








文章目录
前言
本篇是基于B站UP主霹雳吧啦Wz的视频讲解以及其提供的Faster RCNN代码针对Faster RCNN代码流程做的笔记。
如果对RCNN、Fast RCNN、Faster RCNN不了解的话,建议观看霹雳吧啦Wz的Faster RCNN的理论合集。
一、Faster RCNN整体流程
Faster RCNN整体流程如下图所示(图片来源)

流程:
- 加载数据集
- 数据预处理
- 传入特征提取网络(backbone),得到特征图
- 特征图传入PRN网络
- 特征图信息以及RPN输出传入roi_heads(roi_heads:ROIpooling + Two MLPHead + FastRCNNPredictor + Postprocess Detections)
- 将bbox信息映射回原图
二、PASCAL VOC2012数据集
1.简介
PASCAL VOC挑战赛( The PASCAL Visual Object Classes)是一个世界级的计算机视觉挑战赛,PASCAL全称:Pattern Analysis, Statical Modeling and Computational Learning,是一个由欧盟资助的网络组织。
PASCAL VOC挑战赛主要包括以下几类:图像分类(Object Classification),目标检测(Object Detection),目标分割(Object Segmentation),动作识别(Action Classification)等。
VOC的类别主要有20个检测类别,如下图所示(图片来源):

2.下载方式
- 网页下载或者迅雷下载
- 我的百度网盘,提取码:lhb5
3.文件结构及含义
文件结构如下图所示(图片来源):

对于目标检测使用VOC2012的情况,我们主要关注Annotations、ImageSets/Main、JPEGImages 三个文件夹,注意:
Annotations下的xml文件信息每行含义如下图所示(以2007_000123.xml为例):

ImageSets/Main文件夹下有很多txt文件:train.txt、val.txt和trainval.txt,以及各分类的train.txt和val.txt。

其中train.txt中记录了属于训练集的图片名称

这里的2008_000008就对应着JPEGImages目录下名称叫2008_000008.jpg是属于训练集的。而在train前面加上分类名称的,比如boat_train.txt,其具体内容如下图所示:

如上图所示boat_train.txt共有左右两列内容,左侧是属于训练集的图片名称(与train.txt的内容相同),右侧是-1、1或者0。
-1表示代表boat不在这张图片中;0表示检测boat是否在该图片中是有难度的,1表示boat在该图片中。
以2008_007156.jpg、2008_007169.jpg以及2008_007179.jpg三张图片为例,它们分别属于1,-1,0:
| 1(boat在) | -1(boat不在) | 0(boat不太容易确定) |
|---|---|---|
 |  |  |
总结:JPEGImages存放着图片,而txt文件的内容是某个集合中包含的图片名称,xml文件记录着对应图片的相关信息:来源、bbox的位置以及分类。
三、加载数据集
加载数据集的代码在Faster RCNN代码中的my_dataset.py文件中:
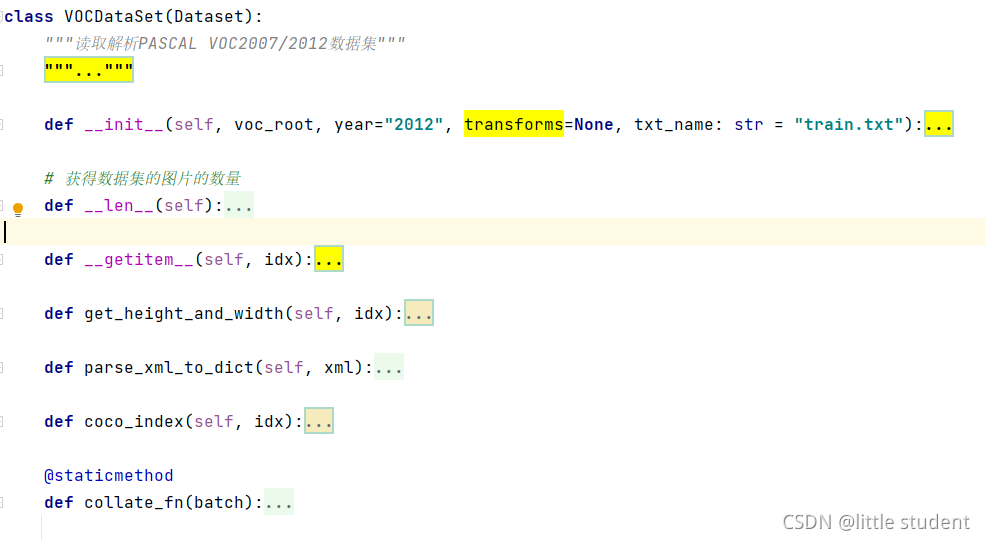
VOCDataset类继承torch.utils.data.Dataset类,需要实现__len__()函数以及__getitem()函数;
- 前者的作用是获取指定的数据集(默认加载的是训练集)的图片的总数量;
- 后者的作用是获得指定索引(idx)的图片的tensor数据、以及目标信息;
__len__函数的实现很简单不做介绍,重点看下__getitem__函数,其有一个参数idx,为图片的索引。
具体实现如下:
def __getitem__(self, idx):
image = Image.open(根据idx获得指定图片路径)
for obj in xml文件中的object:
每个框(obj)的左上角坐标和右下角坐标[xmin, ymin, xmax, ymax]
boxes.append([xmin, ymin, xmax, ymax])
labels.append(每个框对应的分类)
iscrowd.append(检测难度)
将上述变量转换为tensor
计算每个检测框的面积area
target{"boxes":boxes,"labels":labels, \
"image_id":torch.tensor([idx]),"area":area,"iscrowd":iscrowd}
对image,target使用GeneralizedRCNNTransform类进行预处理
return image,target
其中的GeneralizedRCNNTransform类将在下一章介绍。
四、数据预处理
1.流程
数据预处理部分的代码在Faster RCNN代码中的network_files/transform.py文件中:

由上图可知,其初始化有四个参数:
- min_size: 指定图像的最小边长范围
- max_size: 指定图像的最大边长范围
- image_mean: 指定图像在标准化处理中使用的均值
- image_std: 指定图像在标准化处理中使用的方差
对于Faster RCNN代码中image_mean 和 image_std 则是使用了imageNet的均值和方差:
- image_mean = [0.485, 0.456, 0.406]
- image_std = [0.229, 0.224, 0.225]
GeneralizedRCNNTransform的forward主要流程有:
- 标准化image数据
- 缩放image和target
- 将image处理为同一尺寸
代码流程如下:
def forward(self, iamges, targets):
images = 列表化一个batch中的iamge
for i in range(len(images)):
image = images[i]
target_index = targets[i]
image = self.normalize(image) # 对图像进行标准化处理
# 将图像和对应的bboxes缩放到指定范围
image, target_index = self.resize(image, target_index)
images[i] = image
targets[i] = target_index
image_sizes_list.append(batch中每一张图像resize后的尺寸)
images = self.batch_images(iamges) # 将图片处理为统一尺寸
image_list = ImageList(images, image_sizes_list) # 转换为ImageList对象
2.标准化数据
标准化后的图像 = (原图像数据-均值)/方差
def normalize(self, image):
"""标准化处理"""
mean = tensor化image_mean
std = tensor化image_std
return (image - mean[:, None, None]) / std[:, None, None]
3.缩放
# 该函数是针对单个图像以及其对应的boxes缩放
def resize(self, image, target):
# ------缩放image----------
self_min_size:指定的最小边长
self_max_size:指定的最大边长
min_size,max_size = 排序(image宽度、image高度) # 从小到大
scale_factor = self_min_size / min_size
# 如果使用该缩放比例计算的图片最大边长大于指定的最大边长
if max_size * scale_factor > self_max_size:
scale_factor = self_max_size / max_size
# torch.nn.functional.interpolate 为双线性插值函数
image = 以缩放因子为scale_factor使用torch.nn.functional.interpolate函数缩放图片
# ------缩放boxes----------
bbox = target["boxes"]
根据image缩放前后的宽度和高度,确定宽度和高度的缩放比ratios_width,ratios_height
x_min,x_max = ratios_width* (x_min,x_max)
y_min,y_max = ratios_height * (y_min,y_max)
bbox = 缩放后的bbox
4.将图片处理为统一尺寸
经过resize后的图像只是缩放到了规定的尺寸范围(min_size,max_size)之间,然而图像尺寸仍然是不统一的,这就导致无法直接应用于backbone中。
而batch_images函数则实现了如下效果:

如上图所示,假设有四张不同尺寸的图片(用四种不同的带颜色的矩阵表示),求得四张图片中的最大宽度,最大高度,这就是外边的大的白色矩形的尺寸,让每张图片与白色矩形的左上角对齐,然后依次使用图片中的数据填充白色矩阵,其余位置则用0填充。这样四张图片就被统一成了同一尺寸。
def batch_images(self, images, size_divisible=32):
'''
Args:
images: 输入的一批图片
size_divisible: 将图像高和宽调整到该数的整数倍
'''
max_size = [这一批图片的最大channel,这一批图片的最大宽度,这一批图片的最大高度]
# 将height向上调整到stride的整数倍
max_size[1] = int(math.ceil(float(max_size[1]) / stride) * stride)
# 将width向上调整到stride的整数倍
max_size[2] = int(math.ceil(float(max_size[2]) / stride) * stride)
batched_imgs = 全为0的tensor矩阵,shape为(bathc_size,max_size[0],max_size[1],max_size[2])
for img, pad_img in zip(images, batched_imgs):
依次填充图像
return batched_imgs
5.数据预处理的输入输出
数据预处理的输入:
-
images:一个共有batch_size个元素的list,每个元素的shape是读取的图片的shape(通道数,高度,宽度)
-
targets: 一个共有batch_size个元素的list,每个元素都是存储目标检测相关信息的有序字典,key与value对应值如下:
{'boxes':tensor[xmin,ymin,xmax,ymax],'lables':tensor[分类索引], \ 'image_id':tensor[图片索引],'area':tensor[图像面积],'iscorwd':tensor[检测难度对应数值]}
数据预处理的输出:
- images:经过GeneralizedRCNNTransform处理(标准化、缩放、统一尺寸)后的带有图像数据的ImageList对象
images: 属性image_sizes = [batch_size个图像尺寸] ,每个图像尺寸都是resize之后但是没有进行统一尺寸操作的尺寸。 属性tensors的shape:(batch_size,图像的channles,统一尺寸的高度、统一尺寸的宽度) - targets:经过第四章GeneralizedRCNNTransform处理(缩放)后的带有gt boxes信息的字典
五、Backbone
Faster RCNN Backbone 用于提取图片的特征信息,并将得到的特征图传入RPN网络和roi_heads部分。在Faster RCNN代码中Backbone采用mobilenet v2的特征提取层或者ResNet50+FPN。
对于上述内容参考以下链接(因为我也没看…,看完再更新):
由第四章可知,GeneralizedRCNNTransform输出两个变量:images, targets。
- images是ImageList类的变量,其中包含两个类属性,tensors用于存储图像的数据,image_sizes用于存储经过batch_images之前resize之后的图像尺寸。
- targets是一个字典类型,存放着boxes以及labels等信息。
将images中的图像数据传入Backbone后,得到features
# 对于mobilenet v2,其经过backbone只得到一层features,其features 是一个tensor类型的
# 将其存入有序字典并编号为‘0’
# 对于resnet50 + fpn,经过backbone输出的features本身就是一个OrderDict类型的,
# 共有‘0','1','2','3','pool'五层特征层。
features = self.backbone(images.tensors)
if isinstance(features, torch.Tensor):
features = OrderedDict([('0', features)])
六、RPN网络
1.参数
RPN网络部分在Faster RCNN代码中的rpn_function.py文件中:

RegionProposalNetwork类的初始化参数如下:
# fg_iou_thresh,bg_iou_thresh: rpn计算损失时,采集正负样本设置的阈值
# batch_size_per_image: rpn在计算损失时采用正负样本的总个数
# postive_fraction: 正样本个数在batch_size_per_image中占的比例
# pre_nms_top_n:在进入nms前的候选框保留个数
# post_nms_top_n: 使用nms后的候选框保留个数
# nms_thresh: 在nms处理过程中使用的阈值
2. IoU
IoU是交并比的意思,如下图所示:

两个anchors的交并比是用这两个anchors的交集面积/这两个anchors的并集面积。
一种常用的计算IoU的方法入下图所示(图片来源):

流程如下:
- 得到蓝色框的左上角坐标(cx1,cy1),右下角坐标(cx2,cy2);黄色框的左上角坐标(gx1,gy1),右下角坐标(gx2,gy2)
- 计算蓝色框的面积carea,黄色框的面积garea
- 获得两个框的左上角坐标最大的,记为(x1,y1);获得两个框的右下角坐标最小的,记为(x2,y2)
- 判断两个框是否真的相交,就比较右下角坐标(x2,y2)是不是真的在(x1,y1)的右下方,这可以通过如图所示的两个max比较。
3.正负样本
对于正负样本的定义如下:
- 与某个ground-truth box IoU值超过0.7
- 与ground-truth box IoU值最大的那一个或者几个作为正样本
负样本:与所有ground-truth box IoU值小于0.3
以上的正负样本都是针对图片中生成的anchors的,不是分出来图像的正负样本,而是对图像中的anchors分出正负样本。
为什么需要正负样本的采样操作?因为事实上一张图上的初始生成的anchors属于负样本(背景)的肯定是居多的,假设一个极端的比例,属于背景的有99个,属于前景的有1个,那么对于区分前景与背景的分类器来说,即使把所有的anchors都分类为背景,其仍有一个极高的准确率(99%),但是这显然是不合理的。因为对于我们来说,我们是希望这个分类器能够准确分类属于前景的anchors,所以我们需要一个合适的正负样本比例来训练这个分类器。
4.RPN网络流程
1. RPN(RegionProposalNetwork)forward过程
为了不产生一层层的套娃的难受感,在此部分尽量抛弃各种函数的声明,将其流程直接融入到RPN网络的forward函数中(所以会有如下超长的forward代码流程)。
RPN网络的流程在其中的forward函数中:
def forward(self,
images, # type: ImageList
features, # type: Dict[str, Tensor]
targets=None # type: Optional[List[Dict[str, Tensor]]]
):
features = 将第五章得到的features.values列表化
# 计算每个预测特征层上的预测目标概率和bboxes regression参数
# RPNHead:3×3卷积 + 两个并联的1×1卷积
# objectness 的size为[(batch_size,每个点生成的anchos数目,高度,宽度) 重复 预测特征层层数次]
# pred_bbox_deltas 的size为[(batch_size,每个点生成的anchos数目 * 4,高度,宽度)重复 预测特征层层数次]
objectness, pred_bbox_deltas = features传入RPNHead
# --------------------获得anchors开始-------------
# 得到的是一个list列表,对应每张预测特征图映射回backbone输入的anchors坐标信息
# 对于mobilenet v2而言:
# anchors_over_all_feature_maps :[(输出特征图点的个数*根据参数设定的每个点生成的anchors个数,4)]
# 对于resnet50+fpn而言:
# anchors_over_all_feature_maps的列表长度为5,
# 每个元素的shape都是(该层输出特征图点的个数*根据参数设定的每个点生成的anchors个数,4)
anchors_over_all_feature_maps = 使用cached_grid_anchors函数 \
生成在backbone输入图像上的anchors
# 上一步其实是获得了一张backbone输入图像的所有anchors
# 上述操作也可以理解backbone anchors的初始化模板
# 对一个batch中的图片都使用上述得到的初始化模板
anchors = []
将anchors_over_all_feature_maps处理为shape为(所有预测特征层的anchors数, 4)
for i in range(batch_size的大小):
anchors.append(处理后的anchors_over_all_feature_maps)e
# --------------------获得anchors结束-------------
# anchors的size[(预测特征层层数 * 输出特征图的点数 * 每点生成的anchors数, 4) 重复 batch_size次]
# 将objectness全部展开,1是因为RPN分类主要是区分前景与背景,所有只需一个数(0-1)就可以表示这两个情况。
# 4指的bbox偏移参数
# 一个batch中的anchors数目 = 一张图所有预测特征层的anchors数目 * batch_siz
调整objectness的shape为(batch总anchors数目 ,1)
调整pred_bbox_deltas的shape为(batch总anchors数目, 4)
# --------------------修正anchors开始-------------
concat_boxes = 将一个batch中所有的anchors拼接在一起 # shape(batch总anchors数目,4)
根据concat_boxes获得每个anchors的宽度、高度、中心点坐标
# pred_bbox_deltas中的四个数分别是中心点x、y的偏移系数,宽度、高度的偏移系数
# 除此之外,还为这四个系数分配了四个不同的权重,猜测与权重的学习率的作用是一样的
tx,ty,tw,th = pred_bbox_deltas /self.weight
根据tx,ty,tw,th以及下面图中的公式得到经过修正的anchors中心横坐标,宽度、高度
proposals = 再根据上一步的结果调整为左上角坐标,右下角坐标的格式
# --------------------修正anchors结束-------------
# --------------------过滤proposals开始----------
将proposals reshape为(batch_size, -1, 4)
将objectness reshape为(batch_size, -1)
levels = tensor(第 i 层预测特征层的anchors数目 * i)
levels = levels.reshape(1, -1).expand_as(objectness)
# self.pre_nms_top_n是设定的参数
# top_n_idx shape()
top_n_idx = 获得预测概率排前pre_nms_top_n的anchors索引值
根据top_n_idx过滤objectness,proposals,levels
objectness = torch.sigmoid(objectness)
调整proposals信息,将越界的坐标调整到图片边界上
去掉宽度高度不满足min_size限制的proposals和objectness
移除预测概率小于self.score_thresh的proposals和objectness
经过nms进一步过滤proposals和objectness
boxes,scores = 以列表形式存储剩下的proposals,objectness
# --------------------过滤proposals结束----------
# --------------------获得正负样本开始----------
labels = []
matched_gt_boxes = []
# 注意这里的targets中的gt boxes信息并不是xml文件中的原始数据,而是经过第四章第3节缩放过后的boxes信息
# 而anchors也是根据缩放过后的images信息得到的
for anchors_per_image, targets_per_image in zip(anchors, targets):
gt_boxes = targets_per_image["boxes"] # ground_truth boxes
# match_quality_matrix shape:(gt_boxes数量,anchors数量)
match_quality_matrix = 计算anchors_per_image与gt_boxes的IoU值
# matched_idxs 其中元素为-1的是负样本,元素为-2的为需要丢弃的样本,元素属于[0,gt boxes的数量)的是正样本
matched_idxs = 通过match_quality_matrix的数值区分正负样本以及被舍弃的样本
# 获得正样本所对应的gt_boxes,而负样本与需舍弃样本的值在计算loss中没有作用,所以都被统一指定为第0个gt_boxes值
matched_gt_boxes_per_image = gt_boxes[matched_idxs.clamp(min=0)]
labels_per_image = 通过matched_idx正样本处标记为1,负样本处标记为0,丢弃样本处标记为-2
labels.append(labels_per_image)
matched_gt_boxes.append(matched_gt_boxes_per_image)
# --------------------获得正负样本结束----------
# RPN损失的主要来源于RPNHead的参数,一个是分类的损失,一个是anchors回归带来的损失
# --------------------计算真实的偏移参数开始----------
reference_boxes,anchors_rs = 将matched_gt_boxes 和 anchors \
转换为shape为(一个bacth所有anchors数,4)的tensor
利用reference_boxes得到其中每个gt_boxes的宽度gt_widths、高度gt_heights、 \
中心x坐标gt_ctr_x,中心y坐标gt_ctr_y
利用anchors_rs 得到其中每个anchor的宽度ex_widths、高度ex_heights、 \
中心x坐标ex_ctr_x,中心y坐标ex_ctr_y
利用下图的公式,计算出真实偏移参数targets_dx、targets_dy、targets_dw、targets_dh
regression_targets = torch.cat((targets_dx, targets_dy, \
targets_dw, targets_dh), dim=1).split(boxes_per_image, 0)
# --------------------计算真实的偏移参数结束----------
# --------------------计算PRN损失开始----------
# sampled_pos_inds, sampled_neg_inds是列表,共batch_size的长度,每个列表中是个shape为(图片总anchors数,)的tensor
# sampled_pos_inds中的一个元素的可能结果是tensor([0,1,1,0,0,.....]) # 1代表作为选中的正样本,0代表没选中或者不是正样本
# sampled_neg_inds中的一个元素的可能结果是tensor([1,0,0,0,1,.....]) # 1代表作为选中的负样本,0代表没选中或者不是负样本
依据labels随机取样指定比例的正样本与负样本,索引记为sampled_pos_inds, sampled_neg_inds
sampled_pos_inds,sampled_neg_inds = 一个batch中sampled_pos_inds,sampled_neg_inds不为0的元素索引
sampled_inds = 将sampled_pos_inds,sampled_neg_inds中的元素放在一起
box_loss = 使用smooth_l1_loss计算边界框回归损失/(sampled_inds.numel())
objectness_loss = 使用二值交叉熵损失函数binary_cross_entropy_with_logits计算objectness[sampled_inds], labels[sampled_inds]的损失
losses = {
"loss_objectness": loss_objectness,
"loss_rpn_box_reg": loss_rpn_box_reg
}
return boxes, losses
# --------------------计算PRN损失结束----------
对于bbox的修正公式如下图所示(图片来源),tx = (x - xa)/wa tx表示偏移参数,wa表示anchor的宽度,xa表示anchor的中心横坐标,x表示经过修正的anchor中心横坐标.

def cached_grid_anchors(self, grid_sizes, strides):
# type: (List[List[int]], List[List[Tensor]]) -> List[Tensor]
# grid_sizes:backbone输出特征图的尺寸
# strides:backbone 输出特征图的尺寸/backbone输入的尺寸
key = str(grid_sizes) + str(strides)
if key in self._cache:
return self._cache[key]
使用generate_anchors生成以(0,0)为中心若干个不同尺寸不同宽高比(根据参数规定的)的base_anchors
根据strides以及grid_sizes尺寸得到grid_sizes上每一个点对应的backbone输入图像上的点,记为shifts
anchors = shifts + base_anchors 就生成以这些点为中心若干个不同尺寸不同宽高比的anchors
# 这里的anchors尺寸是(输出特征图共有多少个点,根据参数设定的每个点生成的anchors个数,4)
self._cache[key] = anchors
return anchors
为了更加形象地理解cached_grid_anchors到底做了哪些工作,使用以下四张图进行解释(图片来源):
- 第 1 张图:将特征图上的点映射回backbone的输入图中
- 第 2-4 张图:以每个点为中心,生成若干个不同尺寸不同宽高比的anchors

2. RPNHead
RPNHead的结构如下图所示,其中包括了一个3×3卷积以及两个1×1卷积并联(图片来源)。

而RPNHead的代码如下所示:
class RPNHead(nn.Module):
"""
add a RPN head with classification and regression
通过卷积计算预测目标概率与bbox regression参数
Arguments:
in_channels: 经过backbone得到的features的输出通道数
num_anchors: 需要预测的anchors数目
"""
def __init__(self, in_channels, num_anchors):
super(RPNHead, self).__init__()
# 3x3 滑动窗口
self.conv = nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1)
# 计算预测的目标分数(这里的目标只是指前景或者背景)
# 这里的1×1卷积,输出通道数为num_anchors,而不是2×num_anchors,是因为最后使用的是二值交叉熵损失,而不是one-hot分布的交叉熵损失
# 即只使用一个参数表示每一个anchor属于前景的概率,共num_anchors,即输出通道数为num_anchors
self.cls_logits = nn.Conv2d(in_channels, num_anchors, kernel_size=1, stride=1)
# 计算预测的目标bbox regression参数
self.bbox_pred = nn.Conv2d(in_channels, num_anchors * 4, kernel_size=1, stride=1)
初始化卷积的权重和偏置
def forward(self, x):
# type: (List[Tensor]) -> Tuple[List[Tensor], List[Tensor]]
logits = []
bbox_reg = []
for i, feature in enumerate(x):
t = F.relu(self.conv(feature))
logits.append(self.cls_logits(t))
bbox_reg.append(self.bbox_pred(t))
return logits, bbox_reg
5.NMS
非极大值抑制(Non-Maximum Suppression,NMS)的流程是:
- 寻找得分最高的目标
- 计算其他目标与该目标的IoU值
- 删除所有IoU值大于给定阈值的目标,因为与得分最高的目标IoU值越高,说明重复的越多,就没有必要保留下来。
- 在未处理的目标中继续重复1、2、3步直到所有目标都被遍历
如图所示(图片来源):

6.RPN网络的输入与输出
RPN网络的输入:
-
images:经过第四章GeneralizedRCNNTransform处理(标准化、缩放、统一尺寸)后的带有图像数据的ImageList对象
images: 属性image_sizes = [batch_size个图像尺寸] ,每个图像尺寸都是图像标准化并resize之后但是没有进行统一尺寸操作的尺寸。 属性tensors的shape:(batch_size,图像的channles,统一尺寸的高度、统一尺寸的宽度) -
features:经过backbone后得到的一个有序字典
features:{ key:'0' value:backbone得到的第0层特征层 ......} -
targets:经过第四章GeneralizedRCNNTransform处理(缩放)后的带有gt boxes信息的字典
targets:[ {'boxes':tensor[xmin,ymin,xmax,ymax],'lables':tensor[分类索引],'image_id':tensor[图片索引],'area':tensor[图像面积],'iscorwd':tensor[检测难度对应数值]}, ... ... 共batch_size个有序字典 ]
RPN网络的输出:
-
proposals:经过生成anchors、修正anchors、依据分类概率删选一定数量、调整过界anchors、滤除小概率、经过nms操作后得到的anchors
proposals 列表形式,共batch_size个元素,每个元素shape:(self.post_nms_top,4) -
proposal_losses:存储获得的RPN产生的分类损失以及边界框回归损失的有序字典
proposal_losses:{ 'loss_objectness':tensor[分类损失值] 'loss_rpn_box_reg':tensor[边界框回归损失值] }
七、Roi_heads 部分
1.组成元素及初始化

(图片来源)
由上图可知,roi_heads = RoIpooling + Two MLPHead + FastRCNNPredictor + PostProcess Detections
初始化函数如下所示:
class RoIHeads(torch.nn.Module):
__annotations__ = {
'box_coder': det_utils.BoxCoder,
'proposal_matcher': det_utils.Matcher,
'fg_bg_sampler': det_utils.BalancedPositiveNegativeSampler,
}
def __init__(self,
box_roi_pool, # Multi-scale RoIAlign pooling
box_head, # TwoMLPHead
box_predictor, # FastRCNNPredictor
# Faster R-CNN training
fg_iou_thresh, bg_iou_thresh, # default: 0.5, 0.5
batch_size_per_image, positive_fraction, # default: 512, 0.25
bbox_reg_weights, # None
# Faster R-CNN inference
score_thresh, # default: 0.05
nms_thresh, # default: 0.5
detection_per_img): # default: 100
super(RoIHeads, self).__init__()
2.流程
def forward(self,
features, # type: Dict[str, Tensor]
proposals, # type: List[Tensor]
image_shapes, # type: List[Tuple[int, int]]
targets=None # type: Optional[List[Dict[str, Tensor]]]
):
"""
Arguments:
features : 多层特征层
proposals :经过RPN的anchors
image_shapes :images经过resize但是未统一尺寸的图片大小
targets:经过transform操作的targets
"""
# --------------------获得proposals对应信息开始----------
matched_idxs = []
labels = []
gt_boxes,gt_labels(列表形式) = 获取targets中‘boxes’信息,‘labels’信息
proposals = 将gt_boxes拼接到proposal后面
# 假设proposals是size[8*(2000,4)] gt_boxes:[8*(2,4)],拼接后是[8*(2002,4)]
# 至于为什么要拼接,霹雳吧啦Wz认为是在训练过程中正样本过少,添加gt_boxes信息以尽量使得正样本多一些
for proposals_in_image, gt_boxes_in_image, gt_labels_in_image in zip(proposals, gt_boxes, gt_labels):
match_quality_matrix = 计算proposals_in_image与每一个gt_boxes的IoU值
# matched_idxs_in_image 是一个tensor,其中的-1代表该proposals是负样本,-2是需要舍弃的样本,>0的数字代表该proposal与哪一个gt_boxes对应
matched_idxs_in_image = 根据match_quality_matrix以及设置的正负样本的阈值获得proposals_in_image与哪一个gt_boxes_in_imageIoU值最大
# 这两步是为了获得正样本的对应的gt_boxes标签
clamped_matched_idxs_in_image = matched_idxs_in_image.clamp(min=0)
labels_in_image = gt_labels_in_image[clamped_matched_idxs_in_image].tensor化()
labels_in_image = 再修改负样本对应的gt_boxes标签为0(背景),废弃样本的对应的gt_boxes标签为-1
matched_idxs.append(clamped_matched_idxs_in_image)
labels.append(labels_in_image)
# --------------------获得proposals对应信息结束----------
# --------------------获得正负样本开始----------
# sampled_inds是一个batch_size长度的列表,
# 每个元素是存储着proposals正负样本对应索引的tensor,eg.[2,5,7,10,.....]
sampled_inds = 根据lables以及设定的batch_size_per_image, positive_fraction参数,随机采样正样本负样本
for img_id in range(num_images):
# 获取每张图像的正负样本索引
img_sampled_inds = sampled_inds[img_id]
# 获取正负样本的proposal、真实类别、gt索引信息
proposals[img_id], labels[img_id], matched_idxs[img_id] = proposals[img_id][img_sampled_inds], \
labels[img_id][img_sampled_inds],matched_idxs[img_id][img_sampled_inds]
gt_boxes_in_image = gt_boxes[img_id]
# 获取对应正负样本的gt box信息
matched_gt_boxes.append(gt_boxes_in_image[matched_idxs[img_id]])
regression_targets = 根据matched_gt_boxes以及proposals计算真实的回归参数
# --------------------获得正负样本结束----------
# --------------------proposals统一尺寸开始--------
# 统一proposals的尺寸为7×7
# 注意:proposals在未统一尺寸前的尺寸是针对resize后的原图来说的
# 这一步操作也是将resize后的原图上的proposals映射到特征图上再统一尺寸
box_features = 使用RoIpooling,输入(features, proposals, image_shapes)
# --------------------proposals统一尺寸结束--------
# --------------------box_head开始--------
# box_features的shape为(batch_size * 采样数量,1024)
box_features = 将box_features经过TWOMLPHead
# --------------------TWOMLPHead结束--------
# --------------------box_predictor开始--------
# class_logits的shape为(batch_size * 采样数量,21)
# class_logits的shape为(batch_size * 采样数量,21 * 4)
class_logits, box_regression = 将box_features经过FastRCNNPredictor,得到预测目标类别和边界框回归参数
# --------------------box_predictor结束--------
#--------------------计算损失开始-----------
如果是训练模式,就开始计算损失
losses = {}
classification_loss = 对于分类损失,使用交叉熵损失,计算预测分类class_logits与真实分类标签labels的差值
sampled_pos_inds_subset = 获得正样本索引
# 返回正样本对应的真实标签
labels_pos = labels[sampled_pos_inds_subset]
# shape=[num_proposal, num_classes]
N, num_classes = class_logits.shape
box_regression = box_regression.reshape(N, -1, 4)
# 计算边界框损失信息
box_loss = 使用smooth_l1_loss计算box_regression[sampled_pos_inds_subset, labels_pos]与 \
regression_targets[sampled_pos_inds_subset]的损失/ labels.numel()
losses = {
"loss_classifier": classification_loss ,
"loss_box_reg": box_loss
}
#--------------------计算损失结束-----------
# ----------------- 预测模式开始-----------
如果是预测模式,是不需要计算损失的,所以不需要上边的选择正负样本以及计算损失部分
# 对预测结果进行后处理
(1)根据proposal以及预测的回归参数计算出最终bbox坐标
(2)对预测类别结果进行softmax处理
(3)裁剪预测的boxes信息,将越界的坐标调整到图片边界上
(4)移除所有背景信息
(5)移除低概率目标
(6)移除小尺寸目标
(7)执行nms处理,并按scores进行排序
(8)根据scores排序返回前topk个目标
all_boxes, all_scores, all_labels = 存储得到的boxes、scores、labels信息
for i in range(batch_size):
result.append(
{
"boxes": boxes[i],
"labels": labels[i],
"scores": scores[i],
}
)
# ------------------预测模式结束-------------
3.RoIpooling
1.参数
由霹雳吧啦Wz分享的Faster RCNN代码来看,RoIpooling 是torchvision.ops下的MultiScaleRoIAligin.方法。
图1是backbone是mobilenet v2的情况下RoIpooling的实现:

图2是backbone是resnet50+FPN的情况下RoIpooling的实现:

使用到了三个参数:
- featmap_names:在哪些特征层上进行roi_pooling,对于mobilenet v2只输出一个特征层,而在之前的第五章部分,features中key值我们赋值了’0’,所以这里写[‘0’],对于resnet50 + FPN,输出key值为[‘0’,‘1’,‘2’,‘3’,‘pool’]五个特征层,至于为什么是写[‘0’,‘1’,‘2’,‘3’],这里先画个?
- output_size = [7,7],经过RoIAlign输出的尺寸为7×7
- sampling_ratio=2 采样率
2.作用
输入到Roi_heads中的proposals(也就是过滤后的anchors)其除了channel是一样的,宽度和长度都是各异的,无法直接输入到Two MLPHead中,所以需要将proposals统一尺寸。
3.过程
MultiScaleRoIAligin实际上就是一个多预测特征层的RoIAligin函数。而至于RoIAlign函数,torchvision.ops.roi_aligin并没有具体实现方法,,大致原理可以参考博客园的一篇帖子或者知乎上的一篇帖子(内容是一样的。)
4.Two MLPHead(box_head)
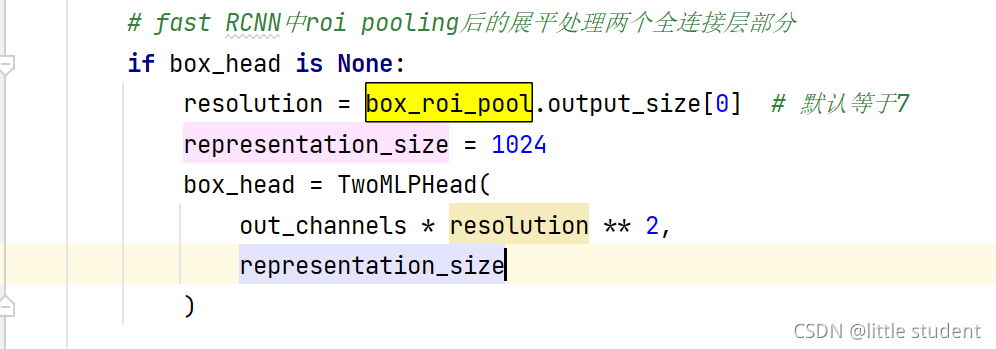

(图片来源)

结合以上三个图可知,TwoMLPHead共有两个参数:
- 第一个参数是第一个fc层的输入,也就是经过RoIpooling之后再flatten后的元素数,即out_channels * resolution ** 2(该特征图7*7大小,out_channles个通道)
- 第二个参数是第一个fc层的输出以及第二个fc层的输入和输出
5.FastRCNNPredictor(box_predictor)


由上图可知,FastRCNNPredictor包含两个参数:
- in_channels:是Two MLPHead的输出通道数
- num_classes: 数据集的类别+背景类数量
6.计算边界框损失(smooth_l1_loss)
smooth_l1_loss的代码如下:
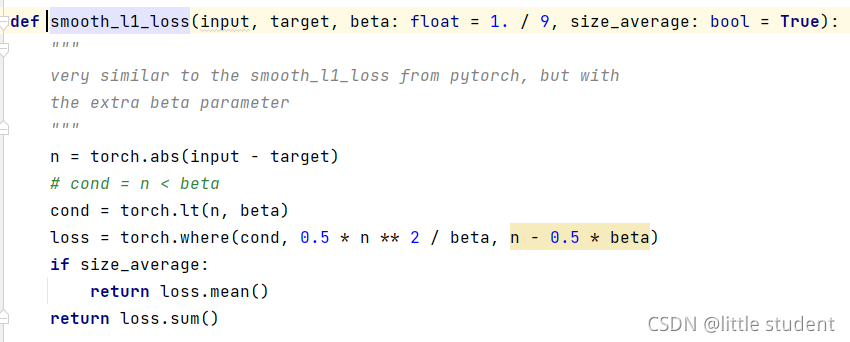
与论文中的实现稍微不同的是,论文中的是:

即当真实值与预测值差值的绝对值小于1的话,则是差值平方的0.5,反正则是第二种情况。
而Faster RCNN代码中的smooth_l1_loss引入了一个超参数beta,来替代这里的1。
所以就是如下情形:

7.Roi_heads的输入与输出
roi_heads的输入:
-
features:经过backbone后得到的一个有序字典
features:{ key:'0' value:backbone得到的第0层特征层 ......} -
proposals:经过生成anchors、修正anchors、依据分类概率删选一定数量、调整过界anchors、滤除小概率、经过nms操作后得到的anchors
proposals 列表形式,共batch_size个元素,每个元素shape:(self.post_nms_top,4) -
images.image_sizes:图像标准化并resize之后但是没有进行统一尺寸操作的尺寸
-
targets:经过第四章GeneralizedRCNNTransform处理(缩放)后的带有gt boxes信息的字典
targets:[ {'boxes':tensor[xmin,ymin,xmax,ymax],'lables':tensor[分类索引],'image_id':tensor[图片索引],'area':tensor[图像面积],'iscorwd':tensor[检测难度对应数值]}, ... ... 共batch_size个有序字典 ]
roi_heads的输出:
-
detections:在预测模式下的roi_heads的实际输出,如果是训练模式,其则返回一个空的列表。有值的情况下共batch_size个元素,每个元素都是一个字典,字典如下所示,记录着预测的边界框、标签、概率。
"boxes": boxes[i], "labels": labels[i], "scores": scores[i] -
detector_losses:在预测模式下是一个空字典{},在训练模式下,其key与value值如下所示:
"loss_classifier": 分类损失, "loss_box_reg": 边界框回归损失
八、 预测结果映射回原尺度

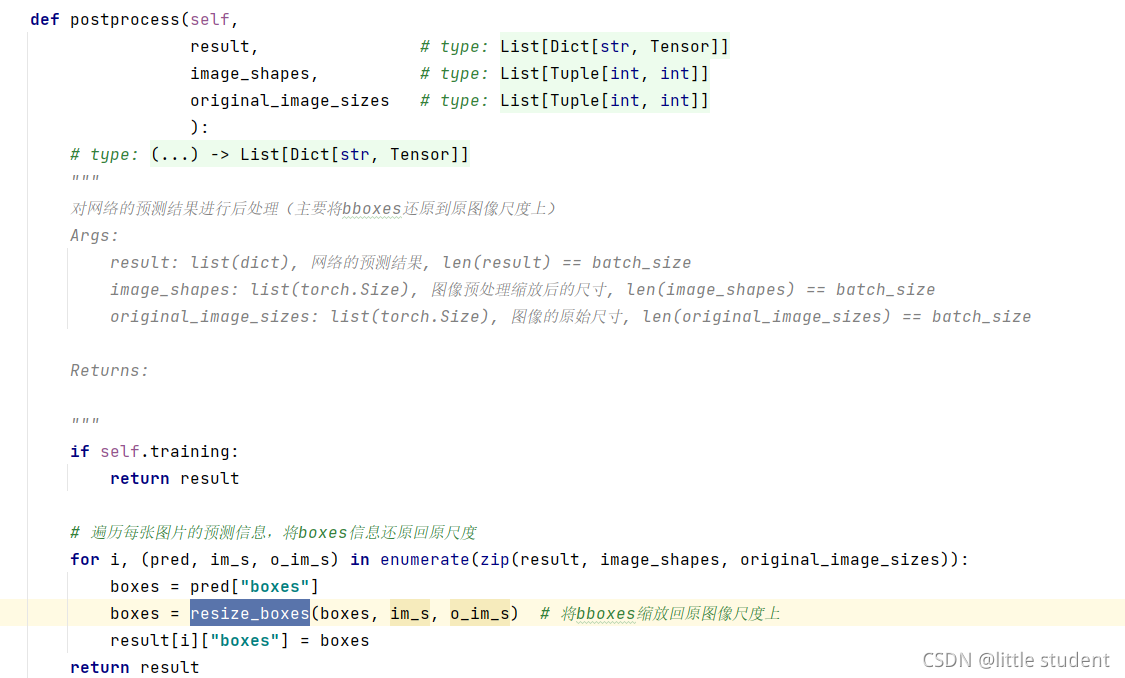
使用transform.py文件中的postprocess将bboxes信息还原到原图像中。
其中的original_image_sizes是在数据预处理之前获得的,如下图所示:
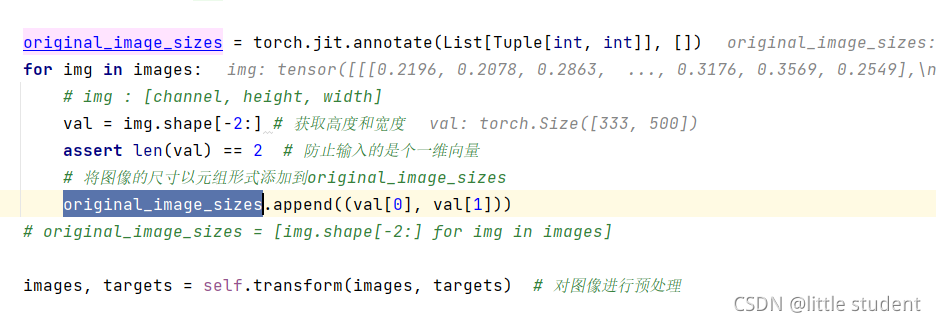
结果如下图所示:

九、Faster RCNN流程再回顾
original_image_sizes = torch.jit.annotate(List[Tuple[int, int]], [])
for img in images:
# img : [channel, height, width]
val = img.shape[-2:] # 获取高度和宽度
assert len(val) == 2 # 防止输入的是个一维向量
# 将图像的尺寸以元组形式添加到original_image_sizes
original_image_sizes.append((val[0], val[1]))
# original_image_sizes = [img.shape[-2:] for img in images]
images, targets = self.transform(images, targets) # 对图像进行预处理
# print(images.tensors.shape)
features = self.backbone(images.tensors) # 将图像输入backbone得到特征图
if isinstance(features, torch.Tensor): # 若只在一层特征层上预测,将feature放入有序字典中,并编号为‘0’
features = OrderedDict([('0', features)]) # 若在多层特征层上预测,传入的就是一个有序字典
# 将特征层以及标注target信息传入rpn中
# proposals: List[Tensor], Tensor_shape: [num_proposals, 4],
# 每个proposals是绝对坐标,且为(x1, y1, x2, y2)格式
proposals, proposal_losses = self.rpn(images, features, targets)
# 将rpn生成的数据以及标注target信息传入fast rcnn后半部分
detections, detector_losses = self.roi_heads(features, proposals, images.image_sizes, targets)
# 对网络的预测结果进行后处理(主要将bboxes还原到原图像尺度上)
detections = self.transform.postprocess(detections, images.image_sizes, original_image_sizes)
losses = {}
losses.update(detector_losses)
losses.update(proposal_losses)



















 5784
5784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}