







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
以回归模型为例进行说明,回归的目的是为了预测未来某段数据,那么除训练集损失函数之外,应该使用其他更有效的评估标准,来保证训练的模型在测试机上有良好的表现。
提示:以下是本篇文章正文内容,下面案例可供参考
1.超参数优化基础
1.1偏差-方差的权衡
模型的训练均方误差达到很小时,测试均方误差反而很大,但是我们寻找的最优的模型是测试均方误差达到最小时对应的模型,因此基于训练均方误差达到最小选择模型本质上是行不同的。
易证
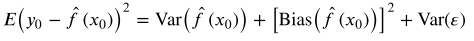
也即测试均方误差的期望值可以分解为 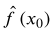 的方差、
的方差、 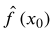 的偏差平方和误差项
的偏差平方和误差项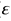 的方差。
的方差。
要找到一个方差–偏差的权衡,使得测试均方误差最小。
1.2特征提取
除不确定的误差方差var(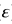 )外,就有两种方式可以降低测试误差,一种是对。一种是修正训练误差,即添加惩罚项,另一种是使用交叉验证集。
)外,就有两种方式可以降低测试误差,一种是对。一种是修正训练误差,即添加惩罚项,另一种是使用交叉验证集。
1.2.1修正训练误差
模型越复杂,训练误差越小。先随意构造一个的模型使其过拟合,此时训练误差很小而测试误差很大,然后加入关于特征个数的惩罚。训练误差随着特征个数的增加而减少时,惩罚项因为特征数量的增加而增大,抑制了训练误差随着特征个数的增加而无休止地减小,从而达到降低测试误差的目的。

一般来说有两个准则,
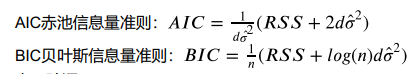
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import warnings
plt.style.use('ggplot')
import seaborn as sns
from sklearn import datasets
from sklearn import linear_model
from sklearn.preprocessing import PolynomialFeatures
from pygam import LinearGAM
from sklearn.tree import DecisionTreeRegressor
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
import statsmodels.api as sm
from statsmodels.formula.api import ols
from sklearn import linear_model
# AIC准则前向逐步回归
def forward_select(data, target):
variate = set(data.columns)
variate.remove(target)
selected = []
current_score, best_new_score = float('inf'), float('inf')
while variate:
aic_with_variate = []
for candidate in variate: # 逐个遍历自变量
formula = "{}~{}".format(target, "+".join(selected + [candidate])) # 将自变量名连接
aic = ols(formula=formula, data=data).fit().aic # 利用ols训练模型得出aic值
aic_with_variate.append((aic, candidate)) # 将第每一次的aic值放进空列表
aic_with_variate.sort(reverse=True) # 降序排序aic值
best_new_score, best_candidate = aic_with_variate.pop() # 最好的aic值等于删除列表的最后
if current_score > best_new_score: # 如果目前的aic值大于最好的aic值
variate.remove(best_candidate) # 移除加进来的变量名,即第二次循环时,不考虑此自
selected.append(best_candidate) # 将此自变量作为加进模型中的自变量
current_score = best_new_score # 最新的分数等于最好的分数
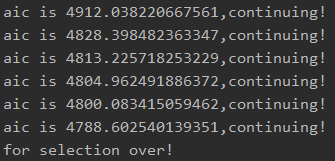
print("aic is {},continuing!".format(current_score)) # 输出最小的aic值
else:
print("for selection over!")
break
formula = "{}~{}".format(target, "+".join(selected)) # 最终的模型式子
print("final formula is {}".format(formula))
model = ols(formula=formula, data=data).fit()
return (model)
diabetes = datasets.load_diabetes()
x = diabetes.data
y = diabetes.target
features = diabetes.feature_names
diabetes_data = pd.DataFrame(x, columns=features)
diabetes_data['ill_degree'] = y
forward_select(data = diabetes_data, target = 'ill_degree')
lm = ols("ill_degree~age+sex+bmi+bp+s3+s5",data = diabetes_data).fit()
print(lm.summary())
final formula is ill_degree~bmi+s5+bp+s1+sex+s2
OLS Regression Results
==============================================================================
Dep. Variable: ill_degree R-squared: 0.509
Model: OLS Adj. R-squared: 0.502
Method: Least Squares F-statistic: 75.06
Date: Mon, 22 Mar 2021 Prob (F-statistic): 4.64e-64
Time: 23:35:09 Log-Likelihood: -2390.1
No. Observations: 442 AIC: 4794.
Df Residuals: 435 BIC: 4823.
Df Model: 6
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 152.1335 2.588 58.785 0.000 147.047 157.220
age -13.3473 59.005 -0.226 0.821 -129.318 102.623
sex -234.1217 60.975 -3.840 0.000 -353.964 -114.280
bmi 524.0346 65.398 8.013 0.000 395.499 652.570
bp 329.4060 64.689 5.092 0.000 202.265 456.547
s3 -287.7806 65.982 -4.362 0.000 -417.464 -158.098
s5 476.7325 66.634 7.154 0.000 345.767 607.698
==============================================================================
Omnibus: 2.369 Durbin-Watson: 1.991
Prob(Omnibus): 0.306 Jarque-Bera (JB): 2.032
Skew: 0.049 Prob(JB): 0.362
Kurtosis: 2.683 Cond. No. 32.8
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
1.2.2交叉验证
交叉验证是对测试误差的直接估计。在这里只介绍K折交叉验证:我们把训练样本分成K等分,然后用K-
1个样本集当做训练集,剩下的一份样本集为验证集去估计由K-1个样本集得到的模型的精
度,这个过程重复K次取平均值得到测试误差的一个估计
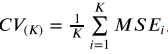
1.3正则化
正则化是对回归的系数进行约束或者加罚的技巧,对p个特征的模型进行拟合,显著降低模型方差,这样也会提高模型的拟合效果。正则化有两种方法:岭回归,拉索回归。
1.3.1岭回归
线性回归中损失函数为
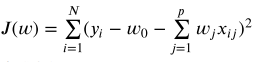
那么以此为例,为期添加系数的约束或惩罚,使损失函数变为
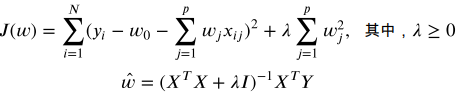
那么与自变量无关的λ就变得十分重要,J的目标是变小,此时若λ越大,则w应更小,说明惩罚的力度越大。领回归通过牺牲线性回归的无偏性来降低方差。能够降低模型整体测试误差,提高模型泛化能力。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import warnings
plt.style.use('ggplot')
import seaborn as sns
from sklearn import datasets
from sklearn import linear_model
from sklearn.preprocessing import PolynomialFeatures
from pygam import LinearGAM
from sklearn.tree import DecisionTreeRegressor
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
import statsmodels.api as sm
from statsmodels.formula.api import ols
from sklearn import linear_model
# 岭回归
reg_rid = linear_model.Ridge(alpha = 0.0001)
print(reg_rid.fit(x, y))
print(reg_rid.score(x, y))
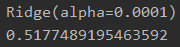
1.3.2lasso回归
将岭回归中惩罚项换位L2番薯记得到lasso回归的损失函数
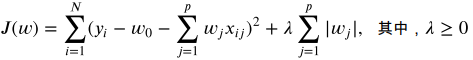
这样做是为了能进行特征选择。岭回归会使模型的系数w变小至趋于0的状态,这样是无法特征选择的。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import warnings
plt.style.use('ggplot')
import seaborn as sns
from sklearn import datasets
from sklearn import linear_model
from sklearn.preprocessing import PolynomialFeatures
from pygam import LinearGAM
from sklearn.tree import DecisionTreeRegressor
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
import statsmodels.api as sm
from statsmodels.formula.api import ols
from sklearn import linear_model
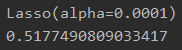
# lasso回归
reg_lasso = linear_model.Lasso(alpha = 0.0001)
print(reg_lasso.fit(x, y))
print(reg_lasso.score(x, y))
1.4降维
将浴室特征空间投影到另一个低维的空间中,已实现控制变量的数目。主要方法就是主成分分析。其思想是通过最大投影方差将原始空间重构。
















 939
939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









