






文章目录
1 Projects and files
本节描述有关项目和文件的组织和命名的一些指南。
1.1 Project Location and Naming
所有项目(应用程序)都应该位于C:\GMAS\MyGMASProjects目录下,该目录是在软件环境安装过程中创建的。根目录C:\可以替换为磁盘的实际名称。
每个项目应该位于上述位置下的特定目录中,给定目录中只有一个项目。
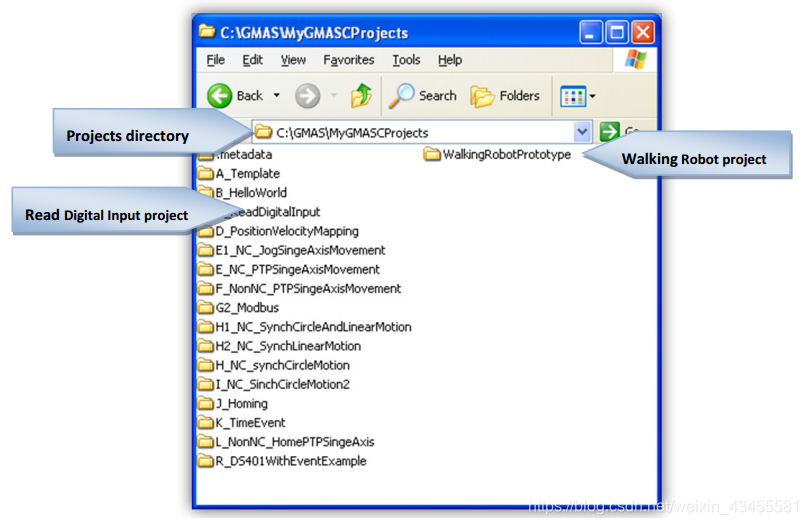
项目目录的名称应该反映项目(应用程序)的名称。例如,来自Elmo的C程序集示例:“C_ReadDigitalInput”(参见下面的屏幕快照)。请注意,项目目录的名称遵循以下准则:
- 它反映了项目/应用程序的内容
- 没有空格
- 如果单词很少,每个单词都以大写字母开头,便于阅读
- 最后,为了方便起见,Elmo在项目名称中添加了一个前缀(在本例中为“C_”),以强制在Windows资源管理器中以给定的顺序显示项目列表。这样做是为了按照本手册读者所需的顺序组织我们的内置示例。您不需要添加此前缀(请参阅下面屏幕快照中的customer项目WalkingRobotPrototype)
以上三个为项目目录命名的准则,也适用于为项目的所有C和H文件命名。名称必须反映文件的内容,不包含空格,名称中的每个单词都应该以大写字母开头,例如:ReadDigitalInput.c
1.2 Project’s Files
每个项目将基于一个主C文件,遵循以下指导原则:
- 它的名称将与项目的目录名称相同(如果使用,则不带前缀)。例如:ReadDigitalInput.c
- 它将包含main()函数,这将是文件中的第一个函数。
每个项目还将包含一个主头文件(*.h),该文件也将以项目的名称命名(例如ReadDigitalInput.h),并将包含针对项目的所有定义(如常量、函数原型等)。
此外,开发人员可以创建额外的代码和头文件,这可能是正确组织各种C函数所需要的。所有文件都应该使用上面的文件命名指南来命名。
1.3 Project’s Description Files
Elmo强烈建议应用程序程序员应该在项目目录中添加一些文件,解释项目目标、任务、实现方法等。它可以是一个简单的自述文件,也可以是更复杂的文件(机器规范、运动序列、机器的)ATP、实施设计评审等)。如果将此信息与整个项目代码文件一起提供(用于开发团队中的新成员和/或Elmo的员工的支持,等等),则可以显著改进流程,例如学习、对项目的支持等。
请参阅每个Elmo示例(位于C:\GMAS\MyGMASCProjects作为开发软件安装过程的一部分)。
2 函数、变量和常数
函数、变量和常量的命名和使用应遵循以下准则:
-
函数的命名应该类似于文件。例如:MainTimer ()。
-
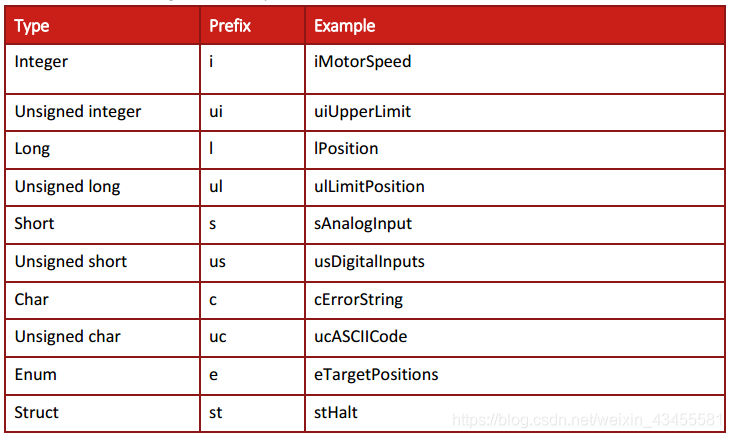
变量的名称也应该类似,但是应该在前面加上小写的变量类型,如下表所示。例如:iSpeed可以是保存速度值的整数变量的名称。
-
常量应使用以下格式命名:MY_CONSTANT(所有大写字母,每个单词之间“_”)。
-
对于由多个函数访问的变量,允许并推荐使用全局变量。它们应该在C文件的顶部定义(在大多数情况下,是项目的主C文件)。
全局变量的名称应该在其前缀处附加一个“G”,例如glPosition、gcErrorString。这将向程序员表明该变量是全局的。
3 C and Header Files
C文件内的源码应遵守以下指引:
- 主项目的C文件应该以描述应用程序的一些注释行开始。
- 每个函数前面都应该有一些注释行,提供关于函数的尽可能多的细节(它做什么、输入和输出参数、谁编写的、版本等等)。
- main()函数应该是项目主C文件中的第一个函数。它通常应该被定义为:Void main(),意思是,在执行项目时不需要任何参数,在退出应用程序时不向操作系统返回任何值。 如果参数应该从操作系统传递到应用程序代码,或如果应用程序在退出时向操作系统返回值,请参阅示例目录中包含的相关示例(C:\GMAS\MyGMASCProjects)。
- 一个C文件应该只包含必要的头文件。
- 代码不应该包含数字。常量应该在相关的头文件中定义,常量的值应该只在头文件中定义。例如:HOMING_SPEED。
- 这包括像“0”和“1”这样的值。定义OK和NOT_OK(和/或类似地,如TRUE,FALSE)。
- 代码应该垂直对齐并正确嵌套。
- 使用Tab而不是空格来垂直对齐代码。
- 开括号和闭括号(“{”和“}”)应分别写在单独的一行中。
- 注释(文件和函数标题、内联注释、行尾注释等)应该使用本章末尾示例代码所示的格式(或样式)。
4 包装函数(Wrapper functions)
包装函数文件是包含一组逻辑相关函数的文件(实际上是函数库)。每个函数都被编写成“隐藏”相对复杂的过程/代码,并为程序员提供一个简单的接口。一个例子可以是包装函数文件,其中包含一组用于运动的函数。例如,它可能包含像MyMoveAbsolute(dSpeed, dPosition)这样的函数。这个函数有一个非常简单的接口(可以很容易地用来创建一个运动,因为您只需要输入速度和位置的值),但是在内部,它将使用不那么简单的接口PLCopen运动函数,包括参数初始化、有效性检查等。
包装器函数有助于保持主代码更干净、更优雅。在读取(和调试/修改)主代码时,我们希望能够很容易地看到实现的机器序列(程序流),而这只有在代码的细节隐藏在函数调用中时才能做到。
调用名为“MMC_InitSystem(…)”的函数将比在主代码中在线放置系统初始化的详细代码(轴、通信等)清楚得多。因此,如果需要,开发人员可以对包装器函数中的详细代码进行深入分析。
包装函数可用于各种建议:
- 隐藏复杂和/或不重要的代码段
- 隐藏重复的代码段
- 为重复调用函数提供更简单的接口(“快捷方式”)
4.1 隐藏复杂和/或不重要的代码段
在为复杂的同步分布式系统编程时,总体代码通常包括相对复杂、较长和“无趣”的代码段。这些部分通常处理系统初始化、管理、错误处理、终止等的详细实现。这段代码不一定与项目的主要目标相关——执行机器序列。
如果这些代码段留在主代码中,主代码就会变得过于复杂,从而阻碍对最重要内容的合理读取和跟踪;实现了机器的顺序和逻辑。
包装器函数可用于隐藏这些代码段。这些包装器函数由Elmo提供,因此我们的示例可以更容易地阅读和理解。
4.2 隐藏重复的代码段
重复的代码段,即使不复杂,即使对理解程序流(机器序列)很重要,也可以隐藏在包装器函数中,以最小化主代码长度。
4.3 提供更简单的界面
一些内置的Platinum Maestro函数块函数具有复杂的接口,即具有多个参数的函数,其中一些参数也具有复杂的结构。这种复杂性对于维护与PLCopen Motion之类的标准的兼容性以及支持该函数的全面运行是必要的。
然而,在大多数情况下(您的情况可能就是其中之一),应用程序不需要函数块的完整操作,而只需要函数块接口的一小部分。在这种情况下,程序员(或其示例中的Elmo)可以定义一个新函数,该函数与程序具有一个简单的接口,并在内部为其余的函数参数假定一些默认值。
一个例子可以是一个简单的运动函数(通常位于一个包装函数文件中,其中包含许多用于简单运动的函数),例如MoveAbs(iPosition)。这个函数只接受一个参数,即所需的位置,并使用PLCopen运动函数块的完整机制创建到这个目标位置的运动。它将为额外需要的参数(如速度和加速度)假定默认值,或者保留最近使用的值——这取决于MoveAbs()函数的实际编码(当然,包装器函数的用户必须清楚地记录这一点)。
假设用户理解包装器函数所采取的默认操作,那么调用MoveAbs()要比调用标准的PLCopen Move Absolute函数容易得多。
另一个例子可以是:
int iEndMotionReason = MoveAbsWaitEndMotion(iPosition)
这显然是一个创建运动并等待其结束的函数(不管原因是什么;达到目标,限制,误差,…)。函数只在运动结束时返回,返回运动结束的原因。
通常,包装器函数是函数库,这些函数旨在简化主要代码(机器序列)的编写和读取。
Elmo提供了一组包装函数文件,作为其示例集的一部分。您可以定义并创建自己的一组包装器函数文件(从零开始或基于Elmo的一个示例),以适合您的项目和写作风格。
包装函数文件应遵循以下准则:
- 不应该修改Elmo提供的包装函数文件。相反,如果需要修改,则将文件复制到一个新文件并修改它。
- 每个包装函数文件应该包含一组逻辑相关的函数。每个函数应该有一个简单的用户界面。
- 应该为每个包装器函数文件命名,以反映其内容。例如:SimplifiedSynchronizedMotions.c。
- 每个包装器函数C文件都应该有一个头文件(*.h),名称相同。头文件将包括与包装器函数文件相关的定义,以及其中包含的包装器函数的原型。
- 由Elmo提供的通用(而不是特定于示例)包装函数文件位于G:\GMAS\GMASCWrapperFunctionsFiles之下。
- 更多特定于给定项目/应用程序的包装器函数文件应该位于项目目录中。
- 如果包装器函数获得许多假设(默认值、保留以前的值等),这些假设必须为用户清楚地记录下来。
- 强烈建议包装器函数(除非它被写到非常特定和固定的项目中)不包含参数的默认值。例如,一个简单的错误可能是假设一个简化的运动函数的值为100000(例如)。对于给定的示例,这可能非常有效,但是对于将来没有人会记住这个默认决策的示例,这就不合适了。建议使用其他解决方案(例如,在文件中包含一个包装器函数,用于从主代码初始化所有这些默认值)。喜欢的东西:
InitMotionsWrapper(iSpeed, iAcceleration, iDecelaration, iMode, iSmoothing, …)
然后程序员可以自由地使用MoveAbs(iPosition)等。
5 实现机器序列
处理机器序列的程序应满足以下要求:
- 能够并行处理多个序列。例如,假设铂金大师应该使用三轴机器(例如X, Y和Z),以及一个自动加载器,该加载器应加载和卸载对象到/从机器,本身由4个轴组成。这些子程序集中的每一个都应该并行控制,具有独立的序列,但必须同步。白金Maestro的用户应用程序应该能够并行执行这两个序列(机器和加载程序),并在需要同步时同步它们。
- 能够处理后台系统进程,如验证读取,处理状态,突发事件等。许多任务应该由应用程序连续地或更精确地、定期地处理。这些任务应该独立于机器状态和/或操作模式来执行。
- 能够随时准备接收具有合理响应时间的传入通信(通常是来自主机的通信),更重要的是,具有预定义的有限响应时间。应用程序对于任何给定的任务都不应该太忙(就时间而言),并且应该始终能够获得并正确响应传入的通信。
- 决定论。应用程序应该执行相同的序列,响应传入的消息,并以一种确定的方式创建到设备网络的通信,几乎没有延迟或抖动,并且在预定义的限制内。
- 可维护性。最后,但同样重要的是对程序的简单开发和维护的需求。程序的组织方式必须能够方便地编写、控制和维护复杂的序列。
有许多方法可以编写满足上述要求的程序。例如:多任务处理和中断。
Elmo在开发用户应用程序方面拥有丰富的经验。我们在多年的客户支持和用户应用程序的内部开发过程中获得了这种经验。
根据这一经验,我们得出结论:为机器序列编写程序的最佳方法是 基 于 状 态 机 的 结 构 基于状态机的结构 基于状态机的结构。这种编程结构最优地满足了上述要求。
使用状态机结构,程序不需要多任务处理(对于大多数程序员来说,这是一个复杂的结构,显然对于大多数运动控制工程师来说),在大多数情况下甚至不需要中断。所需要的只是理解状态机编程的基础。然后代码就变得非常易于开发和维护。
Elmo提供的所有程序示例都使用状态机结构实现。强烈建议使用这种编程结构。它将使Elmo的例子更容易使用,允许Elmo的支持团队提供更好更快的支持。此外,它还将缩短投放市场的时间,并显著降低开发风险。
这是开始解释状态机编程结构细节的一个很好的切入点。这一解释并不简单,而且是以一种系统的程序提出的。
5.1 main() 程序结构
白金Maestro用户应用程序main()函数的推荐结构如图1所示:
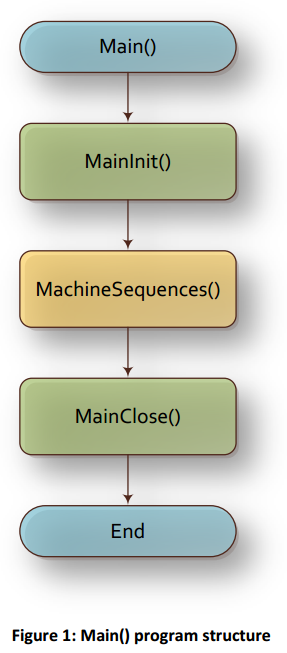
main()以对MainInit()的调用开始,MainInit()是一个函数,它执行所有程序和系统的初始化(稍后将在手册示例中详细介绍)。在完成所有初始化之后,调用MachineSequences()函数。该函数有意地启动机器序列和运动的执行。在机器运行过程中,函数不会返回到main(),直到程序请求终止(由于错误,用户请求关闭,等等)。当机器操作完成时,machine Sequences()函数返回main(), main()调用MainClose()函数来关闭程序终止之前需要关闭的所有内容。
这是程序的main()函数。尽可能简单和干净。现在我们进入函数的作用是:查找机器序列的实现,使用状态机结构。
5.2 MachineSequences()函数
图2给出了MachineSequences()函数的Elmo推荐结构。
请注意,红色的代码块是一段需要尽可能快地执行的代码,不应该包含任何执行时间或延迟相对较长的进程。当我们深入研究程序结构时,这将变得特别相关。显然,它不应该包含任何无休止的循环或任何等待系统进程结束的过程。一个红色的块应该包含一段代码,它无条件地执行有限大小的代码,没有延迟或等待。
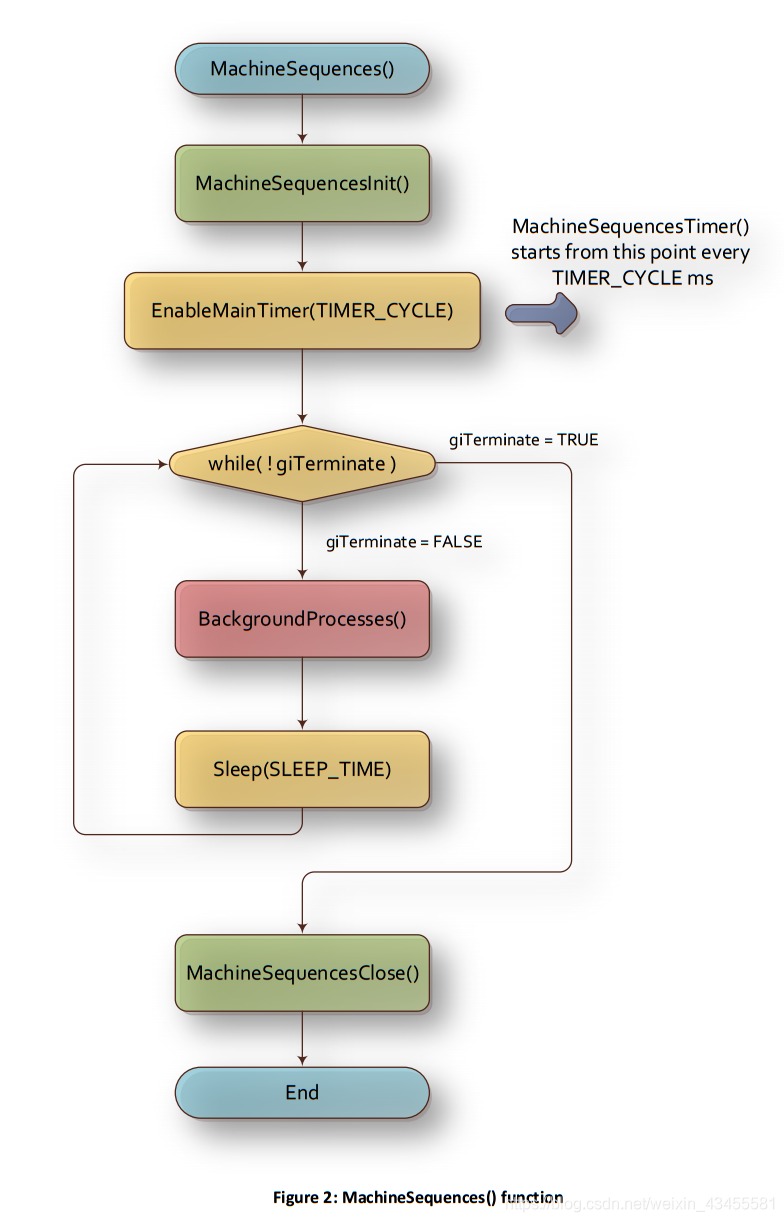
MachineSequences()从调用MachineSequencesInit()开始。此函数初始化所有变量,以激活MachineSequencesTimer()并管理状态机(参见图2)。
后立即,MachineSequences()调用EnableMainTimer (TIMER_CYCLE(记住,格式(CAPITAL_LETTERS)是指一个常数由程序员定义的头文件))开始执行MachineSequencesTimer()函数来定义,它将自动执行的操作系统(OS)每个TIMER_CYCLE毫秒作为这些描述的典型值,假设一个TIMER_CYCLE = 20毫秒。
从现在开始,OS每隔20ms激活MachineSequencesTimer()。这个定时器函数实际上处理和管理状态机,如下所述。
MachineSequences()函数现在进入一个无限的while循环,等待一个全局变量
(giTerminate)表示MachineSequencesTimer()请求终止程序。当启动MachineSequencesInit()函数时,giTerminate变量将初始化为FALSE,如果需要(程序可能永远不会终止),由MachineSequencesTimer()函数可选地将其设置为TRUE。
一般来说,这个无尽的while循环只需要等待终止请求。为了不只是为了在循环中运行而加载CPU,在循环中插入了Sleep(SLEEP_TIME)。SLEEP_TIME的一个典型值是100ms,这意味着(在我们的示例中)这个后台循环大约每5个周期激活一次计时器函数(该函数每20ms激活一次)。
注意定时器方法是一种精确的方法,用于在每个给定的周期内创建对定时器函数的调用。Sleep()方法并不精确,但是对于这个空闲循环,计时精度不是问题。
最后,由于我们这里有一个后台循环代码,它以相对较低的速率周期性地激活,所以我们可以使用它来执行一些时间不那么关键的流程,这可能是应用程序所需要的。进程,您可能不希望将其包含在由定时器函数确定执行的主状态机中。这就是为什么我们有选择性在这个while循环中使用BackgroundProcess()函数。
在请求终止之后,while循环立即结束,然后调用MachineSequences()来关闭需要关闭的所有内容,然后返回main()函数来终止程序。为什么用引号“立即”?因为响应时间可能与此循环的SLEEP_TIME一样长。然而,在处理终止请求时,响应时间不应该成为问题。
现在,我们有一个在后台“缓慢”循环的程序——一个几乎是空闲的循环,同时触发一个计时器函数MachineSequencesTimer(),并在每个TIMER_CYCLE ms(在我们的示例中是20ms)中执行状态机。让我们深入研究MachineSequencesTimer()函数。
5.3 MachineSequencesTimer()函数
图3给出了一个典型的MachineSequencesTimer()函数的一般结构。
为什么“一般”?因为它没有显示状态机的详细信息。这将在稍后介绍。首先,了解MachineSequencesTimer()函数的一般结构。
初始化时,在计时器事件(每个TIMER_CYCLE ms,如上所初始化)上
函数的作用是:触发MachineSequencesTimer()。它的第一个操作是调用ReadAllInputData()函数。
函数ReadAllInputData()是一个依赖于应用程序的函数。它的任务是读取状态机可能需要的所有输入,并将它们复制到“外部世界”无法访问的变量中。
这将确保在此计时器事件期间执行的所有状态机代码将使用相同的输入变量值。
为什么需要这样做?
由于计时器事件不一定与“外部世界”操作同步,例如,主机可以访问MODBUS内存并修改国家机器代码。同样,白金大师核心可以获得一个新的读数,例如驱动器的速度通过设备网络。
因此,外部环境可以在MachineSequencesTimer()执行期间更改这种“输入数据”,从而导致代码流的操作不一致。首先需要将所有必要的值复制到“镜像变量”中,然后才开始使用这些镜像变量,这些镜像变量将保持不变,直到下一次计时器事件。
这正是ReadAllInputData()函数的任务。根据应用程序的不同,它应该访问所有必要的变量(MODBUS内存的变量,从Platinum Maestro固件内核等),并将它们复制到“镜像变量”中。
在MachineSequencesTimer()的开头,使用ReadAllInputData()函数读取和创建所有必要的“外部世界”变量的副本是非常重要的,并且在状态机代码期间只使用这些副本或镜像。这将避免同步和不一致代码行为中的困难。
同样,状态机不应该直接写入“外部世界”。状态机代码应该设置内部变量(状态机的变量,不在状态机外部使用)来反映“代码决策”或编写到“外部世界”的需求。
只有当通过所有状态机(稍后将详细解释)时,才会执行MachineSequencesTimer()调用WriteAllOutputData()(图3),它使用这些内部变量来编写应该写入外部世界变量的内容(MODBUS、Platinum Maestro固件核心等)。
程序员应该注意正确地更新“external world”变量(WriteAllOutputData()函数内部),在某些情况下,写入的顺序可能很重要。例如,(程序员应该)仔细定义通过MODBUS的主机握手,以确保同步和完全一致的通信。
“external world”变量的写入不应从内部执行
机器只在WriteAllOutputData()函数中声明代码,以确保正确的同步和一致操作。
现在让我们看看状态机本身。在下面的图3中,您可以看到,在一般情况下,MachineSequencesTimer()函数可以处理多个独立状态机。例如,对于需要独立管理的机器的不同子系统。
每个状态机都有自己的一组状态变量,并且每个状态机都是独立管理的(尽管特定的实现可以用另一个状态机的状态来约束给定状态机的行为,这是特定于应用程序的)。
例如,每个轴可以有自己的状态机。
实现的另一个例子是拥有XYZ的状态机和第二个状态机为机器的装载机机构。两者都是独立的,尽管可以在第二个状态机等待进程完成后再启动自己的进程,例如:

当然,这只是一个简化的处理,但是它解释了为什么处理两个独立的状态机更容易,如图3所示(显示最多N个状态机的一般情况)。上面的示例还说明了为什么一个给定的实现可能需要用另一个状态机对给定状态机的行为进行条件设置(它们是独立管理的,buy可能有条件地执行)。
图3显示了每个状态机使用以下变量(第一个状态机的“N”从1开始)。
giStateN
定义状态机的当前状态。它通常由
MachineSequencesInit()函数(见上面),然后可以通过MODBUS(执行任务的主机请求)或由状态机本身修改它,同时它从一个状态执行到另一个状态(流程的执行)。
giPrevStateN
将状态值保持为在前面执行MachineSequencesTimer()函数时的状态值。
使用这个变量,状态机代码(将在后面的图中显示)可以检测giStateN值是否是一个“新”状态,并相应地执行(有关详细信息,请参阅后面的内容)。它通常与giStateN变量一起初始化。
giSubStateN
如果需要子状态机(请参阅后面的详细信息),则此变量定义子状态机的当前状态。它通常由MachineSequencesInit(0函数)初始化——就像上面的变量初始化一样。
但是,它也会被MachineSequencesTimer()在每次请求一个新状态时重置为零(或者更好的说法是:第一个子状态的值)(稍后会详细介绍)。
这些变量用于管理状态机和子状态机,我们将在后面的图中看到。
为什么需要子状态机?
假设一个XY轴的状态机。同时,假设需要管理以下任务:HomeXY, ScanObject和GoToIdle。状态机基本上有三种状态:HOME_XY,SCAN_OBJECT和GO_TO_IDLE。
但是,执行HomeXY本身是一个由一系列运动和条件组成的过程,所以它也必须作为状态机来实现。这将作为子状态实现机器。
在对XY寻的过程中,主状态机(下一图中出现的状态机)
函数)将处于HOME_XY状态,而子状态为Machines
(我们将在后面看到图)将进入寻的各个步骤。
理论上说(实际上,甚至几乎),这种结构的并行运行多个独立国家机器(如第二图所示)和嵌套的国家机器在另一个(如前所述,我们将会看到在后面的数字)可以扩展并适合应用程序的要求。
在下面的图中,我们展示了1…N个并行状态机,深度只有两个状态机(主状态机和一个子状态机)。这只是为了简单的数字。但是,可以增加深度,并且所需的变量名称和处理的更改是次要的,应该很容易由经验丰富的程序员处理。
注意,虽然理论上可以实现无限的并行性和深度,但程序员有责任确保最坏情况下的执行时间
MachineSequencesTimer()函数将比TIMER_CYCLE时间更短,以便不饱和白金Maestro CPU的处理负载(这是可以的,如果代码是按照本章中描述的准则编写的,因为白金Maestro处理器可以处理更多的东西,比任何实际应用程序都需要的状态机器)。
记住我们在本章前面描述的giTerminate变量,应该很清楚,任何给定应用程序需要的任何状态机都可以设置这个全局变量,以便请求(来自MachineSequences()函数)将应用程序终止回操作系统。
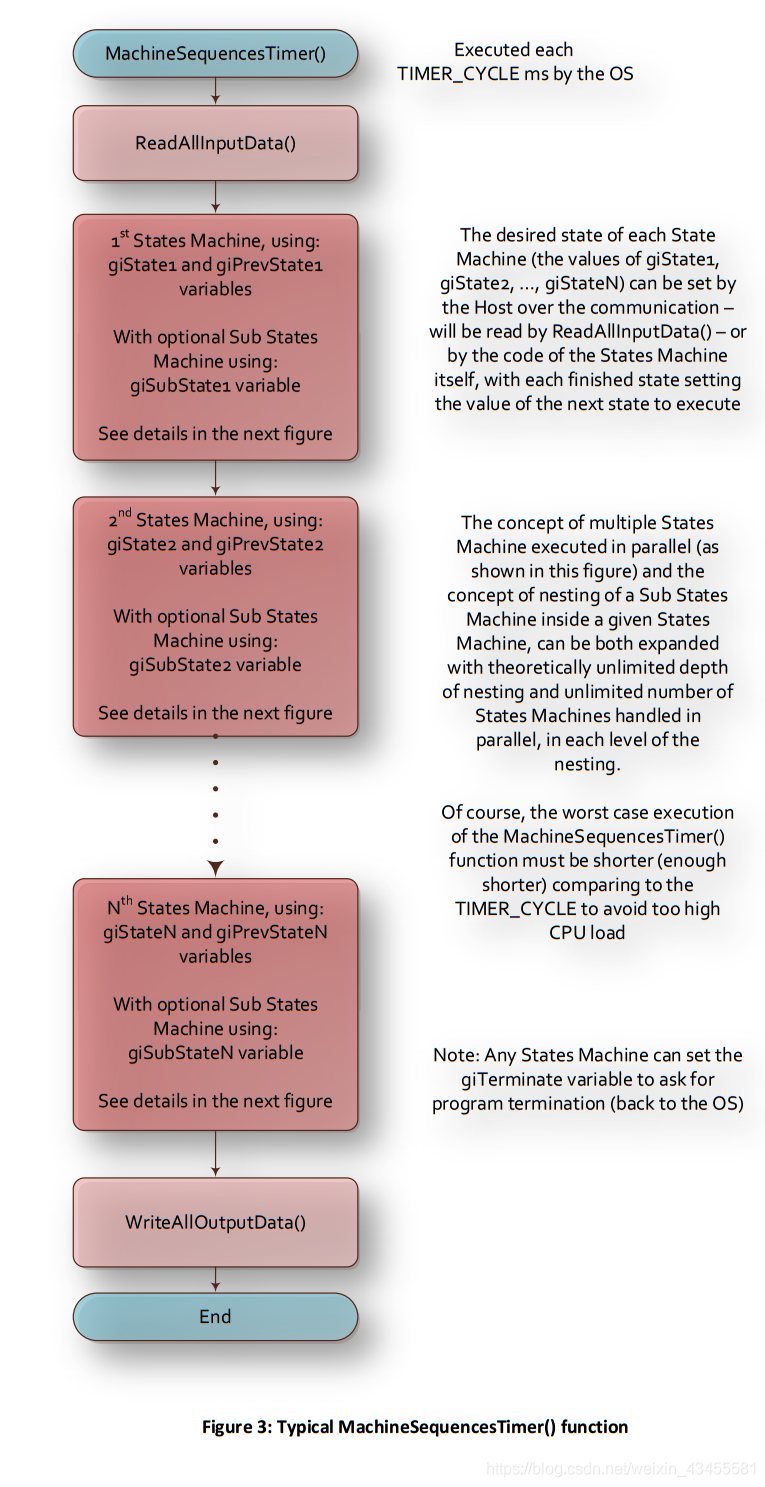
每个状态的期望状态机(giState1、giState2、…、giStateN的值)可以由主机通过通信进行设置——将由ReadAllInputData()读取——或者由状态机本身的代码读取,每个完成的状态设置下一个要执行的状态的值
多重状态的概念并行执行的机器(如图所示)和子状态嵌套的概念,在给定状态下的机器,既可以扩展与理论上无限深度嵌套和无限数量在嵌套的每个级别上并行处理的状态机。
当然,与TIMER_CYCLE相比,MachineSequencesTimer()函数的最坏执行情况必须更短(足够短),以避免过高的CPU负载
注意:任何状态机都可以设置giTerminate变量来请求程序终止(回到OS)
下图显示了其中一个状态机中的代码细节:
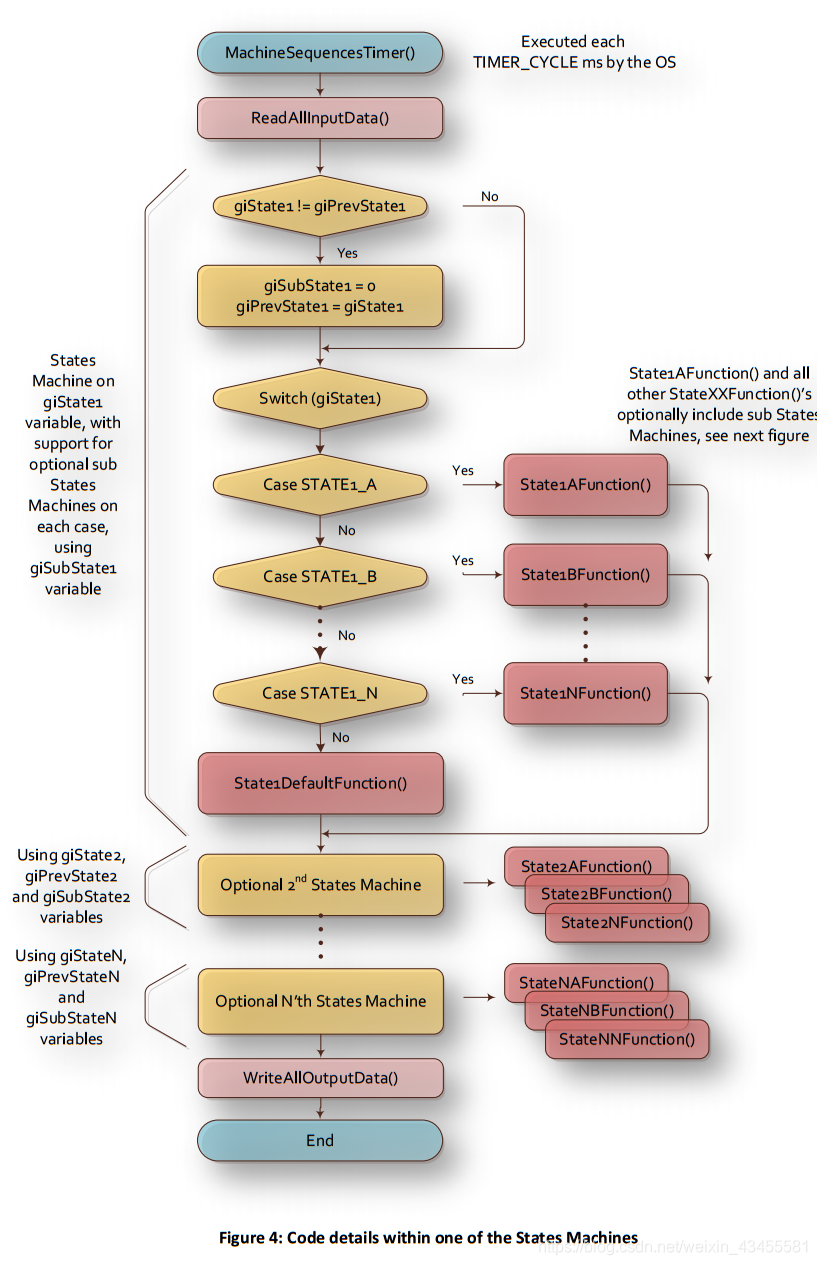
State1AFunction()和所有其他StateXXFunction()可选地包含子状态机,参见下一个图
States Machine on giState1 variable, with support for optional sub States Machines on each case, using giSubState1 variable
在giState1变量上使用状态机,在每种情况下使用giSubState1变量支持可选的子状态机
Using giState2, giPrevState2 and giSubState2 variables
Using giStateN, giPrevStateN and giSubStateN variables
请注意,为了保持简单性,本图中省略了处理重入和终止请求(与前一个示例相比)。当然,如上所述,这两个管理过程仍然作为MachineSequencesTimer()函数中的前两个任务来处理。
您仍然可以看到ReadAlllnputData()和WriteAllOutputData()函数,并且您仍然可以看到可选的第2到第n个状态机的块,但是现在第1个状态机的处理过程已经详细介绍了。
它从处理giSubState1的重置(如果需要,这是一个新的giState1启动时的情况)和处理giPrevState1开始。
为什么需要这样做?
giState1的新值可以由主机(通过MODBUS)或状态在外部定义
机器本身。一般来说(如果需要,给定的应用程序可以修改此行为),当一个新的主状态启动时,您希望相关子状态为“start from-zero”。这就是为什么如果giState1获得新值,giSubState1将被清除。
在此处理之后,将对giState1的值进行简单的切换。每种情况都需要适当的函数。
虽然不应该发生缺省情况,但也应该处理缺省情况(可能使用一些错误消息,但什么也不做)。
注意:请注意为每种情况调用的特定函数都是红色的。这意味着,如上所述,它不应该包含任何“等待”或“延迟”。它应该执行请求并返回。
如果一个等待是必要的(例如,运动的等待结束),它应该被实现为一个状态。每一次状态机被执行,它将到达与此状态相关的代码并检查运动结束。
如果轴仍在移动,代码将返回不改变状态值的状态机将在下一个计时器事件中返回相同的代码。如果运动结束,代码应该正确地更改状态值,以便在下一个计时器事件执行时自动执行下一个状态(整个序列中的下一个步骤)。
重要的是要注意并理解这意味着这个方法(状态机)中时间的最小分辨率是TIMER_CYCLE。例如,如果是20ms,则意味着序列可以按不小于20ms的步骤进行管理。
同样,在最坏的情况下,响应时间(或检测事件并对其作出响应的时间)可能高达20ms。甚至有时是TIMER_CYCLE时间的两倍(一个周期检测,一个周期响应)。
它是状态机代码结构方法的唯一缺点,具有许多优点。对于非常简单的应用程序,处理非常简单的过程或序列,如果需要最终的快速响应时间,可以考虑不使用状态机结构。
正如下面所解释的,支持状态机嵌套,甚至是一种实际需要(至少是两种状态机的深度)。因此,图4中出现的每个case函数(比如在giState1 = STATE1_A时执行的State1AFunction()函数)都可以管理一个Sub状态机本身。如图5所示:
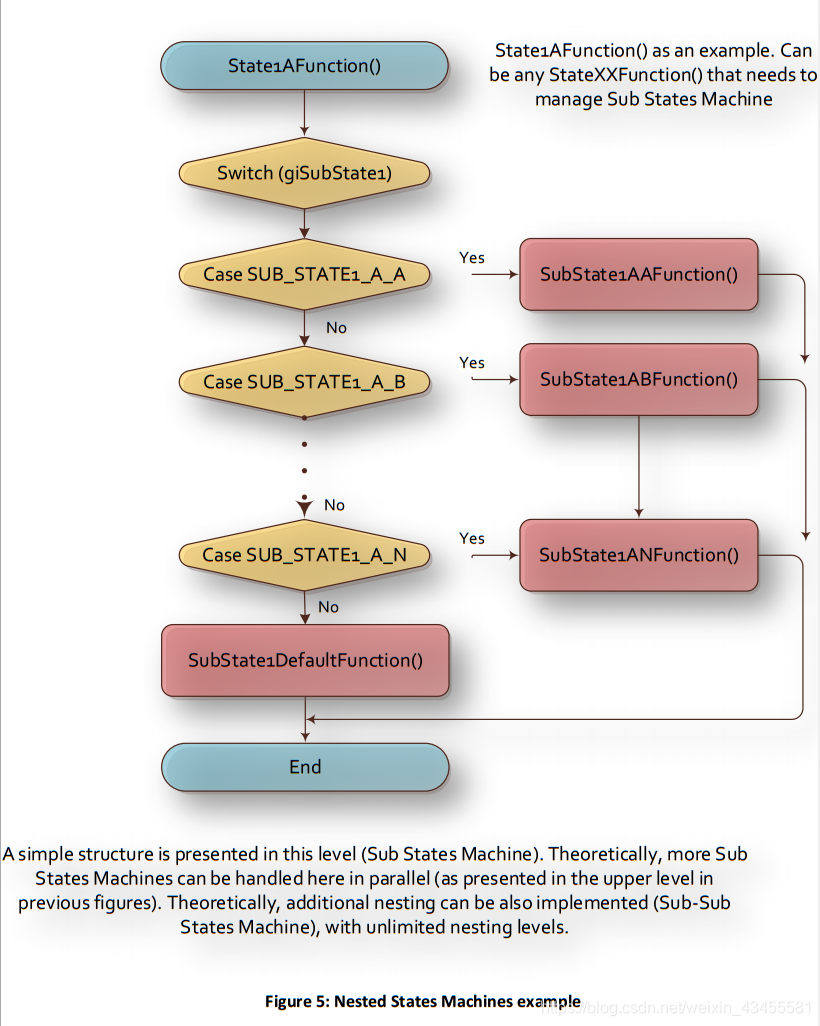
State1AFunction() as an example. Can be any StateXXFunction() that needs to manage Sub States Machine
以State1AFunction()为例。任何需要管理子状态机的StateXXFunction()都可以
A simple structure is presented in this level (Sub States Machine). Theoretically, more Sub States Machines can be handled here in parallel (as presented in the upper level in previous figures). Theoretically, additional nesting can be also implemented (Sub-Sub States Machine), with unlimited nesting levels.
在这一层次(子状态机)给出了一个简单的结构。理论上,这里可以并行处理更多的子状态机(如前面图中的上层所示)。理论上,还可以实现附加嵌套(子-子状态机),嵌套级别不限。
请注意,在这个级别中没有处理任何PrevState变量,因为我们已经定义(仅在我们的示例中)深度只有两个嵌套状态机。所以没有子状态机…
实际上,这就结束了对状态机编程结构的解释。在本章中不久(在下一节处理错误之后),您将发现有一节介绍了一个示例代码。它基于一个简单的状态机结构,我们希望这个结构能够帮助、理解和实现这种方法。
在这个示例代码中,您将发现各种状态的实际进程和更多“与应用程序相关”的名称(instead of SUB_STATE1_A_N for example),这将使其更容易理解。
尝试阅读示例代码,并将其与本章更“theoretical”的解释联系起来。您肯定会发现,建议和推荐的状态机概念很容易理解,甚至更容易适应应用程序的需要。
6 处理错误
本章主要讨论函数块调用过程中的错误(由Elmo在GMAS函数块库中提供的函数)。当然,还可以定义许多其他特定于机器的错误,但是这些错误应该按照特定于每台机器的方式来处理,并且通常作为管理机器序列的状态机的一部分来处理(见上面)。
从底线开始,处理错误(在调用函数块期间)是用户应用程序开发人员(用户)的职责的一部分,因为每台机器对不同类型的错误调用不同的响应。
如何检测这些错误?用户把处理这些错误的函数放在哪里?对于处理这些错误,Elmo推荐了哪些好的编程实践?
澄清一下,我们不可能提供一个通用的函数来处理错误,因为每台机器需要不同的错误处理过程。但是,仍然需要定义在何处、何时以及如何调用此类错误处理函数。本章回答了这一要求。
每个函数块函数返回一个返回代码。如果函数块调用执行时没有任何错误,则它的值为0(zero)。如果有错误,返回代码将得到一个与错误类型相关的值。
因此,调用函数块函数的一般代码段应该是这样的(在本例中,它是一个移动绝对函数的调用):
// Inserting the structure parameters:
sMove_Abs_in.fAcceleration = 100000.0; // Value of the acceleration
sMove_Abs_in.fDeceleration = 100000.0; // Value of the deceleration
sMove_Abs_in.fJerk = 2000.0; // Value of the Jerk
sMove_Abs_in.eDirection = MC_POSITIVE_DIRECTION; // MC_Direction Enumerator type
sMove_Abs_in.eBufferMode = MC_BUFFERED_MODE; // MC_BufferMode Defines the behavior of the axis
sMove_Abs_in.dbPosition = 100000.0; // Target position for the motion
sMove_Abs_in.fVelocity = 5000.0; // Velocity in
sMove_Abs_in.ucExecute = 1;
//
rc = MMC_MoveAbsoluteCmd (hConn, iAxisRef, &sMove_Abs_in, &sMove_Abs_out);
if (rc != 0)
{
HandleError();
}
或者,类似的:
// Inserting the structure parameters:
sMove_Abs_in.fAcceleration = 100000.0; // Value of the acceleration
sMove_Abs_in.fDeceleration = 100000.0; // Value of the deceleration
sMove_Abs_in.fJerk = 2000.0; // Value of the Jerk
sMove_Abs_in.eDirection = MC_POSITIVE_DIRECTION; // MC_Direction Enumerator type
sMove_Abs_in.eBufferMode = MC_BUFFERED_MODE; // MC_BufferMode Defines the behavior of the axis
sMove_Abs_in.dbPosition = 100000.0; // Target position for the motion
sMove_Abs_in.fVelocity = 5000.0; // Velocity in
sMove_Abs_in.ucExecute = 1;
//
if (MMC_MoveAbsoluteCmd (hConn, iAxisRef, &sMove_Abs_in, &sMove_Abs_out) != 0)
{
HandleError();
}
用户负责创建HandleError()函数。这个函数可以选择性地获取参数,当然,不同的函数可以在程序的不同位置使用。
然而,应该执行一系列调用的代码变成了if-call(或call-if)列表。这是Elmo正在努力改进的C编程的一个缺点(参见下面)。
有些程序员倾向于使用以下方法之一来绕过这个困难。我们强烈建议不要使用这些旁路。
-
在不检查返回代码的情况下调用库函数。只是忽略它。
这肯定会创建一个更好更简单的代码。使用这种旁路的假设是,代码经过了调试,对库函数的调用中不应该有错误。虽然这是正确的,但是无法确保错误不会在用户没有完全调试的特定序列中发生。在出现错误的情况下,忽略它并继续执行程序,就像没有错误一样(程序假定函数正确且完整地执行了),这将导致意外的机器行为,在某些情况下,这可能是危险和关键的。如上所述,Elmo强烈建议不要使用这种方法。应根据机器的适用性检查错误并作出反应。 -
第二个旁路是将库函数隐藏在用户开发的包装函数中(参见上面)。在这种情况下,包装器函数将没有返回值,例如:
MyWrapperMoveAbs(..); MyWrapperMoveAbs(..); MyWrapperMoveAbs(..);而且主代码确实会变得更简单。
但是,必须注意,调用库函数的包装器函数本身应该按照上面指定的方式处理返回代码。在包装器函数中处理错误会很好(从主代码的角度来看,它是隐藏的),但它会造成另一个困难;在代码的更深层可以正确地处理错误吗?难道我们不希望主代码(主状态机,请参阅本章后面的部分)处理错误,或者至少意识到错误吗?
根据Elmo的经验,尝试使用此方法(将返回代码隐藏在
包装函数)总是以需要从包装函数返回一个值结束,同样,在每次调用一个函数时,都需要在代码中检查这个值(if(…))。
那么,这种if-call(或call-if)结构是必须的吗?
就目前而言,确实如此。然而,Elmo正在开发一个新的基于C的接口,用于其Platinum Maestro FB库中包含的所有功能。使用这个基于C的接口(使用C的独特特性),用户将不需要检查每个函数的返回代码,而是能够调用函数。上述代码行将更改为:
// Inserting the structure parameters:
sMove_Abs_in.fAcceleration = 100000.0; // Value of the acceleration
sMove_Abs_in.fDeceleration = 100000.0; // Value of the deceleration
sMove_Abs_in.fJerk = 2000.0; // Value of the Jerk
sMove_Abs_in.eDirection = MC_POSITIVE_DIRECTION; // MC_Direction Enumerator type
sMove_Abs_in.eBufferMode = MC_BUFFERED_MODE; // MC_BufferMode Defines the behavior of the axis
sMove_Abs_in.dbPosition = 100000.0; // Target position for the motion
sMove_Abs_in.fVelocity = 5000.0; // Velocity in
sMove_Abs_in.ucExecute = 1;
//
MMC_MoveAbsoluteCmd (hConn, iAxisRef, &sMove_Abs_in, &sMove_Abs_out);
sMove_Abs_in.dbPosition = 200000.0; // Next target
MMC_MoveAbsoluteCmd (hConn, iAxisRef, &sMove_Abs_in, &sMove_Abs_out);
这个新的界面将在几个月内可用,并将使白金大师C程序员享受从一个更简单的代码开发。
7 示例代码
下面所示的示例项目只是为了演示上述编程指南的实现而创建的项目。这是一个相当空的代码,除了准备好实现基于状态机的应用程序外,它没有做任何特定的事情。我们在示例应用程序中包含了一些基本状态,以演示变量/状态应该如何命名、初始化和管理。因为它是一个“clean”的项目,所以更容易展示前面几节中描述的所有指南是如何实现的。
您可以致电Elmo office来接收示例项目代码(它也可能包含在Elmo PC套件环境安装,在这种情况下,您应该能够在您的计算机上找到它,位于与下图相同的位置。
下面是示例项目目录的快照。您可以看到文件夹的位置和名称、C和头文件的名称(包括包装器函数),它们总是成对的。
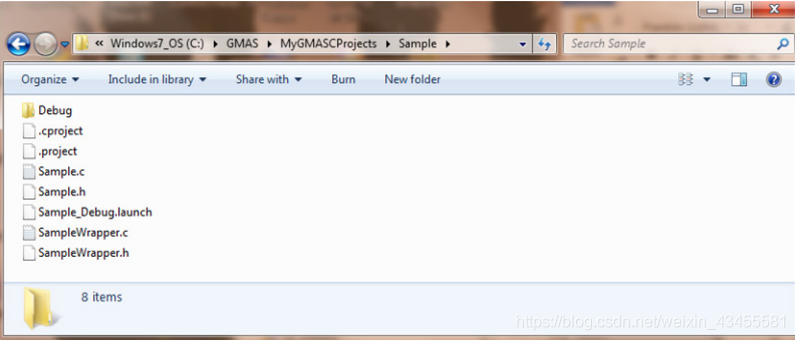
研究Sample.c (使用Eclipse) , 项目的主源文件,我们可以看到文件的头文件,描述了项目、文件、版本、日期和应用程序的简短描述。然后是包含文件(系统文件、Elmo MMC库文件和项目的特定包含文件)。
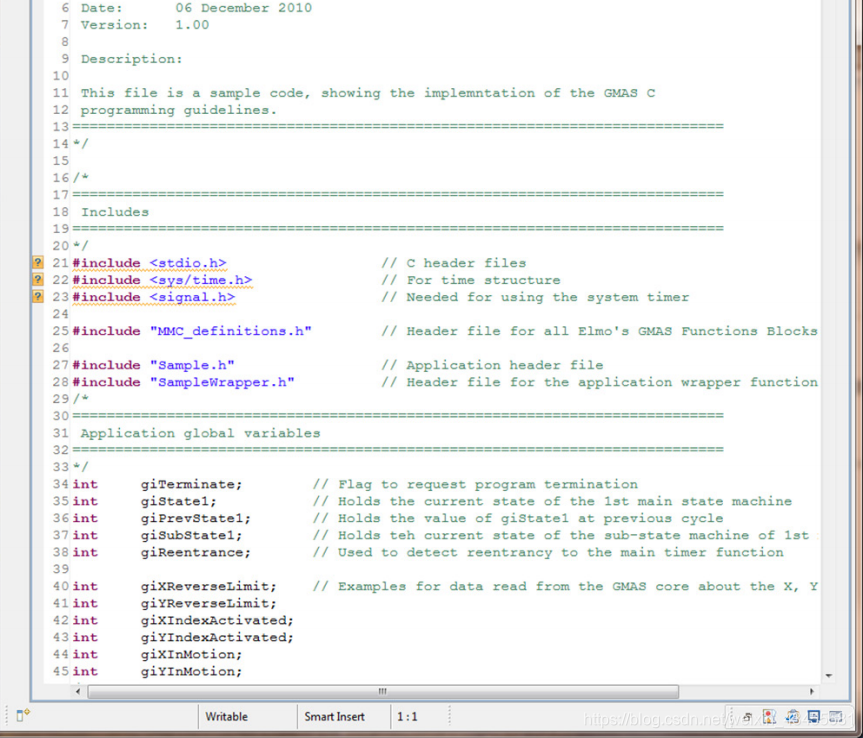
包含文件后;使用上面定义的命名约定定义了全局变量。变量的定义很清楚,有一个简短的解释,最好每行一个。变量的初始化可以发生在这个阶段(作为定义的一部分),但是我们更喜欢在适当的初始化函数中执行所有初始化,如下一节所述。
在应用程序全局变量之后,我们立即定义了MMC函数块接口所需的结构变量。在示例示例中,这些结构作为定义的一部分初始化。我们建议将其作为初始化函数的一部分执行,如前面几节所建议的那样。
我们建议使用全局变量,尽管应该谨慎使用,因为它允许在应用程序代码的任何地方访问这些变量,避免了为每个函数使用多个参数。
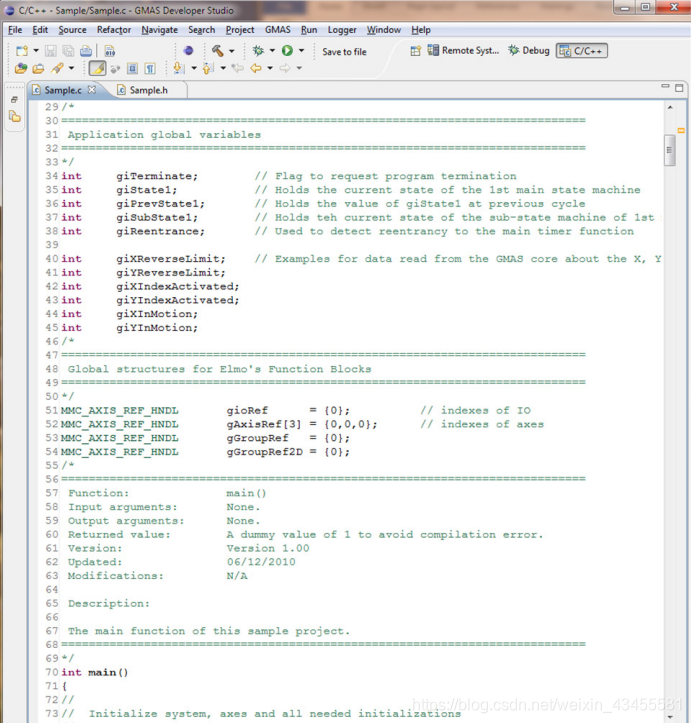
在定义了所有全局变量之后,main()函数就出现了。请注意main()函数上面的注释头,以及代码中任何其他函数上面的注释头。它提供了关于函数的详细信息,如版本、输入/输出、描述等。
main()函数的类型是“int”(尽管在本例中没有返回值),因为Eclipse编译器要求使用这种函数类型。
main()函数与上面流程图中显示的一样简单:初始化、执行机器序列和关闭。注意注释的格式,因为在整个样例项目代码中使用了相同的格式。
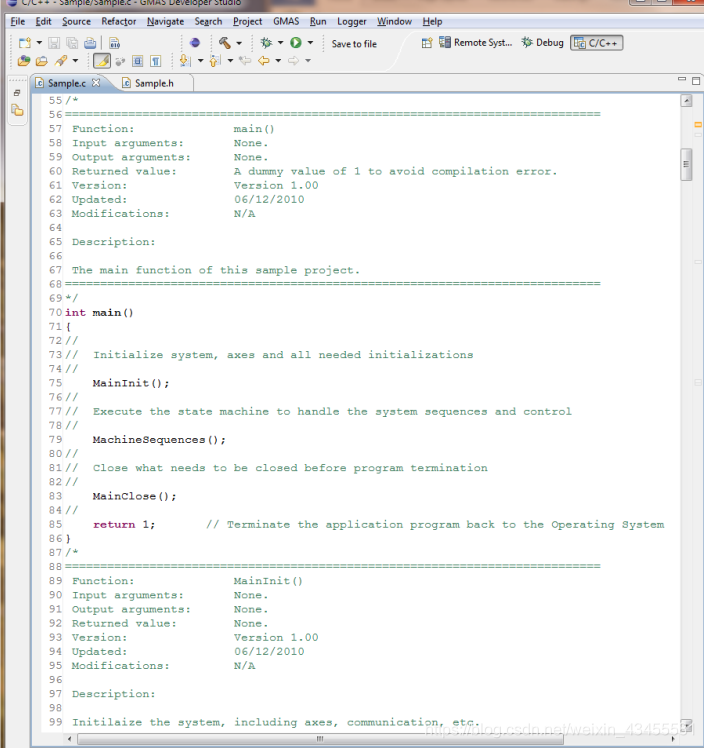
空的main初始化和关闭函数刚好出现在main之后。它们将填充与应用程序相关的代码。初始化函数可用于初始化通信和轴,而关闭函数可用于关闭它们、关闭日志文件、将一些消息打印到标准输出等。
在这些函数之后,我们看到MachineSequences()。它以类似的方式记录和注释。实际上,它是一个非常简单的函数,正如本章流程图中描述的那样。这些细节“隐藏”在特定的函数中,如下图所示的MachineSequencesInit()和EnableMachineSequencesTimer()。
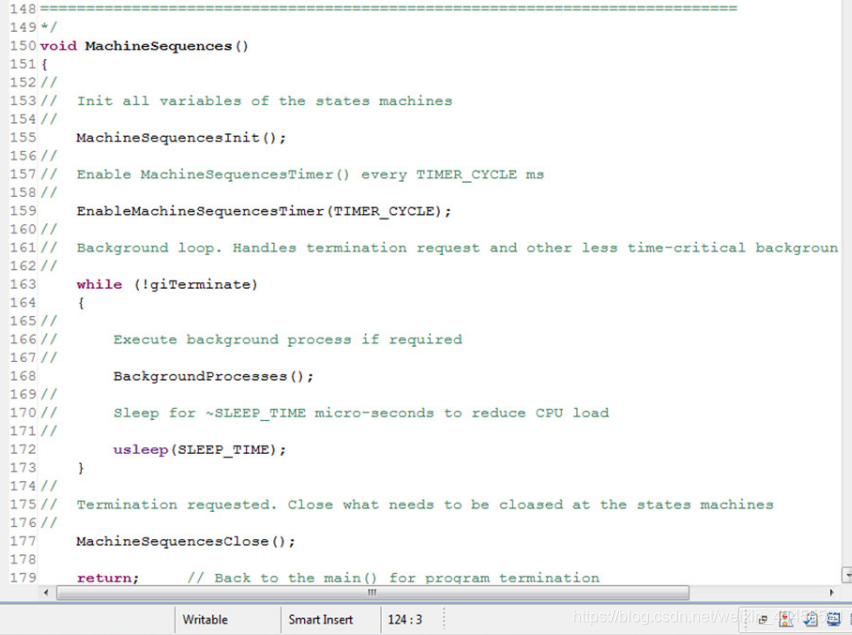
这个函数后面跟着它调用的函数(文件中出现的各种函数的顺序是它们将被调用/使用的顺序),从main()到它调用的其他函数,依此类推。
MachineSequencesInit()初始化管理状态机所需的所有变量。注意,使用的是常量而不是数字(例如IDLE和not 0),如上面的编程指南所定义的那样。
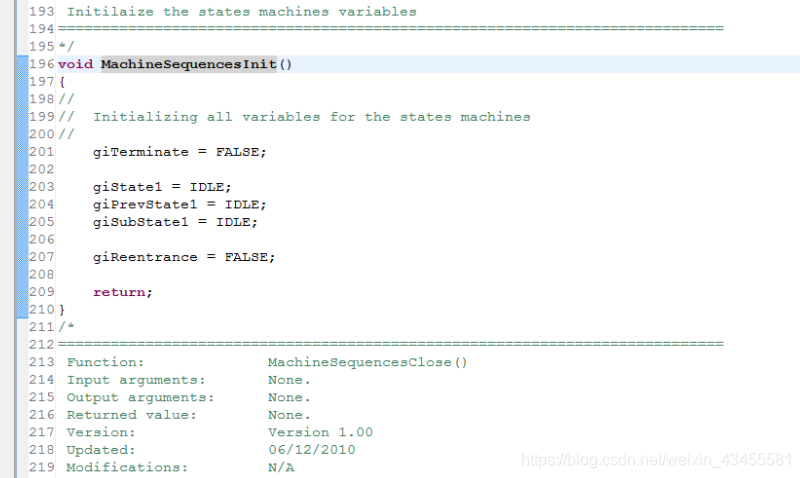
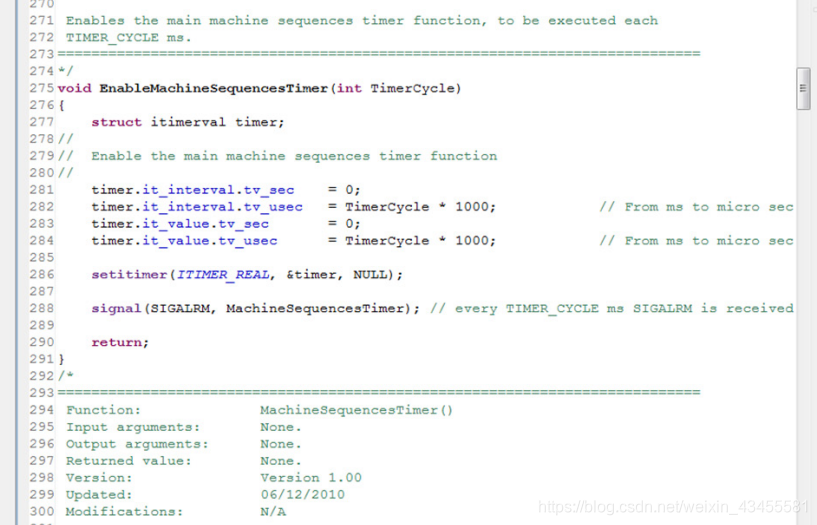
省略一些空函数(前面几章描述了它们的任务),下一个有趣的函数是EnableMachineSequencesTimer()。它使用系统函数来启用计时器,并定义计时器定期触发的函数。除非需要非标准行为,否则用户不应该更改此函数。
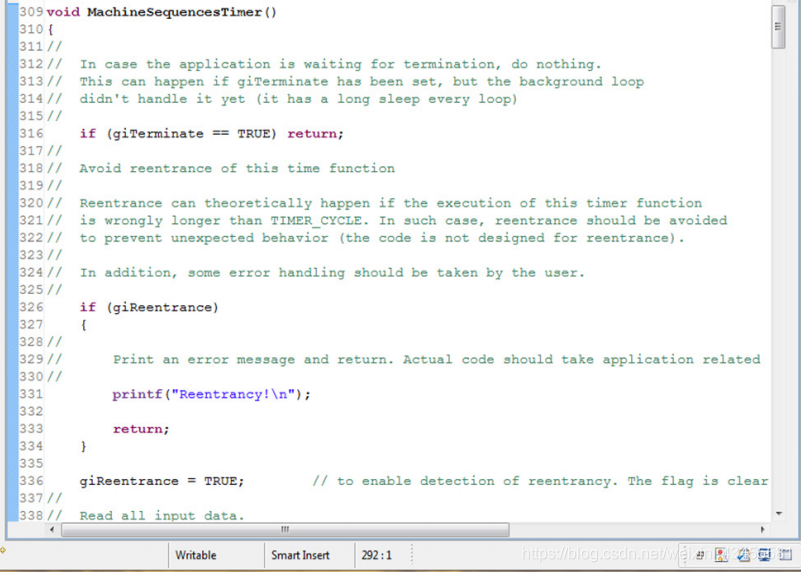
下一个函数是MachineSequencesTimer()。实际上执行机器序列(状态机)的是定时器周期性触发的函数。它首先检查要求终止,如果重新进入错误发生。如果一切正常,则收集输入数据执行状态机和主状态机所需的所有“外部”数据。
然后,下一个阶段是…
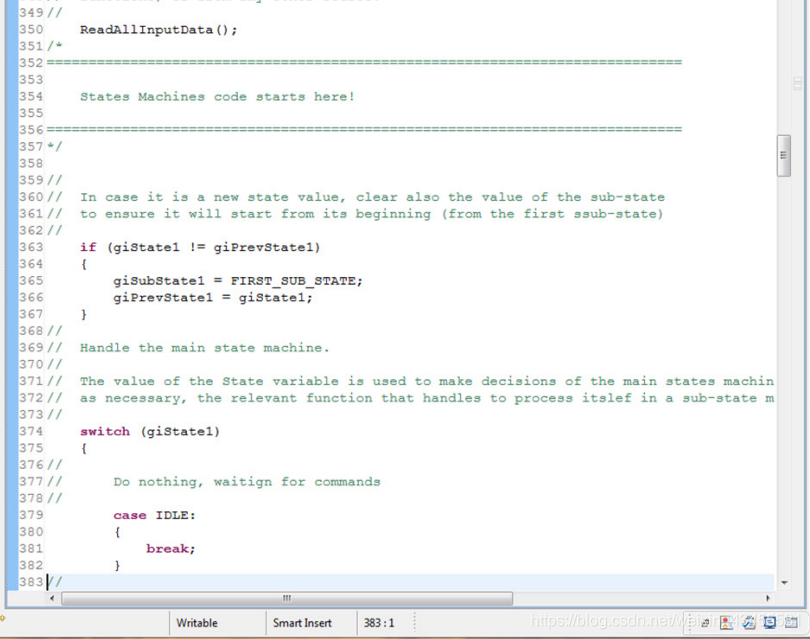
主状态机的处理与我们在上面的流程图中描述的完全一样。在示例项目中,您可以看到主状态机支持两种状态(两个“任务”):XY_HOME和XY_MOVE。每个状态依次处理子状态机,子状态机将执行执行任务所需的操作序列。
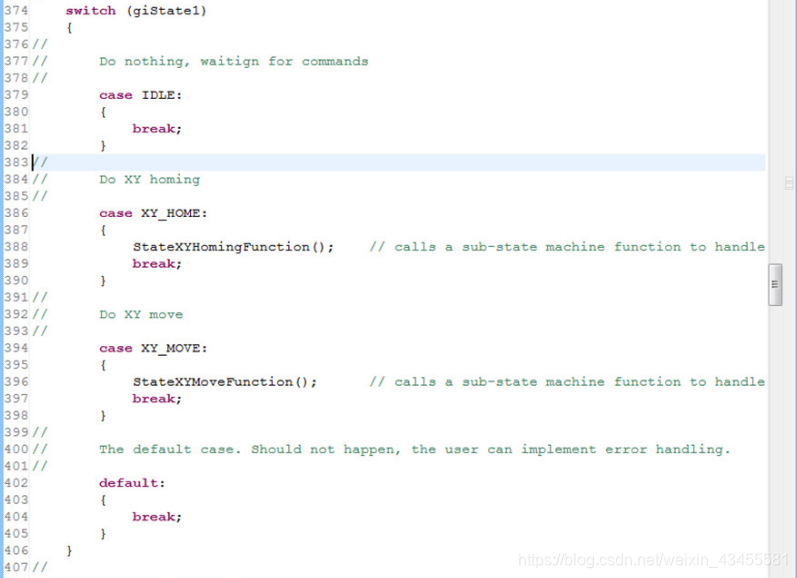
注意,函数ReadAllInputData()必须由用户修改,以实际访问所有所需输入数据的源,并创建其值的副本(镜像)。这将在状态机代码中使用,确保在执行状态机代码的给定循环时没有变量发生更改。
StateXYHomingFunction()是子状态机代码的一个很好的例子。当机器处于XY_HOME状态(主状态机的值是XY_HOME)时,这个函数将运行每个计时器事件,并处理它的子状态机来管理XY_HOME进程。
当然,示例项目中描述的示例是一个非常简单的寻的过程。它只演示了编程概念,而没有显示如何编写完整的寻的过程。但是,这将尽可能保持样例应用程序的整洁和简单。
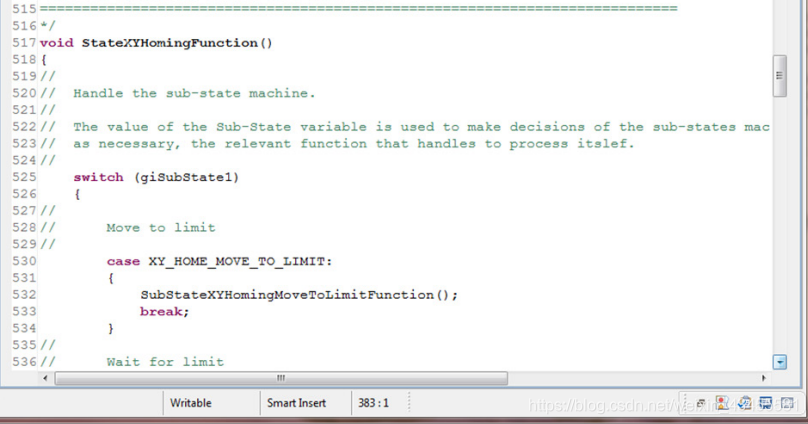
下一个阶段是……

最后,到达创建运动、等待运动结束等低层函数时,我们找到了函数(例如):SubStateXYHomingMoveToLimitFunction()。
请注意这个函数是如何创建动作的(而不是等待动作结束或其他动作),并立即更改子状态,以便在下一个循环中检测到XY_HOME_WAIT_TO_LIMIT状态,并到达SubStateXYHomingWaitLimitFunction()。
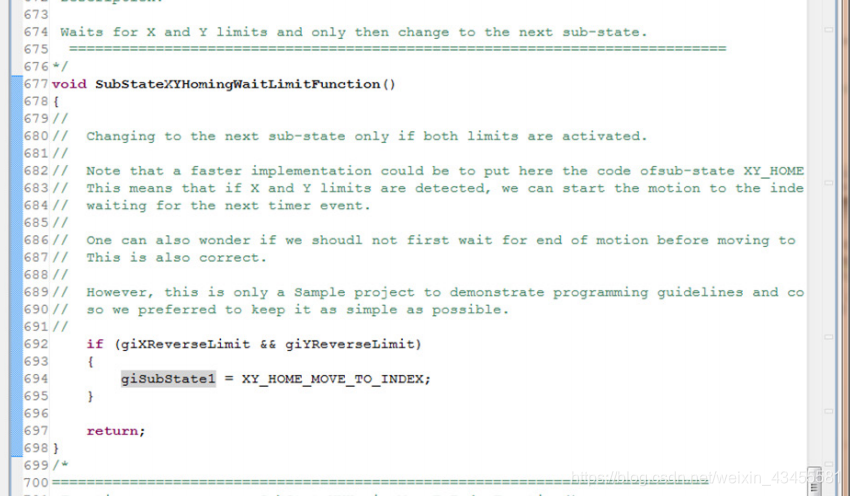
在SubStateXYHomingWaitLimitFunction()中,您可以看到如何检查限制状态(假设读取了限制状态,并且在计时器周期开始时在ReadAllInputData()中相应地设置/清除了giXReverseLimit和giYReverseLimit变量)。
如果没有达到限制,则不会更改子状态,函数结束(没有“延迟”,没有“等待”)。它将在下一个计时器周期(本例中为20ms)再次调用,以此类推。一旦设置了这两个限制,子状态就被修改为下一个状态,函数就结束了。这将迫使子状态机在下一个计时器周期中执行下一个子状态(MOVE_TO_INDEX)。
所有函数都尽可能短。等待事件不是函数的一部分,而是作为状态实现的(例如WAIT_TO_LIMIT)。根据状态机代码的结构,这是每一个定时器周期调用一次,以检查是否满足等待条件。一旦状态为,状态值将更改为下一个状态。
这实际上结束了Sample.c代码。它包含了更多的状态函数,但是它们都是根据上面的指导原则编写的。
下面的两个图显示了Sample.h。注意函数原型(一般函数和状态函数,以及常量的定义)和使用的格式,如:替换代码中的每个数字。
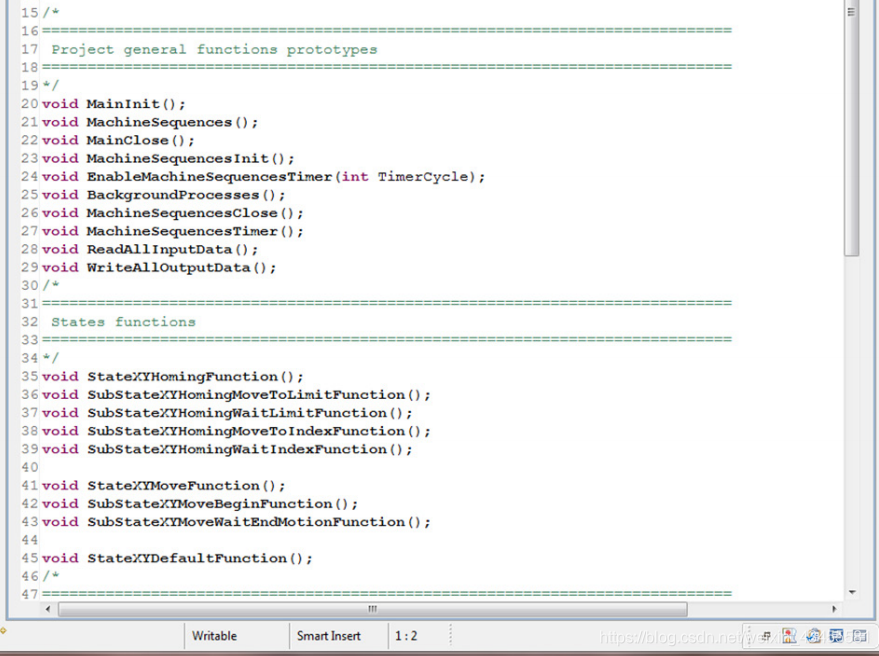
连同下一个图表…
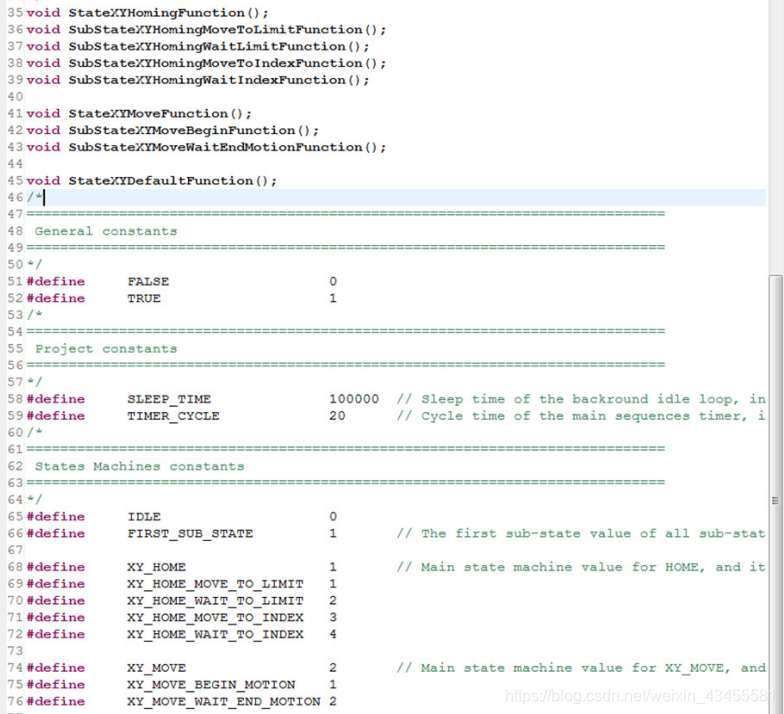
这实际上完成了对示例项目代码的检查。samplewrap.c和samplewrap.h文件是框架文件,几乎是空文件,用于填充实际应用程序可能需要的函数和定义(稍后您将在本手册中找到一个)。














 2744
2744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









