










 本文探讨了在深度学习模型训练过程中遇到的梯度爆炸和梯度消失问题,可能导致模型loss不降且准确率极低。作者分享了自身遇到的梯度爆炸实例,并提供了检查模型学习情况的方法。解决梯度爆炸的策略包括更换优化器、降低学习率、使用梯度截断和调整正则化参数。通过对模型权重更新幅度的观察,可以判断模型是否遭受梯度问题的影响。
本文探讨了在深度学习模型训练过程中遇到的梯度爆炸和梯度消失问题,可能导致模型loss不降且准确率极低。作者分享了自身遇到的梯度爆炸实例,并提供了检查模型学习情况的方法。解决梯度爆炸的策略包括更换优化器、降低学习率、使用梯度截断和调整正则化参数。通过对模型权重更新幅度的观察,可以判断模型是否遭受梯度问题的影响。
loss不下降,ACC很低(只有0.1,0.2这种)
可能的原因有:
- 数据集有问题(噪声过多或存在过多的标签错误或类别不平衡)
- 梯度爆炸
- 梯度消失
笔者遇到的梯度爆炸情况
下图的矩阵是pooler_output(从bert得到的句子向量):
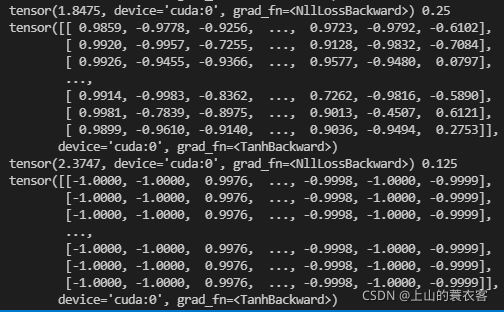
若干个不同的文本,在训练两个batch后可见模型的输出几乎一样了,这正是梯度爆炸的原因
梯度异常检验
检验模型权重更新情况、句子向量、loss值
model = BERT()
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.00001, betas=(0.9, 0.999), eps=1e-6, weight_decay=0.01)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.1)
for i in range(epoch):
train_loader = iter(tasks_config['train_loader'])
for input_data in train_loader:
# print(input_data) # 查看模型的输入有无问题
for name, _ in input_data.items():
input_data[name] = input_data[name].to(torch.float16).long().to(device)
label = input_data.pop("label")
optimizer.zero_grad()
model_output, pooler_output = model(input_data)
Before = list(model.parameters())[0].clone() # 获取更新前模型的第0层权重
loss = criterion(model_output, label)
loss.backward()
# nn.utils.clip_grad_norm_(model.parameters(), max_norm=20, norm_type=2) # 梯度截断
optimizer.step()
# 检验模型的学习情况
After = list(model.parameters())[0].clone() # 获取更新后模型的第0层权重
predicted_label = torch.argmax(model_output, -1)
acc = accuracy_score(label.float().cpu(), predicted_label.view(-1).float().cpu())
print(loss,acc) # 打印mini-batch的损失值以及准确率
print('模型的第0层更新幅度:',torch.sum(After-Before))
print(pooler_output) # 打印句向量
- 梯度正常,更新幅度大约-15

- 梯度爆炸,更新幅度-1k+

- 梯度消失,更新幅度小于1e-2

梯度爆炸的解决方法
- 更换优化器
- 学习率小于1e-4
- 梯度截断
- 最大的正则化参数

















 4619
4619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









