






结合实现简单梳理了LDPC,方便学习LDPC码的朋友们轻松上手。如果能实操,那5G的LDPC编译码也就很简单了。
一、LDPC编码原理
1. 基本概念
LDPC(Low-Density Parity-Check)码是一种接近香农限的线性分组码,因其稀疏校验矩阵而得名。码字由信息位和校验位组成,满足线性约束条件。其核心特点是校验矩阵H是稀疏的,即矩阵中“1”的数量远少于“0”。
1.1 校验矩阵H
校验矩阵H是一个m×n的二进制矩阵,其中:
m:校验方程的数量。
n:码字长度。
每一行对应一个校验方程,每一列对应一个码字位。
2. 编码过程
编码过程为发送序列u和生成矩阵G相乘:c=uG。
2.1 生成矩阵G
生成矩阵G是一个k×n的矩阵,满足:
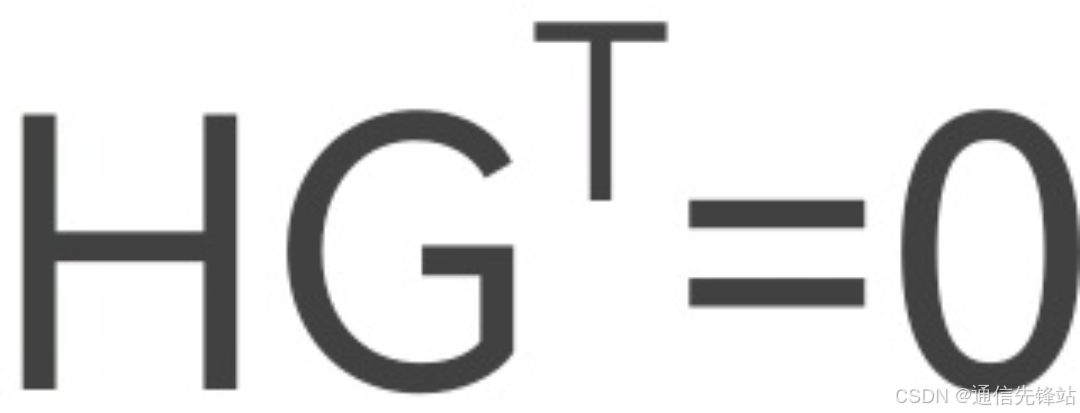
其中:
• u:长度为k的信息位向量。
• c:长度为n的码字向量
(比如5G协议仅规定了校验矩阵H,我们需要根据此公式计算生成矩阵G)
2.2 系统码形式
LDPC码通常采用系统码形式,码字c由信息位u和校验位p组成:c=[u | p]
校验位p通过求解校验方程得到:H=[P | Im]。
(才用系统码的好处是信息位和检验位是分开的,便于打孔处理)
3. 译码过程
LDPC码的译码通常采用置信传播(Belief Propagation, BP)算法,也称为消息传递算法(Message Passing Algorithm, MPA)。
3.1 置信传播算法
变量节点:对应码字位,接收来自校验节点的消息并更新自身信息。
校验节点:对应校验方程,接收来自变量节点的消息并更新校验信息。
迭代过程:变量节点和校验节点交替更新消息,直到满足校验方程或达到最大迭代次数。
3.2 译码步骤
1、初始化:根据接收到的信号初始化变量节点的概率。
2、变量节点更新:向相邻的校验节点发送消息。
3、校验节点更新:向相邻的变量节点发送消息。
4、判决:根据变量节点的最终消息判决码字位。
5、终止条件:若满足校验方程或达到最大迭代次数,则终止译码。
二、LDPC编码设计
1. 校验矩阵设计
校验矩阵H的设计直接影响LDPC码的性能。常用的设计方法包括:
随机构造法:随机生成稀疏矩阵,确保每行和每列的“1”的数量满足要求。
结构化构造法:基于代数或几何方法构造矩阵,如基于有限域或循环移位的方法。
1.1 示例:Gallager构造法
Gallager提出的规则LDPC码构造方法:
将校验矩阵H分为wc个子矩阵,每个子矩阵的每列只有一个“1”。
通过随机排列子矩阵的行,确保每行的“1”数量为wr。
2. 编码设计
LDPC编码的关键是生成矩阵G的构造和校验位的计算。
2.1 生成矩阵构造
1.将校验矩阵H转化为系统形式:
H=[P | Im]
其中P是m×k的矩阵,Im是m×m的单位矩阵。
生成矩阵G为:

其中Ik是k×k的单位矩阵。
2.2 编码步骤
1.将信息位u与生成矩阵G相乘,得到码字c:c=uG
若采用系统码形式,校验位p通过求解校验方程得到:
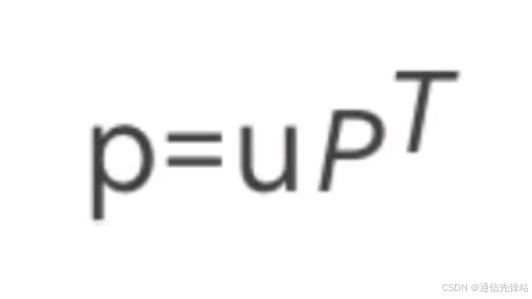
3. 译码设计
LDPC译码通常采用置信传播算法,具体实现步骤如下:
3.1 初始化
根据接收到的信号计算变量节点的初始概率(如对数似然比LLR)。
3.2 消息传递
变量节点到校验节点:
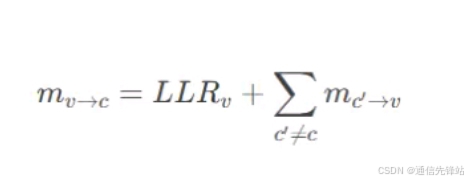
校验节点到变量节点:
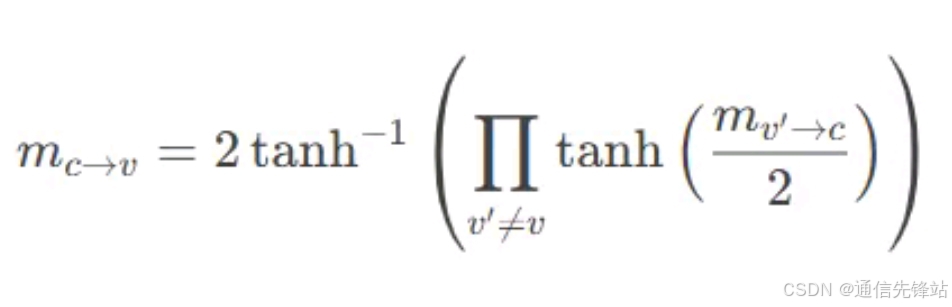
3.3 判决
根据变量节点的最终LLR值判决码字位:

4.4 译码终止条件
若Hc'=0'或达到最大迭代次数,则终止译码。
三、实现
以下是基于上述LDPC编码和译码实例的MATLAB代码实现。代码包括校验矩阵设计、生成矩阵构造、编码过程和译码过程。
% LDPC编码与译码示例
clear;
m=128;
n=256;
%产生H矩阵
H=genH(m,n);
H=double(H);
% 2. 生成矩阵构造
[P_h,re_cols]=H2P(H);
% 3. 编码过程
u=round(rand(1, n-m));
u1=[mod((P_h*u')',2) u];
c=reorder(u1,re_cols);
% disp('编码后的码字:');
% disp(c);
% 4. 译码过程
y = [c(1:255) ~c(256)]; %将译码输入的最后一位取反,模拟传输错误
% 初始化变量节点的对数似然比(LLR)
LLR = 2 * y - 1; % 将0/1映射为-1/+1
% 置信传播算法参数
max_iter = 60; % 最大迭代次数
tol = 1e-6; % 容忍误差
% 消息传递
for iter = 1:max_iter
% 变量节点到校验节点
m_v2c = repmat(LLR, m, 1) .* H; % 初始化消息
% 校验节点到变量节点
m_c2v = zeros(m, n);
for i = 1:m
for j = 1:n
if H(i, j) == 1
% 计算校验节点到变量节点的消息
prod_tanh = 1;
for l = 1:n
if H(i, l) == 1 && l ~= j
prod_tanh = prod_tanh * tanh(m_v2c(i, l) / 2);
end
end
m_c2v(i, j) = 2 * atanh(prod_tanh);
end
end
end
% 更新变量节点的LLR
LLR_new = LLR;
for j = 1:n
sum_mc2v = 0;
for i = 1:m
if H(i, j) == 1
sum_mc2v = sum_mc2v + m_c2v(i, j);
end
end
LLR_new(j) = LLR(j) + sum_mc2v;
end
% 判决
c_hat = (LLR_new >= 0); % 判决码字位
% 检查是否满足校验方程
if mod(c_hat * H', 2) == 0
disp('译码成功!');
disp('译码迭代次数:');
disp(iter);
break;
end
% 更新LLR
LLR = LLR_new
% 检查是否达到最大迭代次数
if iter == max_iter
disp('达到最大迭代次数,译码失败!');
end
end
%%%%%%%%译码后bit%%%%%%%%%%%%
uhat = punc(c_hat,re_cols);
运行结果:

以下是基于上述LDPC编码和译码实例的Verilog代码实现。代码包括校验矩阵设计、生成矩阵构造、编码过程和译码过程。
module ldpc_encoder (
input wire [2:0] u, // 3-bit 信息位
output wire [5:0] c // 6-bit 码字
);
// 生成矩阵 G = [I_k | P^T]
assign c[0] = u[0]; // c[0] = u[0]
assign c[1] = u[1]; // c[1] = u[1]
assign c[2] = u[2]; // c[2] = u[2]
assign c[3] = u[0] ^ u[1]; // c[3] = u[0] + u[1]
assign c[4] = u[1] ^ u[2]; // c[4] = u[1] + u[2]
assign c[5] = u[2]; // c[5] = u[2]
endmodule
module ldpc_decoder (
input wire [5:0] y, // 6-bit 接收信号
output reg [5:0] c_hat, // 6-bit 译码后的码字
output reg success // 译码成功标志
);
reg [2:0] LLR [5:0]; // 变量节点的对数似然比(LLR)
reg [2:0] m_v2c [2:0][5:0]; // 变量节点到校验节点的消息
reg [2:0] m_c2v [2:0][5:0]; // 校验节点到变量节点的消息
integer i, j, l;
// 置信传播算法参数
parameter MAX_ITER = 10; // 最大迭代次数
integer iter;
// 初始化LLR
initial begin
for (i = 0; i < 6; i = i + 1) begin
LLR[i] = (y[i] == 1) ? 3'b111 : 3'b000; // 简单映射
end
end
// 置信传播算法
always @(*) begin
for (iter = 0; iter < MAX_ITER; iter = iter + 1) begin
// 变量节点到校验节点
for (i = 0; i < 3; i = i + 1) begin
for (j = 0; j < 6; j = j + 1) begin
if (H[i][j] == 1) begin
m_v2c[i][j] = LLR[j];
for (l = 0; l < 3; l = l + 1) begin
if (H[l][j] == 1 && l != i) begin
m_v2c[i][j] = m_v2c[i][j] + m_c2v[l][j];
end
end
end
end
end
// 校验节点到变量节点
for (i = 0; i < 3; i = i + 1) begin
for (j = 0; j < 6; j = j + 1) begin
if (H[i][j] == 1) begin
m_c2v[i][j] = 0;
for (l = 0; l < 6; l = l + 1) begin
if (H[i][l] == 1 && l != j) begin
m_c2v[i][j] = m_c2v[i][j] + m_v2c[i][l];
end
end
end
end
end
// 更新变量节点的LLR
for (j = 0; j < 6; j = j + 1) begin
LLR[j] = (y[j] == 1) ? 3'b111 : 3'b000;
for (i = 0; i < 3; i = i + 1) begin
if (H[i][j] == 1) begin
LLR[j] = LLR[j] + m_c2v[i][j];
end
end
end
// 判决
for (j = 0; j < 6; j = j + 1) begin
c_hat[j] = (LLR[j] >= 0) ? 1'b1 : 1'b0;
end
// 检查是否满足校验方程
success = 1;
for (i = 0; i < 3; i = i + 1) begin
if ((c_hat[0] & H[i][0]) ^
(c_hat[1] & H[i][1]) ^
(c_hat[2] & H[i][2]) ^
(c_hat[3] & H[i][3]) ^
(c_hat[4] & H[i][4]) ^
(c_hat[5] & H[i][5]) != 0) begin
success = 0;
end
end
if (success) begin
break; // 译码成功,退出迭代
end
end
end
endmodule
// 测试模块
module testbench;
reg [2:0] u; // 3-bit 信息位
wire [5:0] c; // 6-bit 码字
reg [5:0] y; // 6-bit 接收信号
wire [5:0] c_hat; // 6-bit 译码后的码字
wire success; // 译码成功标志
// 实例化编码器
ldpc_encoder encoder (
.u(u),
.c(c)
);
// 实例化译码器
ldpc_decoder decoder (
.y(y),
.c_hat(c_hat),
.success(success)
);
initial begin
// 测试用例
u = 3'b101; // 信息位
#10;
y = c; // 无噪声情况
#10;
$display("编码后的码字: %b", c);
$display("译码后的码字: %b", c_hat);
$display("译码成功: %b", success);
// 添加噪声
y = 6'b101101; // 假设接收到的信号有误
#10;
$display("编码后的码字: %b", c);
$display("译码后的码字: %b", c_hat);
$display("译码成功: %b", success);
end
endmodule
四、总结
LDPC编码其实很简单的,复杂的是译码迭代过程,译码过程中的检验节点和变量节点的更新需要花时间好好看一下。
关注我,后续写一篇mini-sum算法的译码,可以大大简化译码计算复杂度。

















 6147
6147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









