






一、分布式参数理解
所有gpu数 = world_size
一台机器的gpu数 = device_count 通常<=8
rank是指 当前的进程数是变化的,range从[0, world_size-1]
node表示机器数,通常world_size = node*device_count(=8)
local_rank = rank%device_count [0-7]
二、模型分组切分
模型并行MP:是指将模型的不同层放在不同的gpu(横切)
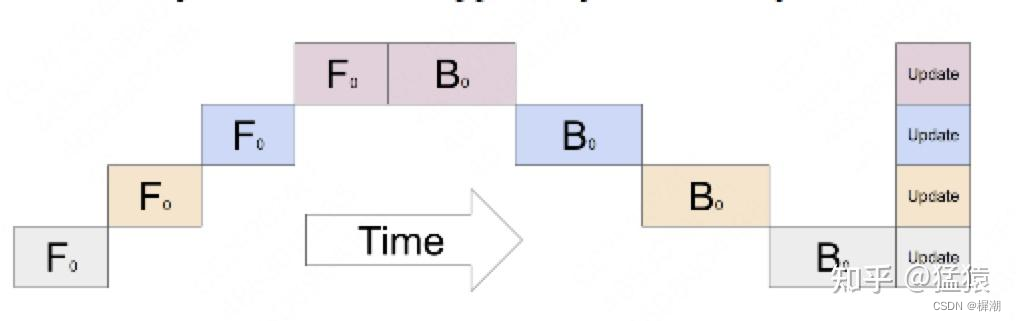
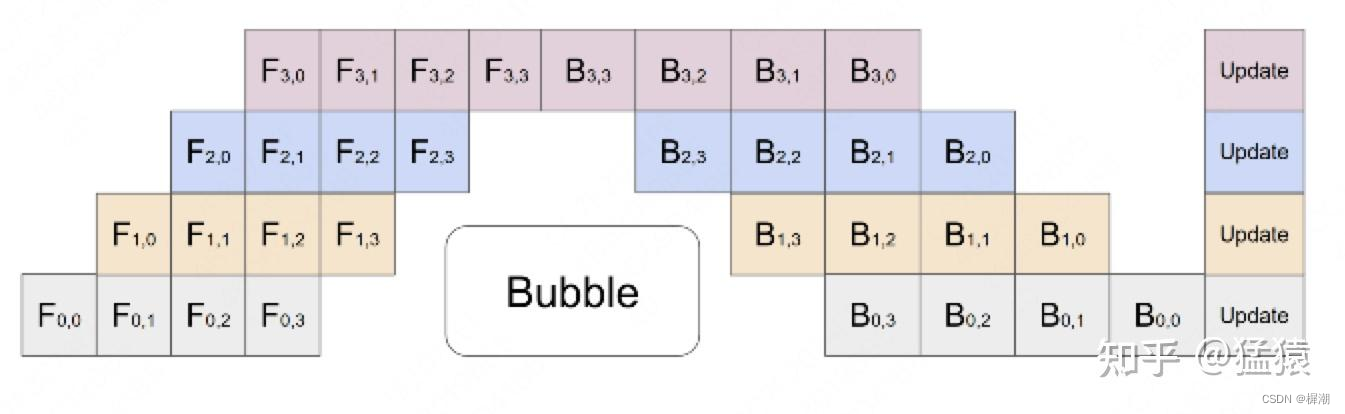
流水线并行PP:是为了解决MP的空转等GPU利用率不同,将mini_batch切分为M个micro_batch
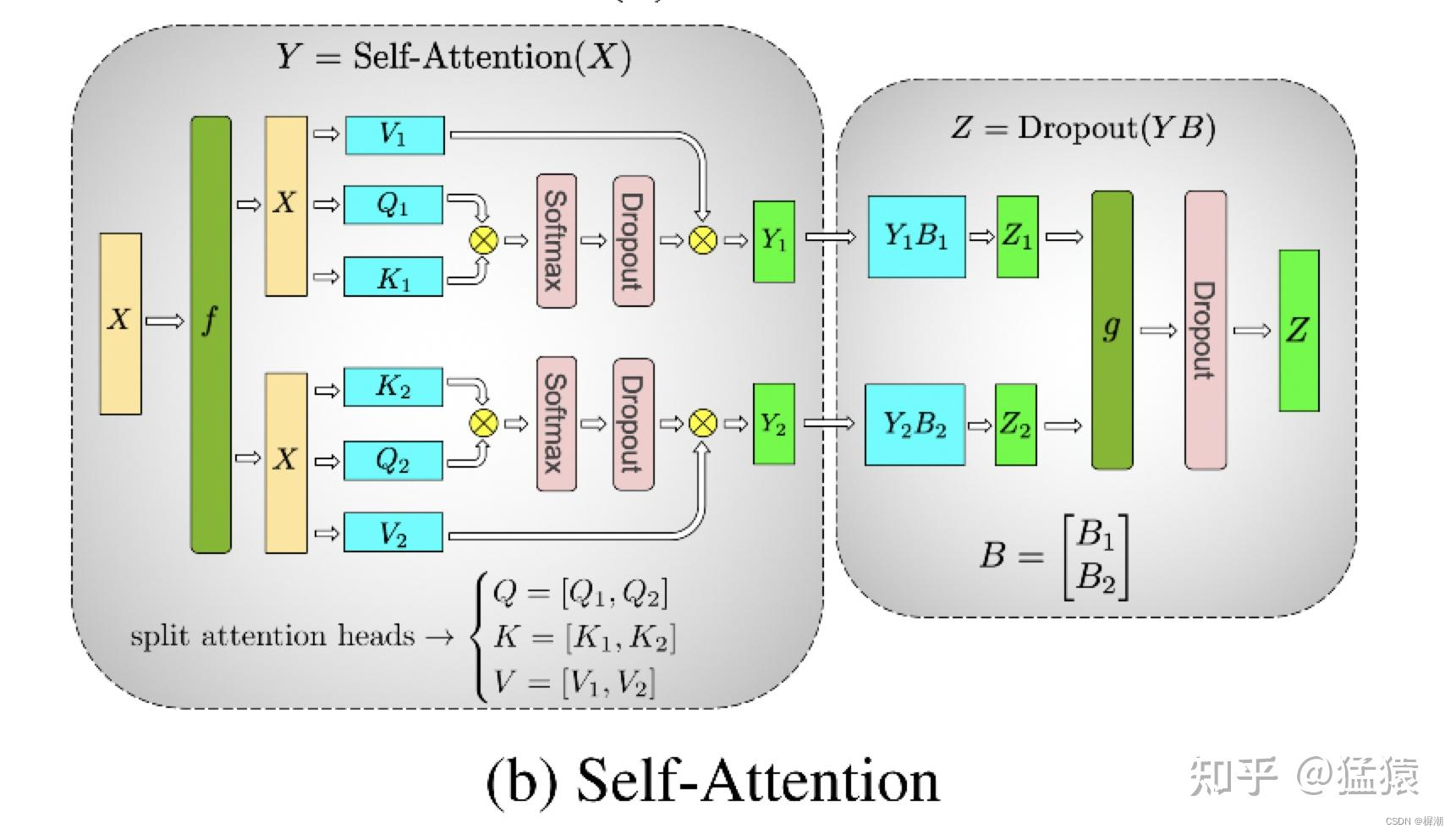
张量并行:将tensor切开放在不同的gpu(竖切),作用颗粒度是矩阵。通常是权重。比如attention的多头注意力,将多头切分成多个小头
数据并行:
1)DP(单机多卡),
2)DDP(多机多卡):Ring-All-Reduce
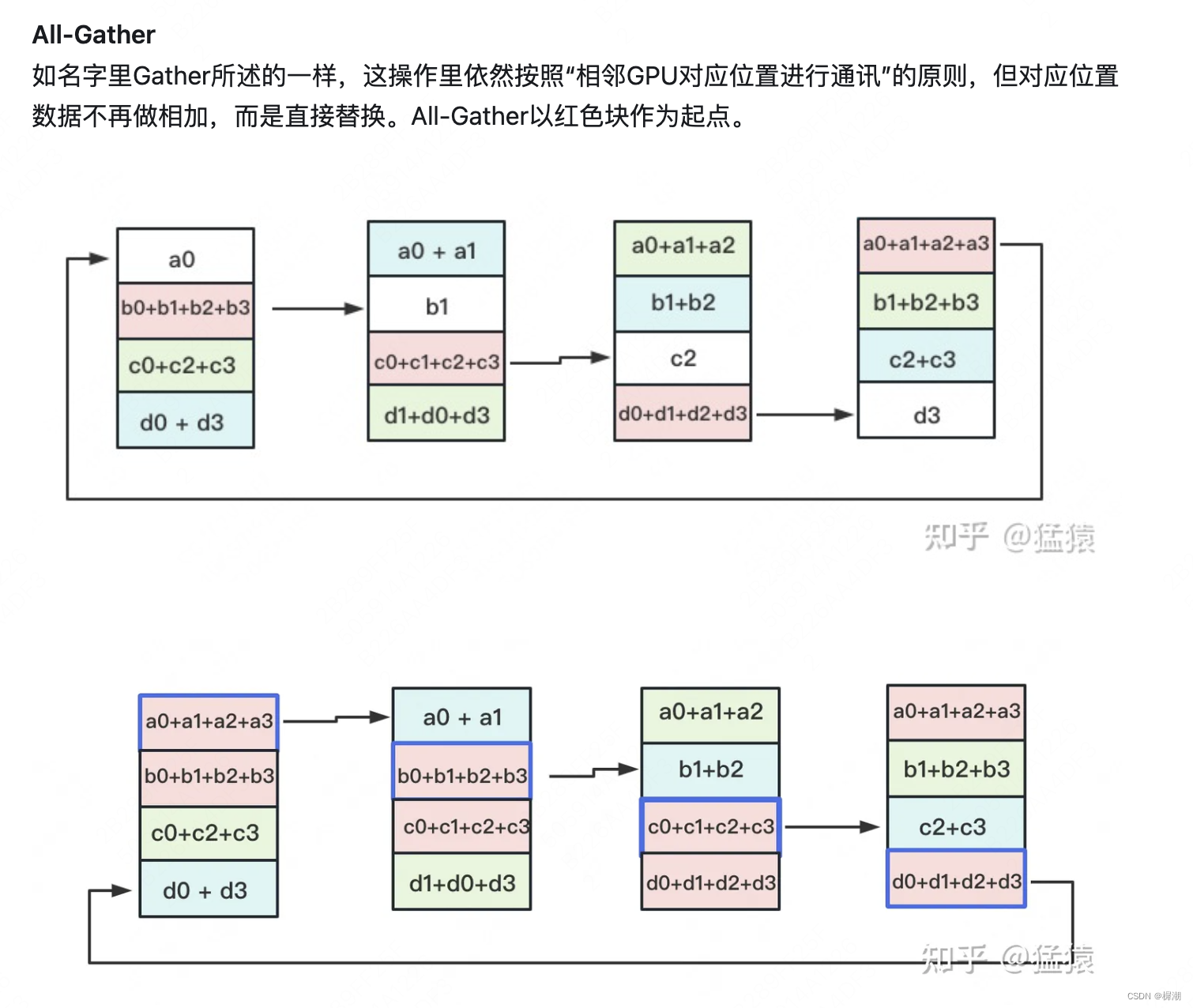
3)zero。















 445
445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









