们计算对数概率,适合最后一层是log_softmax()的网络.
'''
criterion = nn.NLLLoss()
# 学习率
lr = 0.001
# 随机梯度下降
optimizer_vgg = torch.optim.SGD(model_vgg_new.classifier[6].parameters(),lr = lr)
在我们这个代码示例中,是在 ImageNet 上预训练好的 VGG 模型,在这个数据集中,有大量猫和狗的图片。同时,即使不修改网络,模型也可以非常准确的识别猫和狗。它展示的是如何在工程问题中使用深度学习:首先准备待解决问题的数据,然后下载预训练好的网络,接着用准备好的数据来 fine-tune 预训练好的网络。这些步骤在任何深度学习工程项目中都是如此。
四、AI艺术鉴赏
使用预训练的efficientNet-b3,输入尺寸300,30个epoch的验证集准确率:
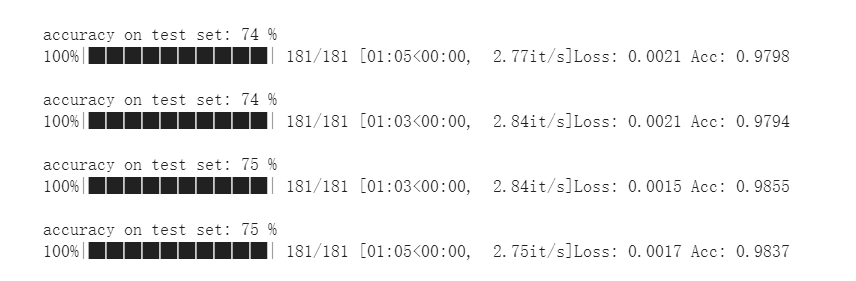
测试集:

对于预训练模型有了一定的理解,但是对于损失函数、优化器、数据预处理等相关操作还需要加强学习。
代码如下
!wget https://data.yanxishe.com/Art.zip
!unzip '/content/Art.zip'
!pip install efficientnet_pytorch
import pandas as pd
import os
import torch
import torch.nn.functional as F
import torch.nn as nn
import torchvision.models as models
from torchvision import transforms, utils
from torch.utils.data import Dataset, DataLoader
from PIL import Image
import numpy as np
import torch.optim as optim
import time
import matplotlib.pyplot as plt
from tqdm import tqdm
from efficientnet_pytorch import EfficientNet
device = torch.device("cuda:0")
print(device)
#数据处理
datadir = np.array(os.listdir('/content/train'))
#print(datadir)
file = pd.read_csv('/content/train.csv')
print(file)
def dictmap(data,num=1):
labels = []
fnames = []
for i in data:
name = int(i.split('.')[0])
fnames.append(name)
labels.append(file['label'][name])
label_dict = dict(zip(fnames,labels))
return label_dict
print(dictmap(datadir))
size = 300
#b3 1536
trans = {
'train':
transforms.Compose([
transforms.Resize([350,350]),
transforms.RandomCrop(300),#660 600 93.125
transforms.RandomHorizontalFlip(),
# transforms.RandomVerticalFlip(),
# transforms.RandomRotation(40),
# transforms.RandomAffine(20),
# transforms.ColorJitter(0.3,0.6,0.3,0.2),#0.6
transforms.ToTensor(),
transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225]),
#transforms.RandomErasing(p=0.6,scale=(0.02,0.33),ratio=(0.3,0.33),value=0,inplace=False)
]),
'val':
transforms.Compose([
transforms.Resize([300,300]),
#transforms.RandomCrop(300),
#transforms.RandomHorizontalFlip(),
# transforms.RandomVerticalFlip(),
# transforms.RandomRotation(40),
# transforms.RandomAffine(20),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])
])
}
def default_loader(path):
return Image.open(path).convert('RGB')
class dataset(Dataset):
def __init__(self, data, lab_dict, loader=default_loader, mode='Train'):
super(dataset, self).__init__()
label = []
for line in data:
label.append(lab_dict[int(line.split('.')[0])])
self.data = data
self.loader = loader
self.mode = mode
self.transforms = trans[mode]
self.label = label
def __getitem__(self, index):
fn = self.data[index]
label = self.label[index]
img = self.loader('/content/train/'+fn)
if self.transforms is not None:
img = self.transforms(img)
return img, torch.from_numpy(np.array(label))
def __len__(self):
return len(self.data)
#从训练集中划分验证集val
def Train_Valloader(data):
np.random.shuffle(data)
lab_dict = dictmap(data)
train_size = int((len(data)) * 0.8)#划分20%
train_idx = data[:train_size]
val_idx = data[train_size:]
train_dataset = dataset(train_idx, lab_dict, loader=default_loader, mode='train')
val_dataset = dataset(val_idx, lab_dict, loader=default_loader, mode='val')
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=2)
val_loader = DataLoader(val_dataset, batch_size=16, shuffle=False, num_workers=2)
return train_loader, val_loader, train_size
model = EfficientNet.from_pretrained('efficientnet-b3')
print(model)
for name,param in model.named_parameters():
if ("_conv_head" not in name) and ("_fc" not in name):
param.requires_grad = False
num_trs = model._fc.in_features
model._fc = nn.Linear(num_trs,49)
model = model.to(device)
criterion = nn.CrossEntropyLoss()
# 学习率
lr = 0.01
# 随机梯度下降
pg = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.Adam(pg,lr = lr)
#optimizer = torch.optim.SGD(model._fc.parameters(),lr=0.001,momentum=0.9)
scheduler = optim.lr_scheduler.StepLR(optimizer,step_size=5,gamma=0.5)
#训练函数
def train(model,dataloader,size):
model.train()
running_loss = 0.0
running_corrects = 0
count = 0
for inputs,classes in tqdm(dataloader):
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
optimizer.zero_grad()
loss.backward()
optimizer.step()
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
count += len(inputs)
#print('Training: No. ', count, ' process ... total: ', size)
scheduler.step()
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
# 测试函数
def val(model,dataloader):
model.eval()
test_loss = 0
correct = 0
total = 0
best_acc = 60
save_path = '/content/drive/MyDrive/Colab/deep learning/Art/art_effB3.pth'
with torch.no_grad(): # 不需要梯度,减少计算量
for images, labels in dataloader:
images, labels = images.to(device), labels.to(device)
output = model(images)
_, predicted = torch.max(output.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100. * correct / total
if accuracy > best_acc:
best_acc = accuracy
torch.save(model.state_dict(), save_path)
print('accuracy on test set: %d %% ' % accuracy)
return accuracy
accuracy_list = []
epoch_list = []
acc=0
train_loader, val_loader,train_size = Train_Valloader(datadir)
for epoch in range(50):
train(model,train_loader,train_size)
acc = val(model,val_loader)
accuracy_list.append(acc)
epoch_list.append(epoch)
plt.plot(epoch_list, accuracy_list)
plt.xlabel(epoch)
plt.ylabel(accuracy_list)
plt.show()
#test
class Dataset(torch.utils.data.Dataset):
def __init__(self):
self.images = []
self.name = []
self.test_transform = transforms.Compose([
transforms.Resize([300,300]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])
])
filepath = '/content/test'
for filename in tqdm(os.listdir(filepath)):
image = Image.open(os.path.join(filepath, filename)).convert('RGB')
image = self.test_transform(image)
self.images.append(image)
self.name.append(filename)
def __getitem__(self, item):
return self.images[item]
def __len__(self):
images = np.array(self.images)
len = images.shape[0]
return len
test_datasets = Dataset()
device = torch.device("cuda:0")
testloaders = torch.utils.data.DataLoader(test_datasets, shuffle=False)
testset_sizes = len(test_datasets)
#加载之前保存的pth
model = EfficientNet.from_name('efficientnet-b3')
f = model._fc.in_features
model._fc = nn.Linear(f,49)
model_weight_path = "/content/drive/MyDrive/Colab/deep learning/Art/art_effB3.pth"
model.load_state_dict(torch.load(model_weight_path, map_location=device))
model.to(device)
dic = {}
def test(model):
model.eval()
cnt = 0
for inputs in tqdm(testloaders):
inputs = inputs.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs.data, 1)
key = test_datasets.name[cnt].split('.')[0]
dic[key] = preds[0]
cnt += 1
with open("/content/drive/MyDrive/Colab/deep learning/Art/result.csv", 'a+') as f:
f.write("{},{}\n".format(key, dic[key]))
test(model)















 1796
1796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









