







 本文介绍了如何利用GEO公共数据库搜索乳腺癌相关数据,涉及数据类型如平台、样本、系列和数据集,以及实例说明了数据组织和搜索流程。
本文介绍了如何利用GEO公共数据库搜索乳腺癌相关数据,涉及数据类型如平台、样本、系列和数据集,以及实例说明了数据组织和搜索流程。
概览
GEO是一个公共数据库,用来储存研究人员分享的数据,一般而言主要是指高通量测序,比如芯片,二代测序,三代测序等等。我觉着主要有两个目的,一是数据共享,不重复造轮子,不做无用功,二是数据的可重复性(数据上传的规范化)
如何搜索目标数据
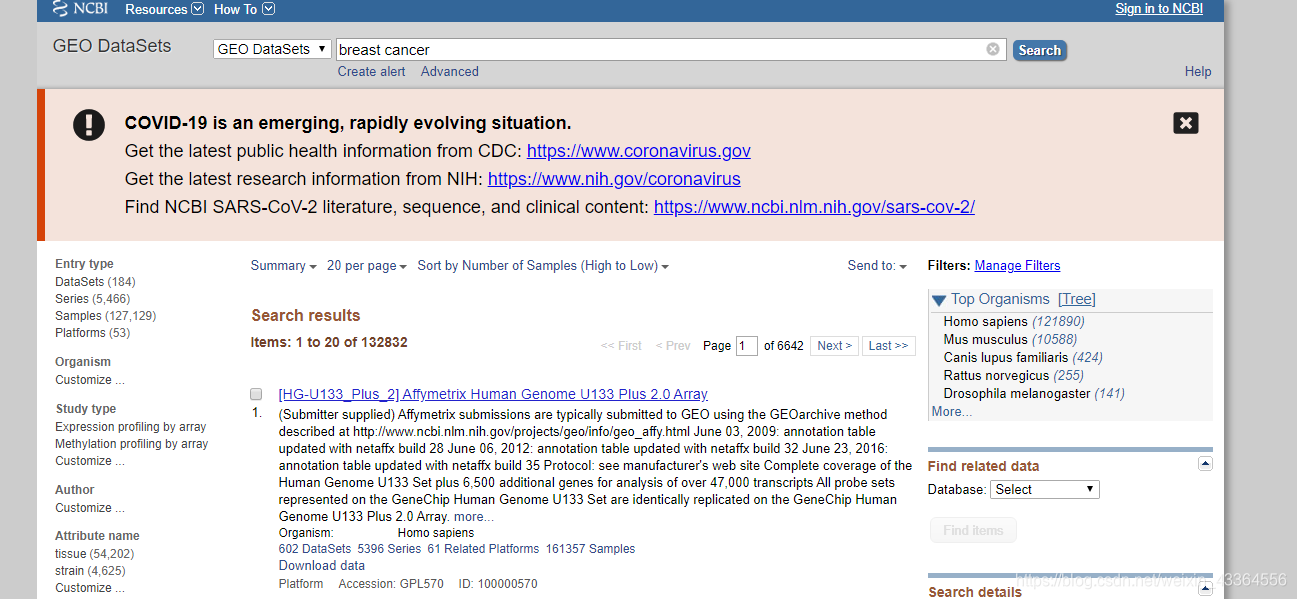
大部分人都希望利用别人的数据发文章,毕竟生信是发文章的低成本通道。在分析数据之前我们需要收集我们感兴趣的数据,比如,乳腺癌,肝癌,肺癌等。利用关键词到GEO网站进行搜索
数据组织形式
GEO里的数据可以分为不同的数据类型:主要分为五类,分别为平台(Plateform),样本(Samples),系列(Series),数据集(DataSet),数据概要(Profile),其中前三者是用户上传数据的时候会自动分配给对应的ID。
1.平台(Plateform)
每一种数据产生的仪器平台那么就对应一个plateform,比如GPL11154表示的是Illumina HiSeq2000,而GPL18573则表示Illumina NextSeq500,每一种数据产生的平台不同,那么对应的信号值和数据类型都可能不同。可以根据平台搜索以这种平台测序的数据结果。
2.样本(Samples)
该研究人员此次上传的样本信息,记录了每一个样本的处理情况,每一个样本都会有唯一一个ID与之对应(GSMXXXXXX),我们可以通过搜索这个ID快速的确认这个样本的信息。一个样本只能对应一个平台信息,但是能够对应多个Series信息(多个上传记录里引用同一个样本)。下面介绍Series
3.系列(Series)
Series是将一系列相关的样本进行聚合在一起给一个ID,每一个Series将会给与一个ID(GSExxxxxx),也就是一个研究人员上传数据的时候会将它这一批次上传的样本分配一个ID.
4.数据集(DataSet)
这个数据是用户上传数据之后,GEO的员工根据一次实验的数据(也就是一组匹配的数据,比如对照组和实验组)进行整理形成的一个数据集形式,然后分配给其一个ID(GDSXXXXX).我平时搜索的时候主要是用到Series,这个Dataset数据量比较少(因为人为处理的速度赶不上数据生产的速度)。
一个DataSet中的数据需要满足:同一个平台,数据用同一种方式进行计算(比如normalizatiojn的方法等,保证数据的可比性),
5.Profile(数据概要)
这个Profile的信息主要是针对基因的展示,它是给定的基因在某个DataSet中的各个样本中的表达量的概要。
实例
我这里以乳腺癌为例,可以看到DataSets(184)的数量远小于Series数量(5466),一般根据Series中的样本从大到小排序,找到我们需要的样本,接下来再进行分析。

















 568
568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









