







论文标题:Assessing Arabic Weblog Credibility via Deep Co-learning
日期:ACL2019
基于新闻文本、半监督、伪标签、协同学习
一、基本内容
利用co-learning的方法训练两个模型,让两个模型互相为无标注的数据打伪标签,从而让两个模型互相越学越好,实现较好的效果。
该工作设计一个以word embedding(词嵌入)为输入的CNN网络和一个以character embedding(字符级嵌入,每次迭代中重新训练)为输入的CNN网络,先利用有标注数据训练两个网络,之后两个网络互相为无标注数据打上伪标签,从而获得更多的带标注数据训练两个网络,依次迭代,直至模型收敛,取得最佳效果。
二、模型框架
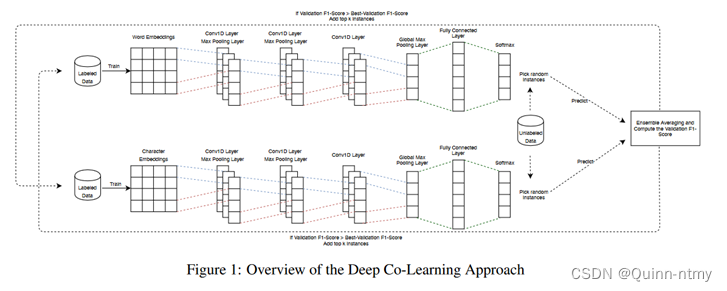
算法流程:

- 第一个数据集 D l D^l Dl,是一个小并且全部注释的数据集,用于最初训练两个CNN模型 M 1 M_1 M1和 M 2 M_2 M2。
- 对于两个模型 M 1 M_1 M1和 M 2 M_2 M2,我们从未标记的数据集 D u l D^{ul} Dul中随机选取 m m m个实例,将模型 M 1 M_1 M1和 M 2 M_2 M2应用于为每个模型选择的 m m m个实例上。
- 迭代训练两个co-learning模型 M 1 M_1 M1和 M 2 M_2 M2:如从 M 1 M_1 M1中的 m m m个实例选择 k k k个实例,然后使用它们来训练 M 2 M_2 M2(或用 M 2 M_2 M2训练 M 1 M_1 M1)。【目标是选择最高准确性的 k k k个实例:如果计算并应用了 M 1 M_1 M1模型的每个实例的分数,我们就选择由 M 1 M_1 M1模型标记的前 k k k个得分最高的实例,并使用它来训练 M 2 M_2 M2。】
- 使用两个模型的集成平均值,并将其应用于第三个数据集 D v l D^{vl} Dvl,该数据集用于验证的完全注释的数据集。两个模型的集成平均值的验证分数存储在深度学习算法每次迭代的变量 f 1 f1 f1分数中。检查 f 1 f1 f1分数是否高于当前最佳 f 1 f1 f1分数,如果更高,则更新模型并使用top-k实例扩充数据集。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









