







VAR:Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
介绍
Code:https://github.com/FoundationVision/VAR
Paper:https://arxiv.org/abs/2404.02905
理解
核心提出“视觉自回归建模(VAR)”
- 方法创新
提出"下一个尺度/分辨率预测"范式,区别于传统的光栅扫描"下一个令牌预测",将自回归(AR)学习应用于图像生成。 - 性能突破
ImageNet 256×256 基准测试中:Fréchet 初始距离(FID)从 18.65 降到 1.73,初始分数(IS)从 80.4 提高到 30.2,推理速度提高 20 倍。 - 关键优势
超越扩散变压器(DiT)
在图像质量、推理速度、数据效率和可扩展性多维度领先 - 重要发现
模型表现呈现幂律缩放律
线性相关系数接近 -0.998
类似大语言模型(LLM)的缩放特性 - 泛化能力
展示零样本泛化能力,支持图像内画、外画和编辑任务 - 研究意义
为视觉生成提供新范式,揭示 AR 模型在视觉领域的潜力,促进 AR/VAR 模型在视觉生成中的研究。
引言

图1 展示了 VAR 的生成效果。
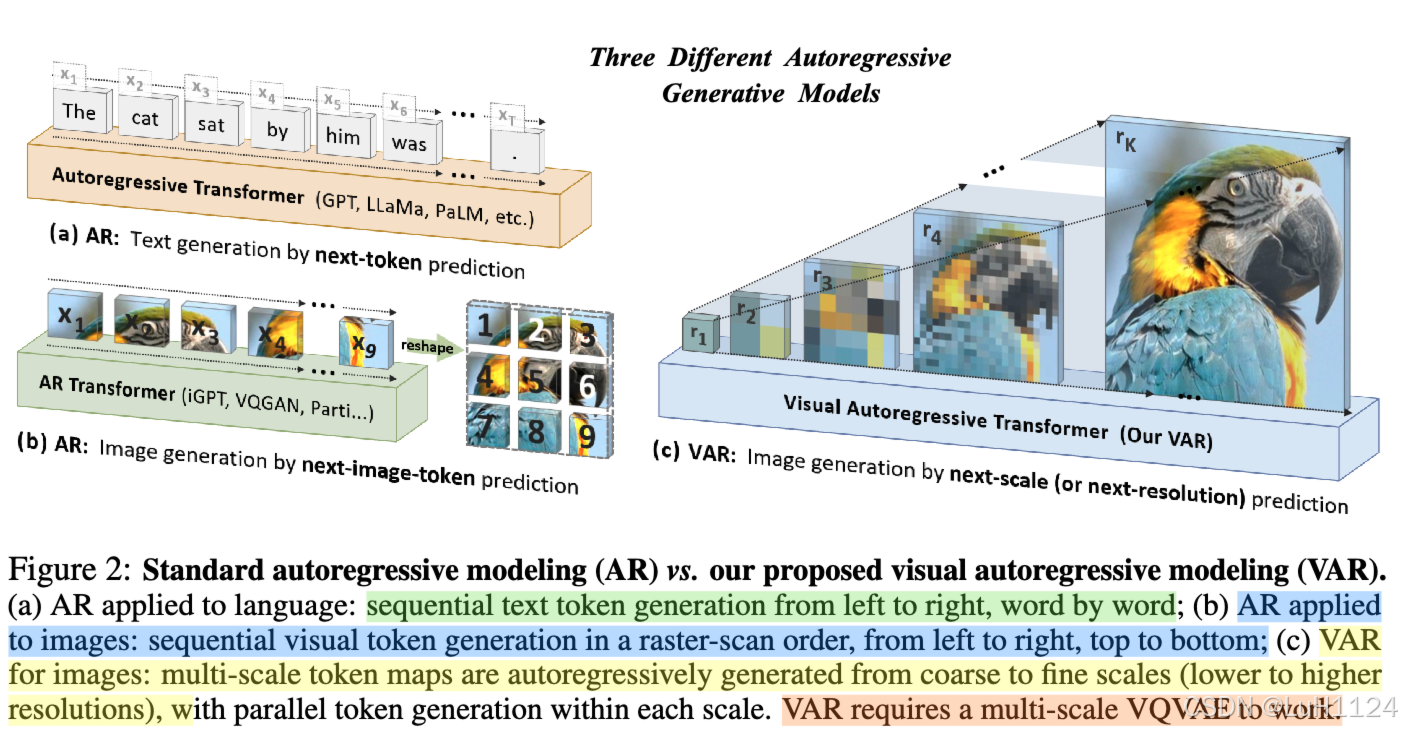
从图二中看,自回归模型在 LLM 领域已经是一家独大,CV 领域也一直在努力开发大型自回归模型,希望能够模拟 LLM 出现可扩展性和可泛化性。现有的主流 AR 模型将连续图像离散为二维标记的网格,然后将其展平为一维序列进行 AR 学习。但类似的性能难以和扩散模型相比。
自回归建模需要定义数据的顺序。我们的工作重新考虑如何“排序”图像:人类通常以分层的方式感知或创建图像,首先捕获全局结构,然后捕获局部细节。这种多尺度、从粗到细的性质表明图像的“顺序”。同样受到广泛的多尺度设计的启发,我们将图像的自回归学习定义为图2©中的“下一个尺度预测”,不同于图2(B)中的传统“下一个令牌预测”。我们的方法首先将图像编码为多尺度标记图。然后自回归过程从 1×1 令牌映射开始,并以分辨率逐步扩展:在每一步,转换器根据所有先前的令牌预测下一个更高分辨率的令牌映射。我们将此方法称为视觉自回归 (VAR) 建模。
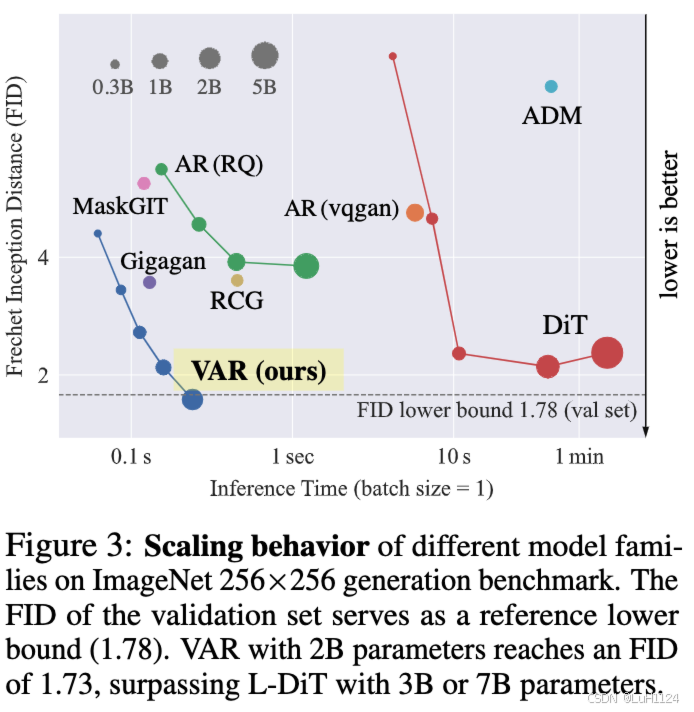
VAR直接利用类似GPT-2的变压器架构[66]进行视觉自回归学习。在 ImageNet 256×256 基准测试中,VAR 显着提高了其 AR 基线,实现了 1.73 的 Fréchet 起始距离 (FID) 和 35.2 的初始分数 (IS),推理速度快 20 倍(详见第 7 节)。值得注意的是,VAR超过了扩散变压器(DiT)——在FID/IS、数据效率、推理速度和可扩展性方面,如稳定扩散3.0和SORA。VAR 模型也表现出类似于 LLM 中所见的标度律。最后,我们展示了VAR在图像修复、外绘和编辑等任务中的零镜头泛化能力。总之,我们对社区的贡献包括:
- 一种新的视觉生成框架,使用多尺度自回归范式和下一个尺度预测,为计算机视觉的自回归算法设计提供了新的见解。
- VAR模型缩放定律和零样本泛化潜力的经验验证,它最初模拟了大型语言模型 (LLM) 的吸引人的特性。
- 视觉自回归模型性能的突破,首次使GPT风格的自回归方法在图像合成方面超过了强扩散模型。
- 一个全面的开源代码套件,包括VQ标记器和自回归模型训练管道,以帮助推动视觉自回归学习的发展。
二、相关工作
大型自回归语言模型的性质
缩放定律和零样本泛化是人工智能的两个重要发现:标度律揭示了模型性能可以随着规模持续提升,而零样本泛化则意味着模型可以处理未被明确训练的任务。这两个特性让AI模型变得越来越强大和灵活,从语言模型成功扩展到计算机视觉等其他领域,标志着人工智能正在向更加智能和通用的方向发展
视觉生成
介绍了相关的扫描式自回归模型,掩码预测模型,扩散模型。
三、方法
以往的自回归模型将 VQVAE 压缩的离散 tokens 展平为一维离散 tokens,然后使用行主光栅扫描、螺旋或 z 曲线顺序。。一旦展平,他们就可以从数据集中提取一组序列 x,然后训练一个自回归模型,通过下一个令牌预测最大化下式中的似然性。
p ( x 1 , x 2 , … , x T ) = ∏ t = 1 T p ( x t ∣ x 1 , x 2 , … , x t − 1 ) p\left(x_{1}, x_{2}, \ldots, x_{T}\right)=\prod_{t=1}^{T} p\left(x_{t} \mid x_{1}, x_{2}, \ldots, x_{t-1}\right) p(x1,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1611
1611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









