







深入解析TTS技术与SSML语音合成标记语言
深入解析TTS技术与SSML语音合成标记语言
一、TTS技术概述
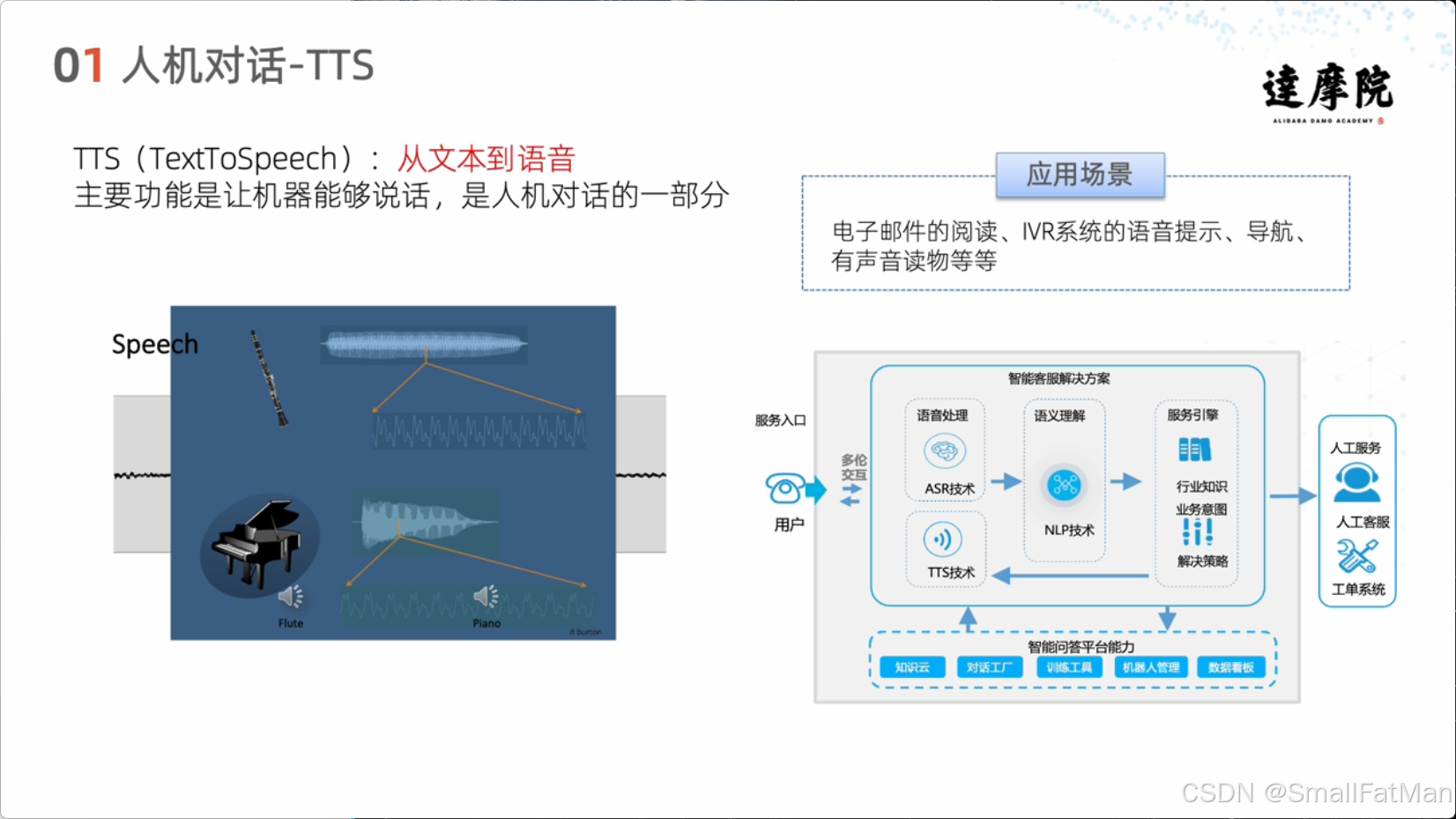
TTS(Text To Speech,文本转语音)技术是人机对话的重要组成部分,主要功能是让机器能够"说话"。这项技术已经广泛应用于多个场景:
- 电子邮件的语音阅读
- IVR(交互式语音应答)系统的语音提示
- 导航系统的语音引导
- 有声读物的自动生成
- 智能客服解决方案
TTS技术的核心目标是将书面文本转换为自然流畅的语音输出,使得人机交互更加自然和高效。
二、TTS处理流程详解

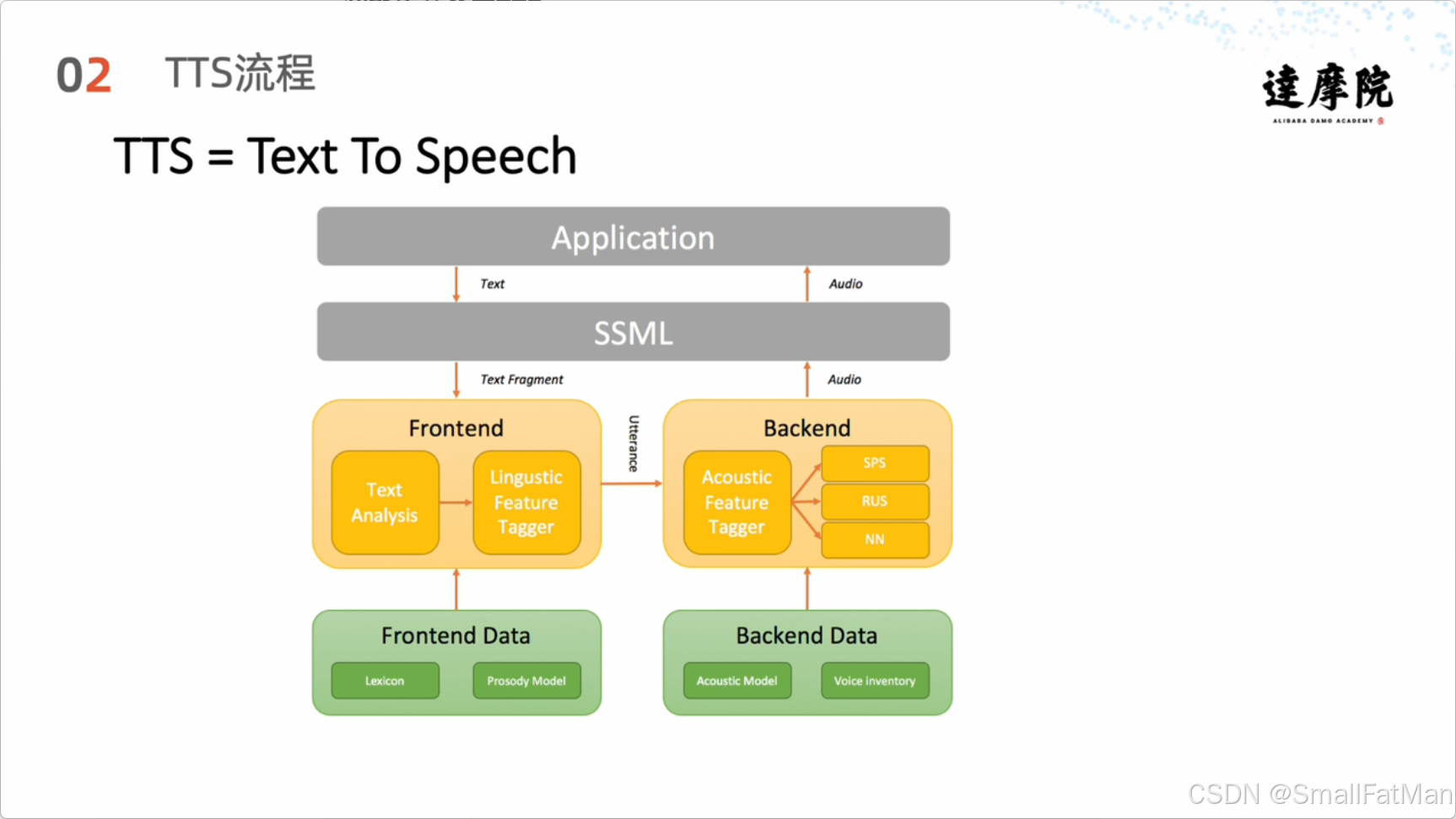
完整的TTS处理流程可以分为前端和后端两大模块:
前端处理(文本分析)
-
文本规范化(Text Normalization):
- 将非标准文本转换为标准形式
- 示例转换:
"小明就岁了,这是他第1次和奶奶一起旅行。"→"小明就两岁了,这是他第一次和奶奶一起旅行。"
-
句子分割(Sentence Separator):
- 将段落拆分为独立句子
- 示例:
"小明就两岁了,这是他第一次和奶奶一起旅行。"→"小明就两岁了。"+"这是他第一次和奶奶一起旅行。"
-
分词(Word Breaker):
- 将句子分解为词语
- 示例:
"小明就两岁了。"→"小/男孩/两/岁/了/。"
-
词性标注(POS Tagger):
- 为每个词语标注词性
- 示例:
"小/男孩/两/岁/Rt 7/n, /wj"
-
发音标注(Pronunciation Tagger):
- 标注每个词语的发音
- 示例:
"siao3 / nan2 / hia2 / liang3 / suia4 / lis5 /"
-
韵律标注(Break Tagger):
- 标注词语间的停顿和韵律
- 示例:
"小明就1两岁了M"
后端处理(语音合成)
-
语言学特征标注(Linguistic Tagger):
- 分析上下文因素值
-
声学特征标注(Acoustic Tagger):
- 确定持续时间、音高、频谱等参数
-
波形生成(Wave Generation):
- 使用多种技术生成最终语音波形
- 常用技术:SPS(信号处理合成)、NN(神经网络)、RUS(规则合成)
三、SSML语音合成标记语言

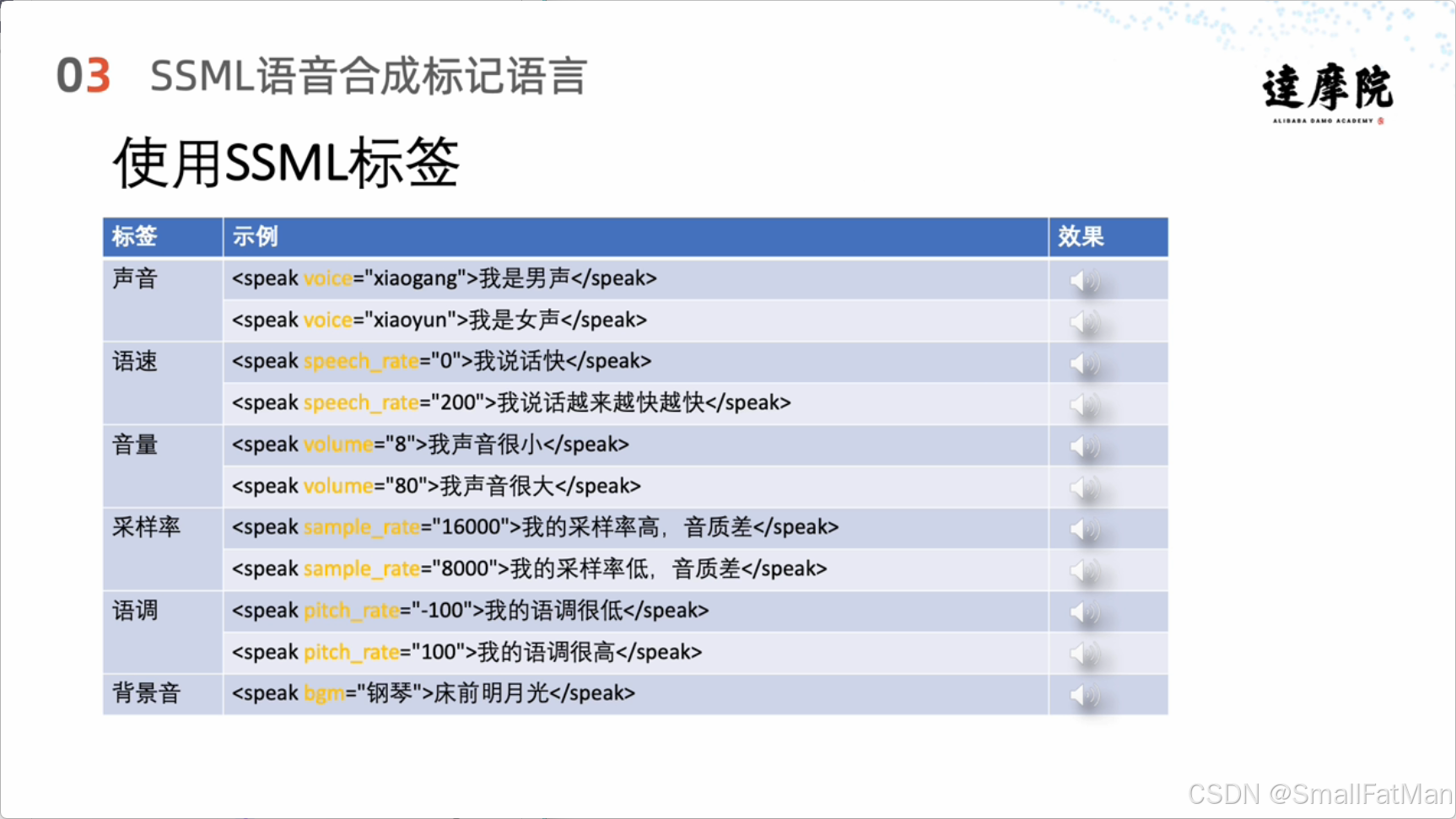

SSML(Speech Synthesis Markup Language)是W3C制定的语音合成标记语言,用于精确控制语音合成的各个方面。
SSML核心功能
-
发音人控制:
<speak voice="xiaogang">我是男声</speak> <speak voice="xiaoyun">我是女声</speak> -
语速调节:
<speak speech_rate="0">我说话快</speak> <speak speech_rate="200">我说话越来越快越快</speak> -
音量控制:
<speak volume="8">我声音很小</speak> <speak volume="80">我声音很大</speak> -
高级文本处理:
- 分句:
<speak>您本月车贷已经到期。<s>请问您的款项是否已存入卡中?</s></speak> - 分词消歧:
<speak>南京<w>市长</w>江大桥。</speak> <speak>南京市<w>长江大桥</w>。</speak> - 特殊发音:
<speak>去<phoneme alphabet="py" ph="diana danga' hang2">典当行</phoneme>把这个玩意<phoneme alphabet="py" ph="danga'diao4">当掉</phoneme></speak>
- 分句:
-
数字和符号处理:
<speak>三零四按数字读<say-as interpret-as="digits">304</say-as></speak> <speak>三零四按整数读<say-as interpret-as="cardinal">304</say-as></speak> <speak>一万按电话读<say-as interpret-as="telephone">10000</say-as></speak> <speak>地址<say-as interpret-as="address">锦云府3-1-3205</say-as></speak> -
停顿控制:
<speak>接下来你将听到一秒静音<break time="1s"/>静音结束</speak>
四、TTS技术架构
完整的TTS系统架构包含以下组件:
- 服务入口:接收用户请求
- 语音处理模块:处理原始语音输入(ASR)
- 语义理解模块:使用NLP技术解析文本
- 服务引擎:结合行业知识和业务意图生成解决方案
- ASI技术:高级语音接口处理
- 数据问答平台:提供知识支持
- 分发系统:将结果传递给用户
五、应用与发展趋势
随着人工智能技术的进步,TTS系统正变得更加自然和智能。未来发展趋势包括:
- 情感化语音合成:能够表达不同情感的语音输出
- 个性化声音克隆:根据少量样本克隆特定人的声音
- 多语言混合合成:无缝切换不同语言的语音输出
- 实时自适应调整:根据上下文自动调整语音参数
六、总结
TTS技术作为人机交互的重要桥梁,正在不断演进和完善。通过SSML等标记语言,开发者可以精确控制语音合成的各个方面,创造出更加自然、富有表现力的语音体验。随着深度学习等技术的发展,未来的语音合成将更加接近人类自然语音,为人机交互开辟更多可能性。
参考资源:
- W3C SSML规范:https://www.w3.org/TR/speech-synthesis11/
- 语音合成技术白皮书
- 神经网络语音合成最新研究进展



















 3583
3583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











