







四、模型优化
由于多模态信息的存在,当多模态编码器和推荐模型一起训练时,模型训练的计算要求大大增加。因此,多模态推荐模型在训练过程中可以分为两类:端到端训练和两步训练。
端到端训练可以利用反向传播获得的每个梯度来更新模型中所有层的参数。而两步训练包括第一阶段预训练多模态编码器和第二阶段面向任务的优化。
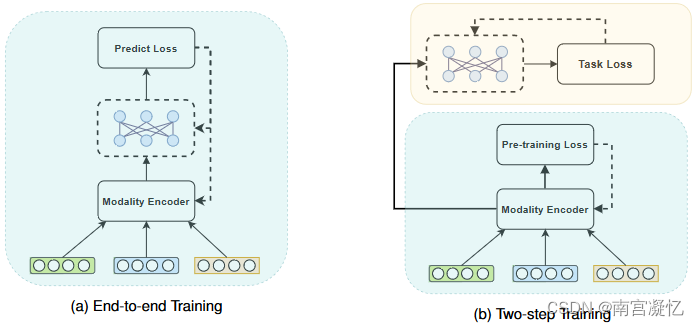
4.1 端到端训练
由于多模态推荐系统使用图片、文本、音频和其他多媒体信息,因此在处理这些多模态数据时,通常采用其他领域中的一些常用编码器,如Vit[13]、Resnet[17]、Bert[12]。这些预训练模型的参数往往非常庞大。例如,Vit-Base[13]的参数数量达到86M,这对计算资源来说是一个巨大的挑战。
为了解决这一问题,大多数MRS直接采用预训练编码器,仅以端到端的模式训练推荐模型。
NOVA和VLSNR使用预训练编码器对图像和文本特征进行编码,然后通过模型嵌入得到的多模态特征向量,并向用户推荐。结果表明,在不更新编码器参数的情况下引入多模态数据也可以提高推荐性能。
MCPTR通过推荐和对比损耗,仅用100个历元微调编码器参数。
一些端到端的推荐方法也旨在减少计算量,同时提高推荐性能,它们通常会减少培训时需要更新的参数数量。
例如,MKGformer是一种多层变压器结构,其中共享了许多关注层参数以减少计算量。
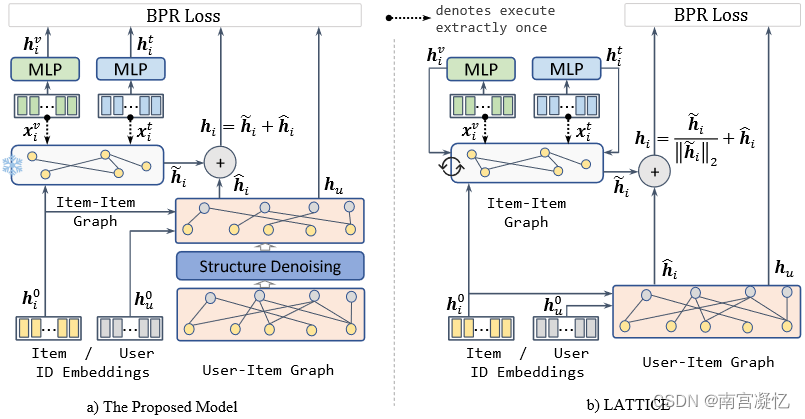
FREEDOM设计用于冻结图结构的一些参数,显著降低内存开销,并实现去噪效果以提高推荐性能。
FREEDOM: A Tale of Two Graphs: Freezing and Denoising Graph Structures for Multimodal Recommendation 2023
以前的工作将多模态特征融合到项目ID嵌入中以丰富项目表示,因此无法捕获潜在的语义项目结构。在这种背景下,LATTICE提出明确地学习项目之间的潜在结构,并实现多模态推荐的最新性能。然而,我们认为LATTICE的潜在图结构学习是无效的和不必要的。实验证明,在训练前冻结其项目结构也能获得竞争性成绩。
基于这一发现,我们提出了一个简单而有效的模型,称为FREEDOM,该模型冻结了项目-项目图,同时对多模式推荐中的用户-项目交互图进行去噪。从理论上讲,我们通过图谱的角度来研究自由度的设计,并证明它在图谱上有一个更紧的上界。在对用户项交互图进行去噪处理时,设计了一种对度敏感的边缘剪枝方法,在对图进行采样时以较高的概率剔除可能存在的噪声边缘。
4.2 两步训练
与端到端模式相比,两阶段训练模式能够更好地针对下游任务,但对计算资源的要求更高。因此,很少有MRS采用两步训练法。
PMGT参考Bert的结构,提出了一种预训练图变换器。它学习项目表示有两个目标:图结构重构和屏蔽节点特征重构。在POG中,训练一个经过训练的变形金刚学习服装匹配知识,然后通过一个布料生成模型向用户推荐。
此外,在顺序推荐任务中,它是常见的,在这种情况下,很难在端到端方案中训练模型。
例如,在预训练阶段,MML首先通过元学习训练元学习者以增加模型泛化,然后训练项目嵌入生成器第二阶段。此外,TESM和Victor分别预训练了一个设计良好的图神经网络和一个视频转换器。

















 1095
1095

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









