







Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
Abstract
- 提出了视觉自回归建模(VAR)[Visual AutoRegressive modeling],这是一种新的生成范式,将图像上的自回归学习重新定义为由粗到细的“下一个尺度预测”或“下一个分辨率预测”,不同于标准的光栅扫描“下一个像素预测”。这种简单直观的方法允许自回归(AR)变压器快速学习视觉分布,并具有良好的泛化能力。
- VAR模型的扩展表现出类似于LLMs的明确幂律扩展规律,线性相关系数接近-0.998,作为坚实的证据。VAR还展示了在下游任务中的零样本泛化能力,包括图像修补、外扩和编辑。这些结果表明,VAR初步模拟了LLMs的两个重要特性:扩展规律和零样本泛化能力。
作者提出了一个新的自回归图像生成范式VAR(Visual AutoRegressive modeling)来预测下一个scale/resolution
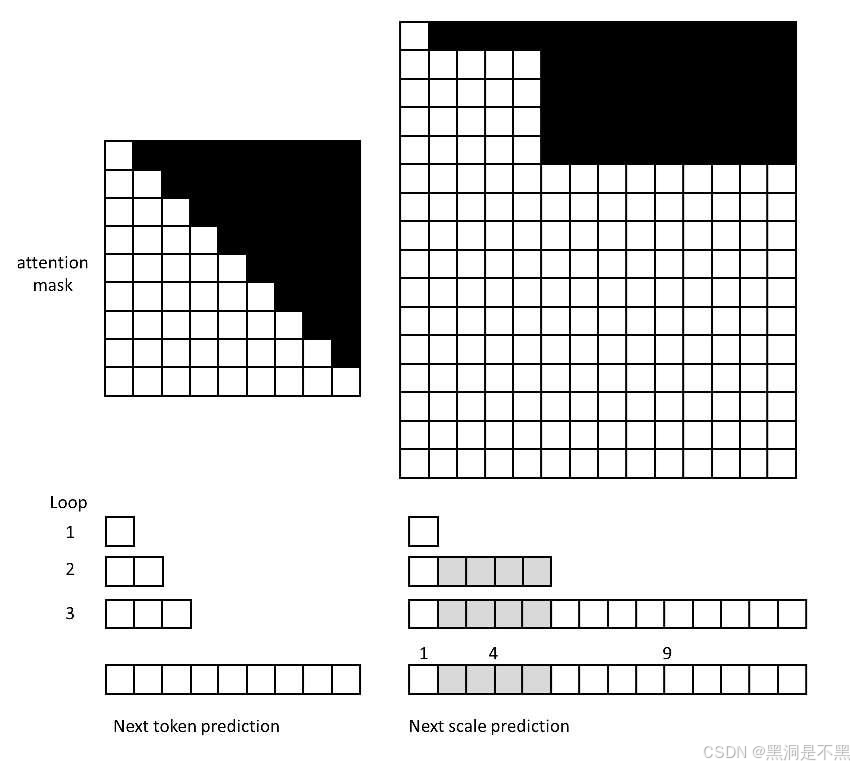
传统图像自回归生成都是采用下一个词元预测策略:将图像用自编码器拆成离散词元。从左到右、从上到下按顺序逐个生成词元。
尽管通过自编码器的压缩,要生成的词元数已经大大减少,但一个个去生成词元还是太慢了。为了改进这一点,VAR 提出了一种更快且更符合直觉的自回归生成策略:将图像用自编码器拆成多尺度的离散词元。比如,原来一张隐图像的大小是 16×16,现在我们用一系列尺度为 1×1, 2×2, …, 16×16 的由词元构成的图像来表示一张隐图像。
从最小的词元图像开始,从小到大按尺度生成词元图像。
1. Introduction
GPT系列和更多自回归(AR)大语言模型(LLMs)的出现,标志着人工智能领域的新纪元。这些模型在广泛性和多功能性方面表现出优异的智能,尽管存在诸如幻觉等问题。这些模型的核心是自监督学习策略——预测序列中的下一个标记,这是一种简单却深刻的方法。对这些大型AR模型成功的研究突出了它们的可扩展性和泛化能力:前者,通过扩展规律[43, 35],使我们能够从较小模型预测大型模型的性能,从而指导更好的资源分配;后者,通过零样本和少样本学习[66, 15],证明了无监督训练模型在面对多样且未知任务时的适应性。这些特性揭示了AR (autoregressive)模型在从大量无标签数据中学习的潜力。
与此同时,计算机视觉领域也在努力开发大型自回归或世界模型[58, 57, 6],旨在模仿其卓越的可扩展性和泛化能力。如VQGAN和DALL-E[30, 67]及其后续作品[68, 92, 50, 99]展示了AR模型在图像生成中的潜力。这些模型利用视觉标记器将连续图像离散化为2D标记的网格,然后将其展平为1D序列以进行AR学习(图2 b),这与序列语言建模的过程相似(图2 a)。然而,这些模型的扩展规律仍未得到充分探索,与LLMs的显著成就相比,自回归模型在计算机视觉中的潜力似乎有所受限。

VAR直接利用类似GPT-2的架构进行视觉自回归学习。本文的贡献包括:
- 使用多尺度自回归范式的新视觉生成框架,通过下一个尺度预测,为计算机视觉中的自回归算法设计提供了新的见解。
- 对VAR模型扩展规律和零样本泛化潜力的实证验证,初步模拟了大型语言模型(LLMs)所具有的吸引人的特性。
- 在视觉自回归模型性能上的突破,使GPT风格的自回归方法首次在图像合成中超越强大的扩散模型。
- 提供了一个全面的开源代码套件,包括VQ标记器和自回归模型训练管道,推动视觉自回归学习的进步。
2 Related Work
2.1 Properties of large autoregressive language models
Scaling laws
在自回归语言模型中发现并研究了缩放规律(Scaling Laws)[43, 35],其描述了模型规模(或数据集规模、计算量等)与测试集上的交叉熵损失值之间的幂律关系。缩放规律使我们能够直接从小规模模型预测大规模模型的性能 [1],从而指导更合理的资源分配。这些规律表明,随着模型规模、数据量和计算量的增长,大型语言模型(LLMs)的性能可以很好地扩展,且不会趋于饱和。
Zero-shot generalization.
零样本泛化指的是模型在未经过明确训练的任务上表现良好的能力。在计算机视觉领域,对基础模型(如CLIP[64]、SAM[48]、Dinov2[61])的零样本和上下文学习能力的兴趣日益浓厚。如Painter[89]和LVM[6]扩展了视觉提示器,以实现视觉中的上下文学习。
2.2 Visual generation
Raster-scan autoregressive models 栅格扫描自回归模型用于视觉生成需要将2D图像编码成1D token序列。早期的工作展示了按标准的逐行栅格扫描方式生成RGB(或分组)像素的能力。VQGAN[30]通过在VQVAE[85]的潜在空间中进行自回归学习,它使用仅解码器的GPT-2变压器按栅格扫描顺序生成token,就像ViT[28]将2D图像序列化为1D patch一样。VQVAE-2[68]和RQ-Transformer[50]也遵循这种栅格扫描方式,但使用了额外的尺度或堆叠编码。
自回归图像生成
自回归(Autoregressive)是一种直观易懂的序列生成范式:给定序列前 n 个元素,模型输出第 n+1个元素;把新元素添加进输入序列,再次输出第 n+2个元素……
自回归生成仅适用于有顺序的序列数据。为了用自回归生成图像,我们需要做两件事:1)把图像拆分成一个个元素;2)给各个元素标上先后顺序。为此,最简单的做法是将图像拆成像素,并从左到右,从上到下地给图像生成像素。例如,经典自回归图像生成模型 PixelCNN
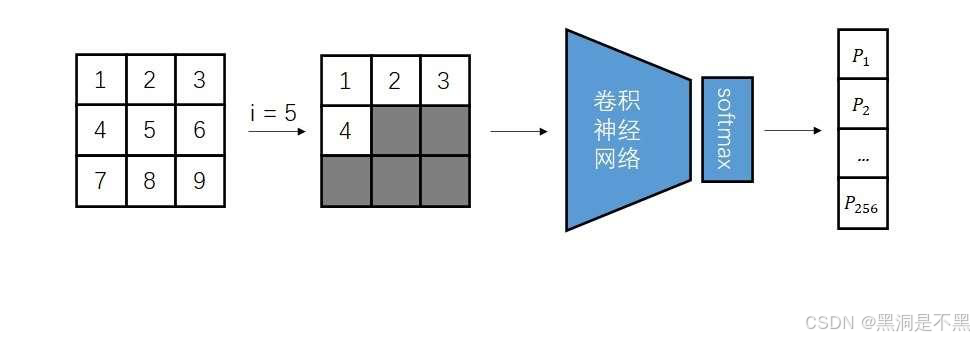
在生成第 5个像素时,模型只能利用已经生成好的前 4个像素的信息。模型的输出是一个概率分布,表示灰度值大小分别取 0, 1, …, 255 的概率。
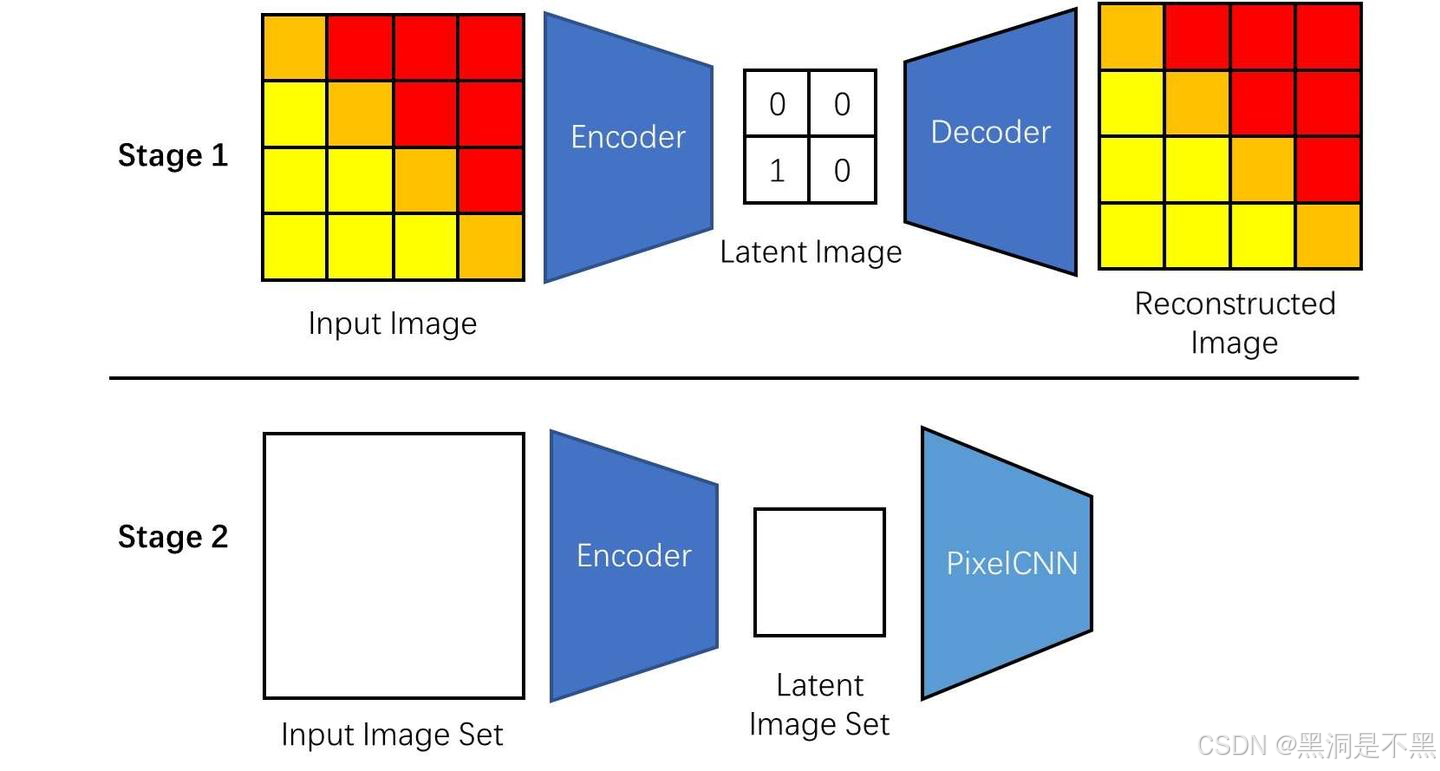
VQVAE
PixelCNN 虽然能做图像生成,但它的效率太慢了:由于像素是逐个生成的,要生成几个像素,就要运行几次神经网络。VQVAE 工作提出了一种两阶段的图像生成方法:先生成压缩图像,再用图像压缩网络将其复原成真实图像。具体流程为先训练一个图像压缩网络。这种由编码器和解码器组成的图像压缩网络被称为自编码器,压缩出来的图像被称为隐图像(latent image)。训练好了自编码器后,我们再把训练集的所有图像都转成隐图像,让 PixelCNN 学习生成隐图像。
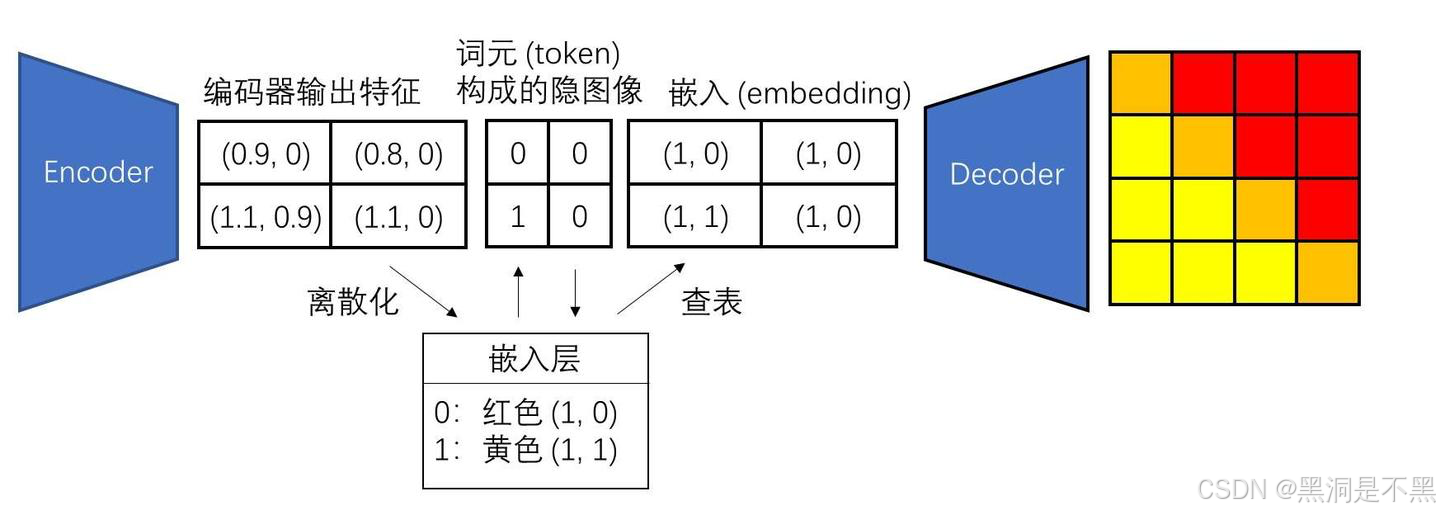
向量离散化(vector quantization, VQ)
编码器可以输出一个由任意向量构成的二维特征。通过查找嵌入层里的最近邻,这些任意的向量会被转换成整数,表示最近邻的索引。索引可以被认为是词元 (token),这样编码器输出特征就被转换成了词元构成的隐图像。而在将隐图像输入进解码器时,我们把嵌入层当成一张表格,利用隐图像里的索引,以查表的形式将隐图像转换成由嵌入构成的特征。
Masked-prediction model. MaskGIT[17]采用VQ自编码器和类似于BERT[25, 10, 34]的掩码预测变压器,通过贪婪算法生成VQ令牌。MagViT[94]将这种方法适应到视频中,MagViT-2[95]通过引入改进的VQVAE进一步增强了[17, 94],适用于图像和视频。
Diffusion models 扩散模型的进展主要集中在改进学习或采样[76, 75, 55, 56, 7]、引导[37, 60]、潜在学习[70]和架构[36, 63, 71, 91]上。DiT和U-ViT[63, 8]替换或整合了U-Net与变压器,并启发了最近的图像[19, 18]或视频合成系统[12, 33],包括Stable Diffusion 3.0[29]、SORA[14]和Vidu[9]。
3 Method
3.1 Preliminary: autoregressive modeling via next-token prediction
Formulation。考虑一个离散token序列
x
=
(
x
1
,
x
2
,
…
,
x
T
)
x = (x_1, x_2, \dots, x_T)
x=(x1,x2,…,xT),其中
x
t
∈
[
V
]
x_t \in [V]
xt∈[V] 是来自大小为
V
V
V 的词汇表的整数。下一个令牌自回归假设当前令牌
x
t
x_t
xt 的出现概率仅依赖于它的前缀
(
x
1
,
x
2
,
…
,
x
t
−
1
)
(x_1, x_2, \dots, x_{t-1})
(x1,x2,…,xt−1)。这种单向令牌依赖假设允许将序列
x
x
x 的似然进行因式分解:
p
(
x
1
,
x
2
,
…
,
x
T
)
=
∏
t
=
1
T
p
(
x
t
∣
x
1
,
x
2
,
…
,
x
t
−
1
)
.
(1)
p(x_1, x_2, \dots, x_T) = \prod_{t=1}^{T} p(x_t | x_1, x_2, \dots, x_{t-1}). \tag{1}
p(x1,x2,…,xT)=t=1∏Tp(xt∣x1,x2,…,xt−1).(1)
训练自回归模型
p
θ
p_\theta
pθ 涉及在数据集上优化
p
θ
(
x
t
∣
x
1
,
x
2
,
…
,
x
t
−
1
)
p_\theta(x_t | x_1, x_2, \dots, x_{t-1})
pθ(xt∣x1,x2,…,xt−1)。这被称为“下一个令牌预测”,训练好的
p
θ
p_\theta
pθ 可以生成新的序列。
Tokenization 图像本质上是2D连续信号。为了通过下一个令牌预测将自回归模型应用于图像,必须:1) 将图像分为多个离散令牌,2) 定义令牌的1D顺序以进行单向建模。
对于第1点,通常使用量化自编码器,将图像特征图 f ∈ R h × w × C f \in \mathbb{R}^{h \times w \times C} f∈Rh×w×C 转换为离散令牌 q ∈ [ V ] h × w q \in [V]^{h \times w} q∈[V]h×w:
f = E ( i m ) , q = Q ( f ) , (2) f =\mathcal E(im), \quad q = Q(f), \tag{2} f=E(im),q=Q(f),(2)
其中 i m im im 表示原始图像, E ( ⋅ ) E(\cdot) E(⋅) 是编码器, Q ( ⋅ ) Q(\cdot) Q(⋅) 是量化器。量化器通常包括一个可学习的代码本 Z ∈ R V × C Z \in \mathbb{R}^{V \times C} Z∈RV×C,包含 V V V 个向量。量化过程 q = Q ( f ) q = Q(f) q=Q(f) 将每个特征向量 f ( i , j ) f(i,j) f(i,j) 映射到其在欧几里得空间中最近代码的索引 q ( i , j ) q(i,j) q(i,j):
q ( i , j ) = arg min v ∈ [ V ] ∥ lookup ( Z , v ) − f ( i , j ) ∥ 2 ∈ [ V ] , (3) q(i,j) = \arg \min_{v \in [V]} \| \text{lookup}(Z, v) - f(i,j) \|^2 \in [V], \tag{3} q(i,j)=argv∈[V]min∥lookup(Z,v)−f(i,j)∥2∈[V],(3)
其中, lookup ( Z , v ) \text{lookup}(Z, v) lookup(Z,v) 表示获取代码本 Z Z Z 中的第 v v v 个向量。
为了训练量化自编码器,首先通过每个 q ( i , j ) q(i,j) q(i,j) 查找代码本 Z Z Z 以获取 f ^ \hat{f} f^,这是原始 f f f 的近似值。然后,使用解码器 D ( ⋅ ) D(\cdot) D(⋅) 根据 f ^ \hat{f} f^ 重建新图像 i m ^ \hat{im} im^,并最小化复合损失 L L L:
f ^ = lookup ( Z , q ) , i m ^ = D ( f ^ ) , (4) \hat{f} = \text{lookup}(Z, q), \quad \hat{im} = D(\hat{f}), \tag{4} f^=lookup(Z,q),im^=D(f^),(4)
L = ∥ i m − i m ^ ∥ 2 + ∥ f − f ^ ∥ 2 + λ P L P ( i m ^ ) + λ G L G ( i m ^ ) , (5) L = \|im - \hat{im}\|_2 + \|f - \hat{f}\|_2 + \lambda_P L_P(\hat{im}) + \lambda_G L_G(\hat{im}), \tag{5} L=∥im−im^∥2+∥f−f^∥2+λPLP(im^)+λGLG(im^),(5)
其中, L P ( ⋅ ) L_P(\cdot) LP(⋅) 是感知损失,如 LPIPS [97], L G ( ⋅ ) L_G(\cdot) LG(⋅) 是判别损失,如 StyleGAN 的判别器损失 [46], λ P \lambda_P λP 和 λ G \lambda_G λG 是损失权重。一旦自编码器 { E , Q , D } \{\mathcal E, Q, D\} {E,Q,D} 完全训练好,它将用于对图像进行分词,以便后续训练单向自回归模型。
LPIPS(Learned Perceptual Image Patch Similarity)
LPIPS 是一种衡量图像相似度的方法,它通过深度学习模型来评估两个图像之间的感知差异
d为 x0与x之间的距离。从L层提取特征堆(feature stack)并在通道维度中进行归一化。利用向量 w l w_l wl 来放缩激活通道数,最终计算L2距离。最后在空间上平均,在通道上求和。在标准的生成对抗网络(GAN)中,判别器(Discriminator)的损失函数旨在最大化判别器正确区分真实图像和生成图像的能力:
L D = E x ∼ p data [ log D ( x ) ] + E z ∼ p z [ log ( 1 − D ( G ( z ) ) ) ] \mathcal{L}_D = \mathbb{E}_{\mathbf{x} \sim p_{\text{data}}} [\log D(\mathbf{x})] + \mathbb{E}_{\mathbf{z} \sim p_{\mathbf{z}}} [\log (1 - D(G(\mathbf{z})))] LD=Ex∼pdata[logD(x)]+Ez∼pz[log(1−D(G(z)))]
其中, x \mathbf{x} x 是从真实数据分布 p data p_{\text{data}} pdata 中采样的真实图像; z \mathbf{z} z 是从潜在空间分布 p z p_{\mathbf{z}} pz 中采样的随机噪声向量。 G ( z ) G(\mathbf{z}) G(z) 是生成器(Generator)通过噪声向量 z \mathbf{z} z 生成的假图像。 D ( x ) D(\mathbf{x}) D(x) 是判别器对真实图像 x \mathbf{x} x 输出的概率,即真实图像被判别为真的概率。 D ( G ( z ) ) D(G(\mathbf{z})) D(G(z)) 是判别器对生成图像 G ( z ) G(\mathbf{z}) G(z) 输出的概率,即生成图像被判别为真的概率。

图像中的 token 在 q ∈ [ V ] h × w q \in [V]^{h \times w} q∈[V]h×w 中排列成一个二维网格。与自然语言句子具有固有的从左到右的顺序不同,图像 token 的顺序必须在单向自回归学习中明确地定义。先前的自回归方法 [30, 92, 50] 使用一些策略,如按行主序列扫描、螺旋扫描或 Z 曲线顺序,将二维网格 q q q 扁平化为一维序列 x = ( x 1 , … , x h × w ) x = (x_1, \dots, x_{h \times w}) x=(x1,…,xh×w)。一旦扁平化,它们就可以从数据集中提取一组序列 x x x,然后训练一个自回归模型,通过下一个 token 预测最大化(公式 1)中的似然。
关于传统自回归模型的不足讨论:
上述的 token 化和扁平化方法使得图像可以进行下一个 token 的自回归学习,但也引入了几个问题:
- 违反数学假设:在量化自动编码器(VQVAEs)中,编码器通常会生成一个图像特征图 f f f,该特征图中所有 f ( i , j ) f(i,j) f(i,j) 之间是相互依赖的。因此,经过量化和扁平化后,token 序列 ( x 1 , x 2 , … , x h × w ) (x_1, x_2, \dots, x_{h \times w}) (x1,x2,…,xh×w) 保留了双向关联。这与自回归模型的单向依赖假设相矛盾,后者要求每个 token x t x_t xt 只依赖于其前缀 ( x 1 , x 2 , … , x t − 1 ) (x_1, x_2, \dots, x_{t-1}) (x1,x2,…,xt−1)。
- 无法进行零样本 泛化:与问题 1 类似,图像自回归建模的单向特性限制了其在需要双向推理的任务中的泛化能力。例如,无法根据图像的下半部分预测上半部分。
- 结构退化:扁平化破坏了图像特征图中固有的空间局部性。例如,token q ( i , j ) q(i,j) q(i,j) 及其四个相邻的即时 neighbors q ( i ± 1 , j ) , q ( i , j ± 1 ) q(i\pm1,j), q(i,j\pm1) q(i±1,j),q(i,j±1) 由于彼此接近而高度相关。这个空间关系在一维序列 x x x 中被破坏,单向约束减弱了这些关联。
- 低效性。使用传统的自注意力变换器生成图像 token 序列 x = ( x 1 , x 2 , … , x n × n ) x = (x_1, x_2, \ldots, x_{n \times n}) x=(x1,x2,…,xn×n) 时,需要 O ( n 2 ) O(n^2) O(n2) 次自回归步骤,且计算成本为 O ( n 6 ) O(n^6) O(n6)。

在 VQVAE 中的token的依赖性
为了检查 VQVAE [30] 中的令牌依赖性,我们检查了在向量量化模块之前自注意力层中的注意力分数。随机从 ImageNet 验证集选取了 4 张 256×256 的图像进行分析。需要注意的是,VQVAE 中的自注意力层只有一个头,因此每张图像只绘制一个注意力图。在图 9 中的热力图显示了每个令牌对所有其他令牌的注意力分数,表明所有令牌之间存在强烈的双向依赖性。因为 VQVAE 模型在训练时旨在重建图像,并利用没有任何注意力掩码的自注意力层。
自回归 (AR) 时间复杂度
引理 B.1 对于标准的自注意力变换器,AR 生成的时间复杂度为 O(n⁶),其中 h = w = n h = w = n h=w=n,h 和 w 分别是 VQ 代码图的高度和宽度。
证明:总的令牌数是
h
×
w
=
n
2
h × w = n²
h×w=n2。对于第 i 次
(
1
≤
i
≤
n
2
)
(1 ≤ i ≤ n²)
(1≤i≤n2) 自回归迭代,需要计算每个令牌与所有其他令牌之间的注意力分数,这需要
O
(
i
2
)
\mathcal O(i²)
O(i2) 的时间。因此,总时间复杂度为:
∑
i
=
1
n
2
i
2
=
n
2
(
n
2
+
1
)
(
2
n
2
+
1
)
6
\sum_{i=1}^{n^2} i^2 = \frac{n^2(n^2 + 1)(2n^2 + 1)}{6}
i=1∑n2i2=6n2(n2+1)(2n2+1)
这等价于
O
(
i
6
)
\mathcal O(i^6)
O(i6) 基本计算。
3.2 Visual autoregressive modeling via next-scale prediction
Reformulation :我们通过将自回归建模从“下一个令牌预测”转变为“下一个尺度预测”策略,重新构想了图像上的自回归建模。在这里,自回归单元是整个token图,而不是单个token。我们首先将特征图 f ∈ R h × w × C f \in \mathbb{R}^{h \times w \times C} f∈Rh×w×C 量化为 K 个多尺度令牌图 ( r 1 , r 2 , … , r K r_1, r_2, \dots, r_K r1,r2,…,rK),每个令牌图的分辨率逐渐增大 h k × w k h_k \times w_k hk×wk,最终 r K r_K rK 匹配原始特征图的分辨率 h × w h \times w h×w。自回归似然函数被表述为:
p ( r 1 , r 2 , … , r K ) = ∏ k = 1 K p ( r k ∣ r 1 , r 2 , … , r k − 1 ) , p(r_1, r_2, \dots, r_K) = \prod_{k=1}^{K} p(r_k | r_1, r_2, \dots, r_{k-1}), p(r1,r2,…,rK)=k=1∏Kp(rk∣r1,r2,…,rk−1),
其中,每个自回归单元 r k ∈ [ V ] h k × w k r_k \in [V]^{h_k \times w_k} rk∈[V]hk×wk 是第 k 层尺度的令牌图,包含 h k × w k h_k \times w_k hk×wk 个令牌,序列 ( r 1 , r 2 , … , r k − 1 ) (r_1, r_2, \dots, r_{k-1}) (r1,r2,…,rk−1) 作为 r k r_k rk 的“前缀”。在第 k 步自回归中,所有关于 r k r_k rk 中的 h k × w k h_k \times w_k hk×wk 个令牌的分布将并行生成,条件是 r k r_k rk 的前缀以及关联的第 k 层位置嵌入图。这个“下一个尺度预测”方法是我们定义的视觉自回归建模(VAR),如图 4 右侧所示。需要注意的是,在 VAR 的训练中,使用了块级因果注意力掩码,确保每个 r k r_k rk 只能关注其前缀 r ≤ k r_{\leq k} r≤k。在推理阶段,可以使用键值(kv)缓存,并且不需要掩码。

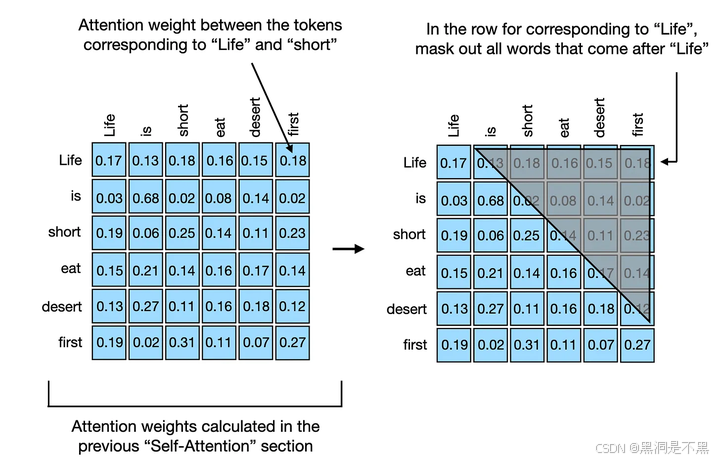
“Causal mask” 是指在自注意力机制(self-attention mechanism)中的一种掩码。
为了保持模型对未来信息的无法访问性,我们需要在每个位置处将未来位置的信息屏蔽掉。这就是所谓的“causal mask”,因为它只允许当前位置之前的信息流动,从而保证了模型的生成是基于先前的内容,而不是未来的内容。
通常情况下,causal mask 是一个二维矩阵,其中对角线以下的元素都为1,表示允许当前位置之前的信息流动,而对角线及以上的元素都为0,表示屏蔽了当前位置之后的信息。在序列生成任务中,这种掩码非常重要,因为它确保了模型按照序列的顺序逐步生成输出,而不会提前使用未来的信息
Discussion.:VAR 解决了之前提到的三个问题,具体如下:
-
数学前提得到了满足,如果我们限制每个 r k r_k rk 仅依赖于其前缀,即获取 r k r_k rk 的过程仅与 r ≤ k r_{\leq k} r≤k 相关。这一约束是可以接受的,因为它符合自然的从粗到精的进展特性。
-
空间局部性得到了保留,因为(i)在 VAR 中没有扁平化操作,且(ii)每个 r k r_k rk 中的令牌是完全相关的。多尺度设计进一步强化了空间结构。
-
生成一个 n × n n \times n n×n 潜在图像的复杂度显著降低至 O ( n 4 ) O(n^4) O(n4),这一效率提升源自于每个 r k r_k rk 中令牌的并行生成。
对于 VAR,它需要我们定义自回归生成的分辨率序列 ( h 1 , w 1 , h 2 , w 2 , … , h k , w k ) (h₁, w₁, h₂, w₂,…, hₖ, wₖ) (h1,w1,h2,w2,…,hk,wk),其中 hᵢ 和 wᵢ 是第 i 步自回归时 VQ 代码图的高度和宽度,hₖ = h,wₖ = w 达到最终分辨率。假设对于所有 1 ≤ k ≤ K 1 ≤ k ≤ K 1≤k≤K, n k = h k = w k nₖ = hₖ = wₖ nk=hk=wk,且 n = h = w n = h = w n=h=w,为了简化,设定分辨率为 n k = a ( k − 1 ) nₖ = a^{(k−1)} nk=a(k−1),其中 a > 1 是一个常数,使得 a ( K − 1 ) = n a^{(K−1)} = n a(K−1)=n。
视觉自回归 (VAR) 生成的时间复杂度
引理 B.2 对于一个标准的自注意力 Transformer,给定超参数 a > 1 a > 1 a>1,VAR(视觉自回归)生成的时间复杂度为 O ( n 4 ) O(n^4) O(n4),其中 h = w = n h = w = n h=w=n, h h h 和 w w w 分别是最后(最大)VQ 码图的高度和宽度。
证明 : 考虑第
k
k
k 次(
1
≤
k
≤
K
1 \leq k \leq K
1≤k≤K)自回归生成。当前所有标记图(
r
1
,
r
2
,
…
,
r
k
r_1, r_2, \ldots, r_k
r1,r2,…,rk)的标记总数为:
∑
i
=
1
k
n
i
2
=
∑
i
=
1
k
a
2
⋅
(
k
−
1
)
=
a
2
k
−
1
a
2
−
1
.
(18)
\sum_{i=1}^k n^2_i = \sum_{i=1}^k a^{2 \cdot (k - 1)} = \frac{a^{2k} - 1}{a^2 - 1}. \tag{18}
i=1∑kni2=i=1∑ka2⋅(k−1)=a2−1a2k−1.(18)
因此,第
k
k
k 次自回归生成的时间复杂度为:
(
a
2
k
−
1
a
2
−
1
)
2
.
(19)
\left( \frac{a^{2k} - 1}{a^2 - 1} \right)^2. \tag{19}
(a2−1a2k−1)2.(19)
通过对所有自回归生成过程求和,可以得到:
∑
k
=
1
log
a
(
n
)
+
1
(
a
2
k
−
1
a
2
−
1
)
2
.
(20)
\sum_{k=1}^{\log_a(n) + 1} \left( \frac{a^{2k} - 1}{a^2 - 1} \right)^2. \tag{20}
k=1∑loga(n)+1(a2−1a2k−1)2.(20)
通过计算简化,最终得:
(
a
4
−
1
)
log
n
+
a
8
n
4
−
2
a
6
n
2
−
2
a
4
(
n
2
−
1
)
+
2
a
2
−
1
log
a
(
a
2
−
1
)
3
(
a
2
+
1
)
log
a
.
(21)
\frac{(a^4 - 1) \log n + \frac{a^8n^4 - 2a^6n^2 - 2a^4(n^2 - 1) + 2a^2 - 1}{\log a}}{(a^2 - 1)^3 (a^2 + 1) \log a}. \tag{21}
(a2−1)3(a2+1)loga(a4−1)logn+logaa8n4−2a6n2−2a4(n2−1)+2a2−1.(21)
当
n
n
n 较大时,时间复杂度的增长速率可近似为:
O
(
n
4
)
.
O(n^4).
O(n4).
Tokenization. 我们开发了一种新的多尺度量化自编码器,将图像编码为 VAR 学习(6)所需的 K 个多尺度离散令牌图 R = ( r 1 , r 2 , … , r K ) R = (r_1, r_2, \dots, r_K) R=(r1,r2,…,rK)。我们采用与 VQGAN [30] 相同的架构,但对多尺度量化层进行了修改。编码和解码过程采用残差设计,作用于 f f f 或 f ^ \hat{f} f^,详细内容请见算法 1 和 2。我们通过实验证明,这种残差风格的设计(类似于 [50])比独立插值效果更好。算法 1 显示,每个 r k r_k rk 仅依赖于其前缀 ( r 1 , r 2 , … , r k − 1 ) (r_1, r_2, \dots, r_{k-1}) (r1,r2,…,rk−1)。请注意,在所有尺度中使用共享代码簿 Z Z Z,确保每个 r k r_k rk 的令牌属于相同的词汇表 [ V ] [V] [V]。为了处理在将 z k z_k zk 上采样到 h K × w K h_K \times w_K hK×wK 时的信息丢失,我们使用了 K 个额外的卷积层 { ϕ k } k = 1 K \{ \phi_k \}^K_{k=1} {ϕk}k=1K。在将 f f f 下采样到 h k × w k h_k \times w_k hk×wk 后,则不使用卷积。

现在词元图像不是一张图像,而是多张不同尺度的图像,由于词元图像的定义发生了改变,编码器特征和嵌入的定义也会发生改变,
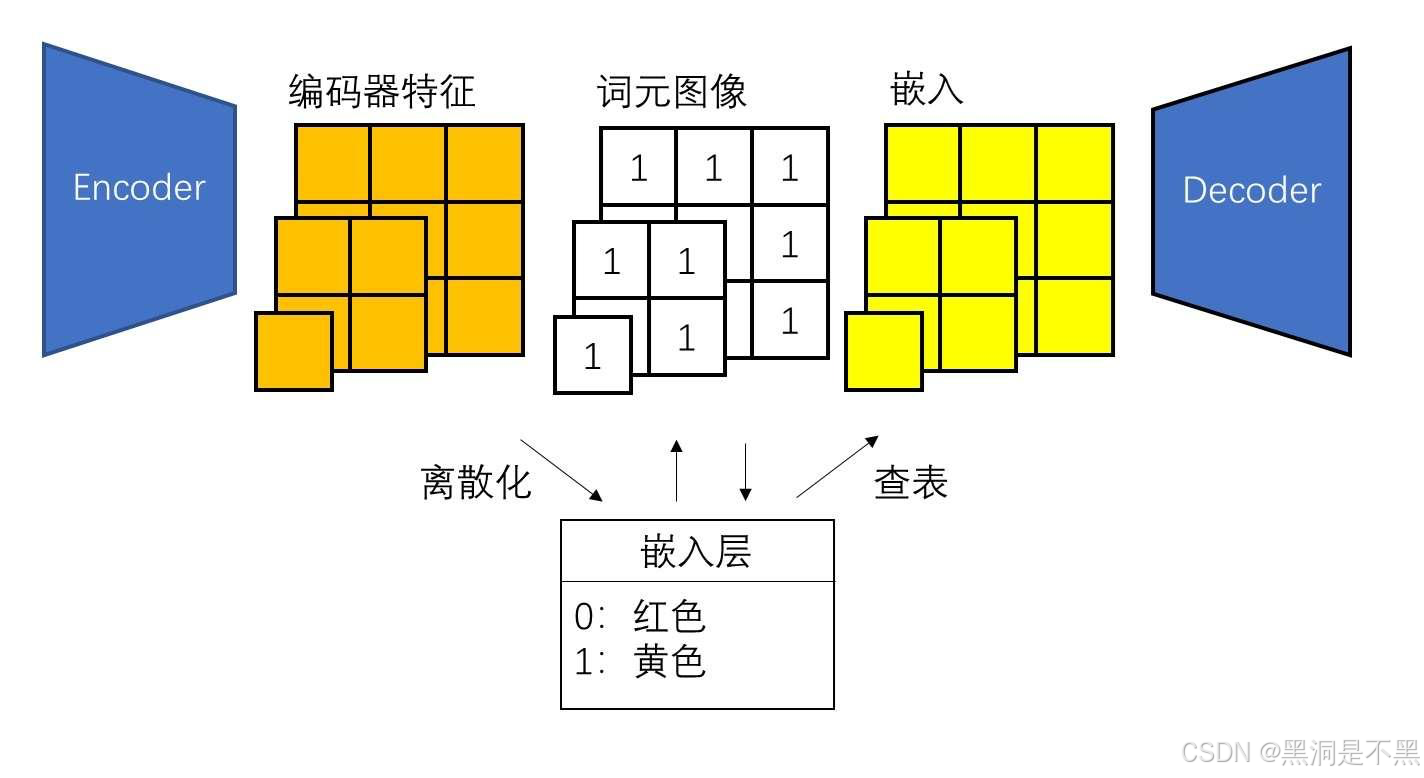
VAR 用残差金字塔来表示这些隐空间特征。在计算拉普拉斯金字塔时,会不断下采样图像,并计算当前尺度的图像和下一尺度的复原图像(通过上采样复原)的残差。通过不断上采样最低尺度的图像并加上每一层的残差,最终就复原出高分辨率的原图像。
VAR 并没有简单地把退化和复原定义为下采样和上采样,而是将向量离散化引入的误差也算入金字塔算法的退化内。也就是说,我们现在的目标不是让编码器特征金字塔的累加和编码器特征相等,而是想办法让嵌入金字塔的累加和编码器特征尽可能相似。
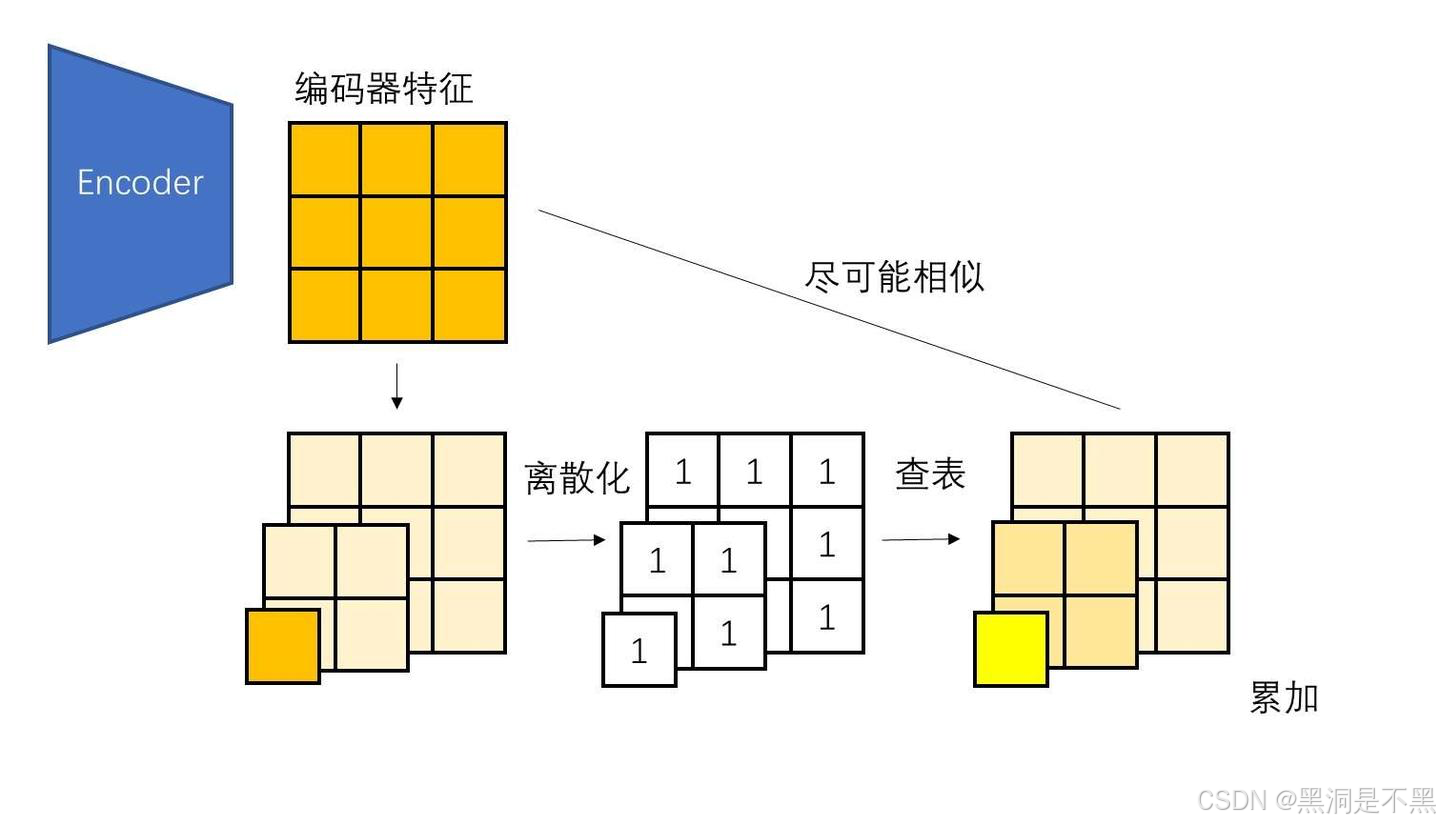
基于这一目标,我们可以把退化定义为下采样加上离散化、查表,复原定义成上采样加一个可学习的卷积。
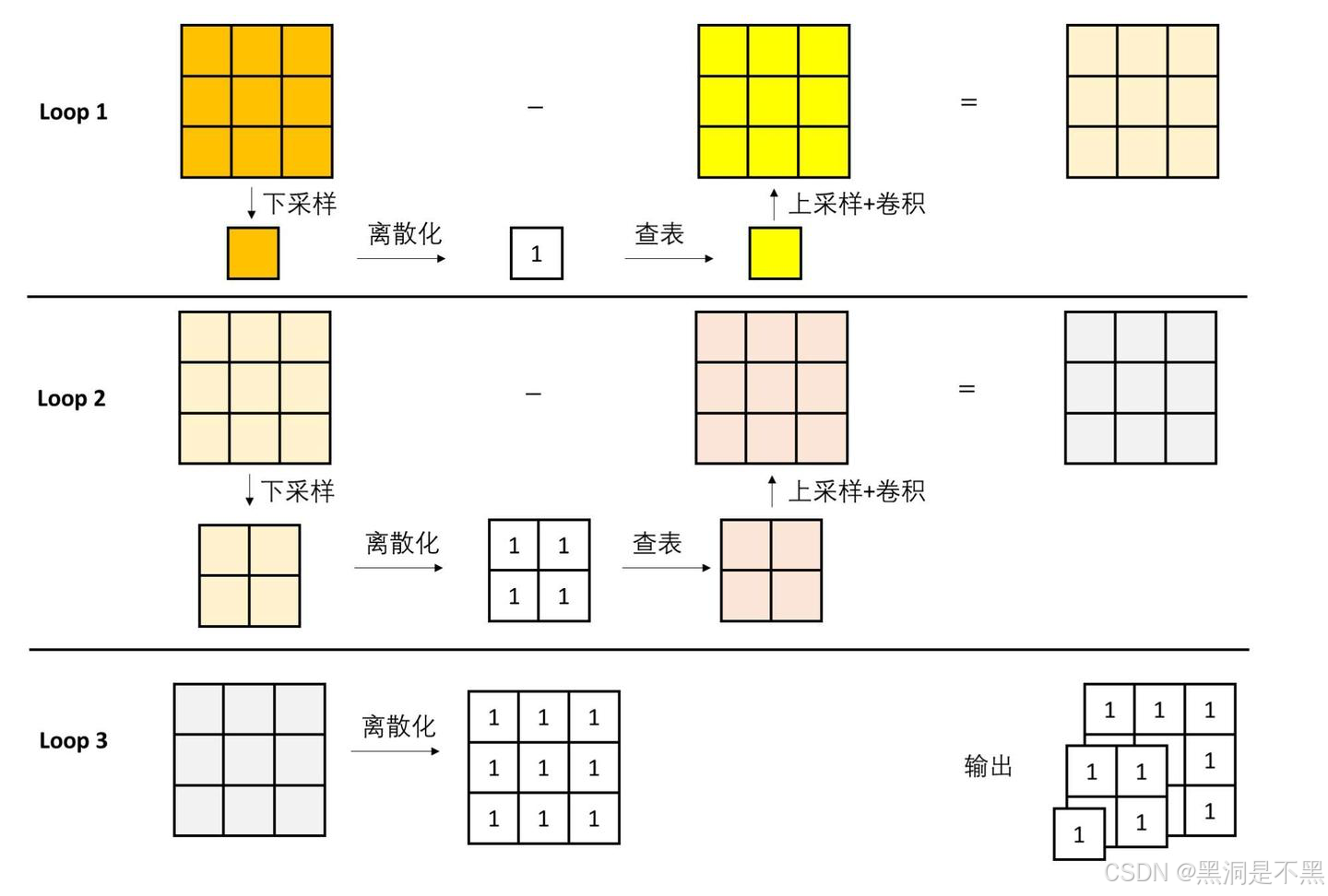
多尺度向量离散化操作
这个操作的输入是编码器特征,输出是一系列多尺度词元图像。算法从最低尺度开始执行,每个循环输出当前尺度的词元图像,并将残差特征作为下一个循环的输入特征。
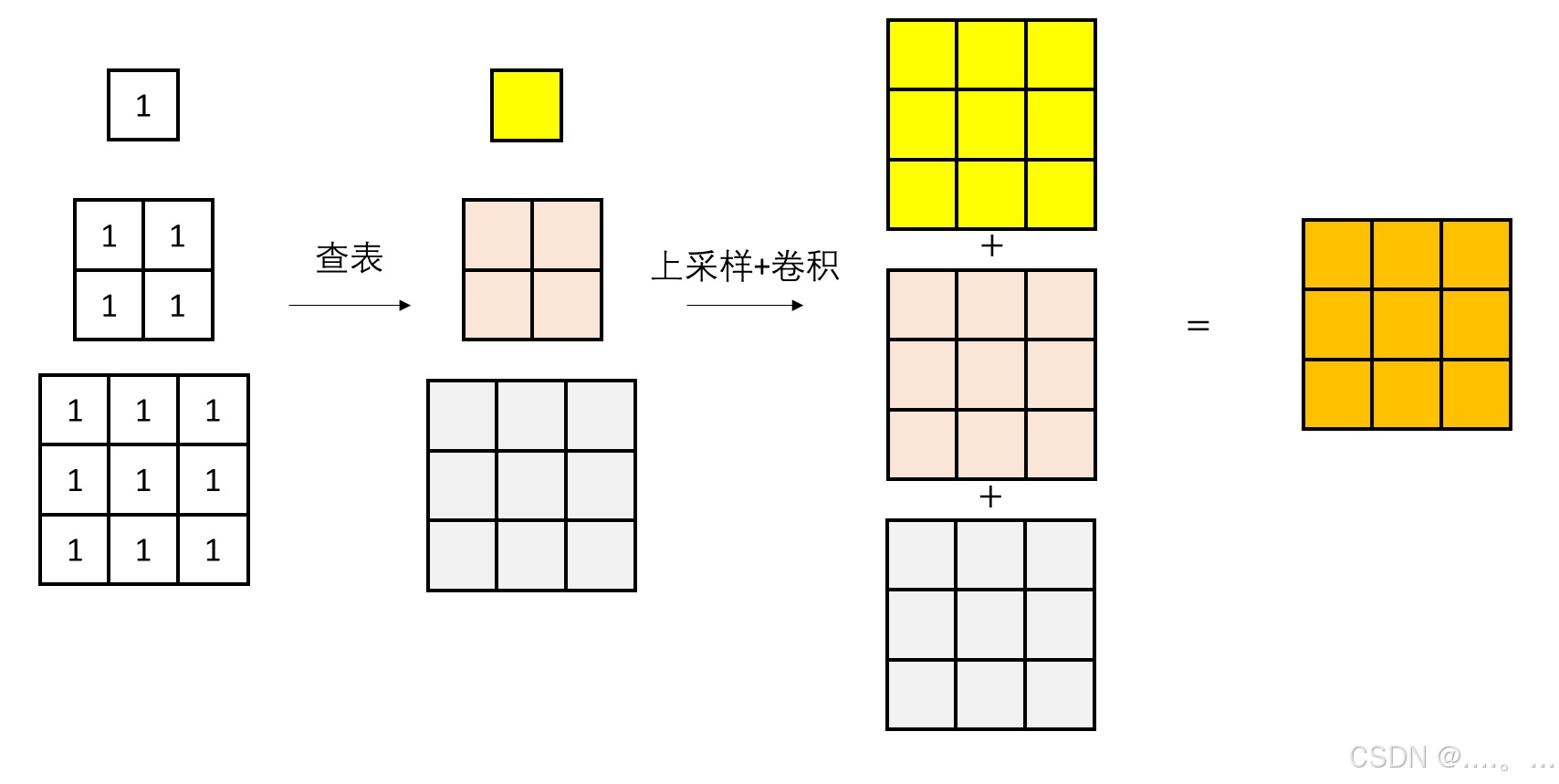
多尺度查表操作,输入是多尺度词元图像,输出是一张最大尺度的隐空间特征,它将成为自编码器的解码器的输入。在这步操作中,我们只需要分别对各个尺度的词元图像做查表和复原(上采样+卷积),再把各尺度的输出加起来,就能得到一个和编码器特征差不多的特征。
把图像压缩成多尺度词元图像后,只需要把所有词元拆开,拼成一维词元序列,之后用 Transformer 在这样的序列上训练即可。由于现在模型的任务是下一尺度预测,模型会一次性输出同尺度各词元的概率分布,而不是仅仅输出下一个词元的。这样,尽管序列总长度变长了,模型的整体生成速度还是比以前快。同时,随着预测目标的变更,自注意力的掩码也变了。现在同尺度的词元之间可以互相交换信息,只是前一尺度的词元看不到后面的词元。
VAR 采用了一种多尺度残差离散化操作:将编码器特征拆解成最小尺度的特征以及不同尺度的残差特征,并对不同尺度的特征分别做向量离散化。

















 1693
1693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









