







文章目录
- 1.为什么只有~析构函数不论基类和派生类都用到了virtual关键字?
- 2.c++ inline使函数实现可以在头文件中,避免多重定义错误
- 3.this->
- 4.调用另一个cpp文件中函数(多个.cpp文件编译)
- 5.有空看看开源项目glog(谷歌日志系统)
- 6.类访问控制关键字public、protected、private的区别
- 7.类的参数
- 8.模板template
- 9.冒号:的作用
- 10.C++中explicit的用法
- 11.为什么要在类的成员函数后加const?
- 12.虚函数
- 13.关键字"override"
- 14.atomic 为什么要定义一个原子类型?
- 15.emplace_back
- 16.lock_guard
- 17.multiple definition of `xxxx`问题解决及其原理
- 18.虚函数编译提示undefined reference to ‘vtable‘
- 19.数据类型与其大小简单一览表
- 20.编译报错undefind reference to 'pthread_create'
- 21.emplace_back与push_back
- 22.double类型隐式转换int
- 23.std::system_error
- 24.python调用dll函数,参数报错,提示类型未知
- 25.编译后运行时出现的问题:无法定位程序输入点__gxx_personality_v0
- 26.Python x64下ctypes动态链接库出现access violation
1.为什么只有~析构函数不论基类和派生类都用到了virtual关键字?
C++中基类采用virtual虚析构函数主要目的是为了防止潜在的内存泄漏。
具体地说,如果派生类中申请了内存空间,并在其析构函数中对这些内存空间进行释放。假设基类中采用的是非虚析构函数,当删除基类指针指向的派生类对象时就不会触发动态绑定,因而只会调用基类的析构函数,而不会调用派生类的析构函数。那么在这种情况下,派生类中申请的空间就得不到释放从而产生内存泄漏。所以,为了防止这种情况的发生,C++中基类的析构函数应采用virtual虚析构函数。
关于虚函数的笔记看第12点。
2.c++ inline使函数实现可以在头文件中,避免多重定义错误
inline最大的用处是: 非template 函数,成员或非成员 ,把定义放在头文件中,定义前不加inline ,如果头文件被多个translation unit(cpp文件)引用,ODR会报错multiple definition。
3.this->
this 是 C++ 中的一个关键字,也是一个 const指针,它指向当前对象,通过它可以访问当前对象的所有成员。this 是一个指针,要用 ->来访问成员变量或成员函数。
4.调用另一个cpp文件中函数(多个.cpp文件编译)
首先两个cpp文件都导入需要的函数声明所在的.h文件。
第一种方法是分别将两个cpp文件编译为.o文件,然后进行连接。
g++ -c main.cpp -o main.o
g++ -c fun.cpp -o fun.o
g++ main.o fun.o -o out
第二种方法是使用vscode编译器,在tasks.json中加入需要一起编译的文件
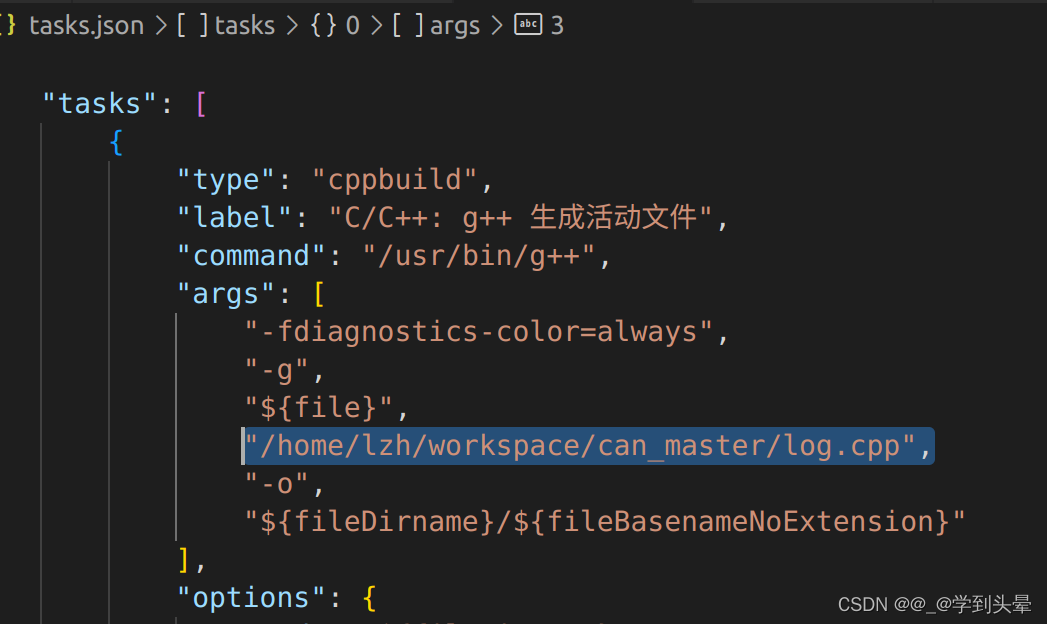
5.有空看看开源项目glog(谷歌日志系统)
6.类访问控制关键字public、protected、private的区别
1)private,public,protected的访问范围:
private: 只能由该类中的函数、其友元函数访问,不能被任何其他访问,该类的对象也不能访问.
protected: 可以被该类中的函数、子类的函数、以及其友元函数访问,但不能被该类的对象访问
public: 可以被该类中的函数、子类的函数、其友元函数访问,也可以由该类的对象访问
注:友元函数包括两种:设为友元的全局函数,设为友元类中的成员函数
在不加声明时,类的成员默认为private成员。
- 继承控制:
| 类自己 | 类的实例化对象 | 类的派生类 | |
|---|---|---|---|
| public成员 | yes | yes | yes |
| protect成员 | yes | no | yes |
| private成员 | yes | no | no |
2)类的继承后方法属性变化:
使用private继承,父类的所有方法在子类中变为private;
使用protected继承,父类的protected和public方法在子类中变为protected,private方法不变;
使用public继承,父类中的方法属性不发生改变;
public:可以被任意实体访问
protected:只允许子类及本类的成员函数访问
private:只允许本类的成员函数访问
在不加声明时,类的默认继承方式为private继承。
- 继承控制:
| public继承 | protect继承 | private继承 | |
|---|---|---|---|
| 父类的public成员 | public | protect | private |
| 父类的protected成员 | protect | protect | private |
| 父类的private成员 | 不可见 | 不可见 | 不可见 |
7.类的参数
使用类的时候进行实例,如果有参数会将参数传入类中定义的构造函数里,可以给成员变量赋值。
8.模板template
模板是C++支持参数化多态的工具,使用模板可以使用户为类或者函数声明一种一般模式,使得类中的某些数据成员或者成员函数的参数、返回值取得任意类型。
使用模板的目的就是能够让程序员编写与类型无关的代码。比如编写了一个交换两个整型int 类型的swap函数,这个函数就只能实现int 型,对 double ,字符这些类型无法实现,要实现这些类型的交换就要重新编写另一个swap函数。使用模板的目的就是要让这程序的实现与类型无关,比如一个swap模板函数,即可以实现int 型,又可以实现double型的交换。模板可以应用于函数和类。
注意:模板的声明或定义只能在全局,命名空间或类范围内进行。即不能在局部范围,函数内进行,比如不能在main函数中声明或定义一个模板。
9.冒号:的作用
9.1 单冒号(😃
1)在构造函数后面,冒号起分割作用,是类给成员变量赋值的方法,初始化列表,更适用于成员变量的常量const型。
Byte::Byte(constuint8_t *value) : value_(const_cast)
2)类名冒号后面的是用来定义类的继承。
class 派生类名 : 继承方式 基类名
{
派生类的成员
};
3)public:和private:后面的冒号,表示后面定义的所有成员都是公有或私有的,直到下一个"public:”或"private:”出现为止。"private:"为默认处理。
4)表示机构内位域的定义(即该变量占几个bit空间)
typedef struct _XXX
{
unsigned char a:4;
unsigned char c;
} ; XXX
9.2 双冒号(😃
1)表示“域操作符”
例:声明了一个类A,类A里声明了一个成员函数void f(),但没有在类的声明里给出f的定义,那么在类外定义f时,
就要写成void A::f(),表示这个f()函数是类A的成员函数。
2)直接用在全局函数前,表示是全局函数
例:在VC里,你可以在调用API 函数里,在API函数名前加::
3)表示引用成员函数及变量,作用域成员运算符
例:System::Math::Sqrt() 相当于System.Math.Sqrt()
10.C++中explicit的用法
C++提供了关键字explicit,可以阻止不应该允许的经过转换构造函数进行的隐式转换的发生,声明为explicit的构造函数不能在隐式转换中使用。
C++中, 一个参数的构造函数(或者除了第一个参数外其余参数都有默认值的多参构造函数), 承担了两个角色。
1 是个构造;2 是个默认且隐含的类型转换操作符。
所以, 有时候在我们写下如 AAA = XXX, 这样的代码, 且恰好XXX的类型正好是AAA单参数构造器的参数类型, 这时候编译器就自动调用这个构造器, 创建一个AAA的对象。这样看起来好象很酷, 很方便。 但在某些情况下, 却违背了程序员的本意。 这时候就要在这个构造器前面加上explicit修饰, 指定这个构造器只能被明确的调用/使用, 不能作为类型转换操作符被隐含的使用。
解析:explicit构造函数是用来防止隐式转换的。
隐式类型转换 ( 构造函数的隐式调用 )
先来看一下这种隐式类型转换是怎么发生的吧.
#include <iostream>
using namespace std;
class Point {
public:
int x, y;
Point(int x = 0, int y = 0)
: x(x), y(y) {}
};
void displayPoint(const Point& p)
{
cout << "(" << p.x << ","
<< p.y << ")" << endl;
}
int main()
{
displayPoint(1);
Point p = 1;
}
我们定义了一个再简单不过的 Point类, 它的构造函数使用了默认参数. 这时主函数里的两句话都会触发该构造函数的隐式调用. (如果构造函数不使用默认参数, 会在编译时报错)
显然, 函数 displayPoint需要的是 Point类型的参数, 而我们传入的是一个 int, 这个程序却能成功运行, 就是因为这隐式调用. 另外说一句, 在对象刚刚定义时, 即使你使用的是赋值操作符 =, 也是会调用构造函数, 而不是重载的 operator=运算符.
这样悄悄发生的事情, 有时可以带来便利, 而有时却会带来意想不到的后果. explicit关键字用来避免这样的情况发生。
11.为什么要在类的成员函数后加const?
class CanReader
{
public:
CanReader();
~CanReader();
bool IsRunning() const; //const修饰
};
我们定义的类的成员函数中,常常有一些成员函数不改变类的数据成员,也就是说,这些函数是"只读"函数,而有一些函数要修改类数据成员的值。如果把不改变数据成员的函数都加上const关键字进行标识,显然,可提高程序的可读性。其实,它还能提高程序的可靠性,已定义成const的成员函数,一旦企图修改数据成员的值,则编译器按错误处理。
12.虚函数
C++通过虚函数实现动态绑定。
12.1 成员函数为虚函数
在开始虚函数之前,先看一段代码分析其中的问题。
#include <iostream>
class Animal
{
public:
Animal() {}
~Animal() {}
void run(void)
{
std::cout << "Animal run..." << std::endl;
}
};
class Cat : public Animal
{
public:
Cat() : Animal() {}
void run(void)
{
std::cout << "Cat run..." << std::endl;
}
};
int main(int argc, char **argv)
{
Animal *animal = new Cat; //创建Cat对象,然后执行向上类型转换
animal->run();
return 0;
}
/*输出结果*/
// Animal run...
在以上代码中,animal所指向的为Cat对象,但是当调 用run函数的时候,打印的值是"Animal run…“,并不是"Cat run…”,这是因为当编译器看到 "animal"的指针类型是"Animal"时 ,自然而然的就会调用 Animal::run() ,在编译时期,就已经确定所要调用的具体函数,这也就是所说的 静态绑定 。
在开始后面讲解之前,需要先记住两点知识:
- 声明一个虚函数需要使用关键字:virtual
- 当 基类 (或称为 父类 )中的某函数 A() 被声明为虚函数之后,在 继生类 (或称为 子类 )中重载的 A() ,即不使用virtual修饰,也是虚函数
现在对上面的代码进行修改,将 void Animal::run()修改为虚函数,即改为 virtual void Animal::run(),观察修改后的运行情况。
#include <iostream>
class Animal
{
public:
Animal() {}
~Animal() {}
virtual void run(void)
{ //!!!!!!!!!!注意此处的修改
std::cout << "Animal run..." << std::endl;
}
};
class Cat : public Animal
{
public:
Cat() : Animal() {}
void run(void)
{
std::cout << "Cat run..." << std::endl;
}
};
int main(int argc, char **argv)
{
Animal *animal = new Cat; //创建Cat对象,然后执行向上类型转换
animal->run();
return 0;
}
//输出结果:
// Cat run...
当 Animal::run()为虚函数时,输出结果为 Cat run… ,这也就是虚函数的作用,此时在程序运行时去决定调用哪一个 run()函数,这也就是 动态绑定 。在这里animal实际上指向的是 Cat对象 ,所以调用的是 Cat::run()。
12.2 析构函数为虚函数
当基类中包含虚成员函数的时候,一般会把析构函数也定义为虚析构函数
虚析构函数和虚成员函数在函数定义上是一样的,只需要添加 virtual关键字就可以了,这里主要介绍定义虚析构函数的原因:
- 为了通过基类指针正确释放该指针所指向的对象(该指针可能指向一个子类)
通过实例了解一下:
#include <iostream>
class Base1 {
public:
virtual void print(void) {
std::cout << "Base1 print" << std::endl;
}
~Base1(){
std::cout << "Base1's destructor" << std::endl;
}
};
class Derived1 : public Base1
{
public:
Derived1(int n) {
p = new char[n];
}
void print(void) {
std::cout << "Derived1 print" << std::endl;
}
~Derived1() {
delete[]p;
std::cout << "Derived1's destructor" << std::endl;
}
private:
char *p;
};
class Base2 {
public:
virtual void print(void) {
std::cout << "Base2 print" << std::endl;
}
virtual ~Base2() {
std::cout << "Base2's destructor" << std::endl;
}
};
class Derived2 : public Base2
{
public:
Derived2(int n) {
p = new char[n];
}
void print(void) {
std::cout << "Derived2 print" << std::endl;
}
~Derived2() {
delete[]p;
std::cout << "Derived2's destructor" << std::endl;
}
private:
char *p;
};
int main(int argc, char** argv)
{
std::cout << "Base1 test: \n";
Base1 *base1 = new Derived1(5);
base1->print();
delete base1;
std::cout << "\n\nBase2 test: \n";
Base2 *base2 = new Derived2(5);
base2->print();
delete base2;
return 0;
}
//输出结果:
Base1 test:
Derived1 print
Base1's destructor
Base2 test:
Derived2 print
Derived2's destructor
Base2's destructor
base1实际指向Derived1对象,在Derived中通过new在堆上创建了5个char,但是当执行 delete base1;的时候,只调用了 Base1::~Base1(),但却没有调用 Derived1::~Derived1(),最终导致这5个char无法释放,而导致内存泄漏。
当把Base2的析构函数声明为虚函数的时候,调用 delete base2,会先调用 Derived2::~Derived2(),然后再调用 Base2::~Base2(),所有内存成功释放。
13.关键字"override"
override用于直接明了的告诉编译器该函数用于重载父类的某个虚函数
class Base {
public:
virtual void print(void){...}
};
class Derived1 : public Base {
public:
void print(void){...}
};
class Derived2 : public Base {
public:
void Print(void){...}
};
该代码中因为不小心,在 Derived2中将 print误输入为 Print,(注意其中的字母p的大小写),关键问题是 编译器完全可以正确的编译上面的代码 ,这是一个很难发现的错误。
问题来了: 如何简单直接的向编译器表明意图,我就是要重载 Base::print(void)呢?如果我写错了字母,你(指代编译器)要直接告诉我错误,或者一个警告也行?
答: override关键字可以做这件事情。
代码修改如下:
class Base {
public:
virtual void print(void){...}
};
class Derived1 : public Base {
public:
void print(void) override {...}
};
class Derived2 : public Base {
public:
void Print(void) override {...}
};
当编译器看到上面代码的时候就开始很不爽了,编译器开始抱怨了,你通过 "override" 告诉我 "Derived2::Print(void)是要重载父类的某个函数,可是我根本没有在父类中找到 "Print(void)"函数,编译器直接丢出个错误,然后甩膀子不干了。
14.atomic 为什么要定义一个原子类型?
原子类型是封装了一个值的类型,它的访问保证不会导致数据的竞争,并且可以用于在不同的线程之间同步内存访问。
举个例子,int64_t类型,在32位机器上为非原子操作。更新时该类型的值时,需要进行两步操作(高32位、低32位)。如果多线程操作该类型的变量,且在操作时未加锁,可能会出现读脏数据的情况。
解决该问题的话,加锁,或者提供一种定义原子类型的方法。
15.emplace_back
emplace_back函数的作用是减少对象拷贝和构造次数,是C++11中的新特性,主要适用于对临时对象的赋值。
在使用push_back函数往容器中增加新元素时,必须要有一个该对象的实例才行,而emplace_back可以不用,它可以直接传入对象的构造函数参数直接进行构造,减少一次拷贝和赋值操作。
16.lock_guard
lock_guard是一种在作用域内控制可锁对象所有权的类型。
从lock_guard<>可以看出它是一个模板类,它在自身作用域(生命周期)中具有构造时加锁,析构时解锁的功能。
lock_guard具有两种构造方法:
lock_guard(mutex& m)
lock_guard(mutex& m, adopt_lock)
其中mutex& m是互斥量,参数adopt_lock表示假定调用线程已经获得互斥体所有权并对其进行管理了。
#include <iostream>
#include <mutex>
#include <vector>
#include <string>
#include <ctime>
#include <thread>
using namespace std;
// 时间模拟消息
string mock_msg()
{
char buff[30] = { 0 };
static int i = 100000;
sprintf_s(buff, "%d", i--);
return buff;
}
class CMutexTest
{
public:
void recv_msg(); //接收消息
void read_msg(); //处理消息
private:
vector<string> msg_queue; //消息队列
mutex m_mutex; //互斥量
};
// 模拟接收消息
void CMutexTest::recv_msg()
{
while (true)
{
string msg = mock_msg();
cout << "recv the msg " << msg << endl;
// 使用"{ }"限定lock_guard作用域
{
lock_guard<mutex> mylockguard(m_mutex);
// 消息添加到队列
msg_queue.push_back(msg);
}
this_thread::sleep_for(chrono::milliseconds(10));//方便观察数据
}
}
// 模拟读取处理
void CMutexTest::read_msg()
{
while (true)
{
// 已经加锁
m_mutex.lock();
// 传递所有权给lock_guard,并传入adopt_lock表示已获得所有权
lock_guard<mutex> mylockguard(m_mutex, adopt_lock);
if (!msg_queue.empty())
{
// 处理消息并移除
string msg = msg_queue.front();
cout << "read the msg " << msg << endl;
msg_queue.erase(msg_queue.begin());
}
this_thread::sleep_for(chrono::milliseconds(15));//方便观察数据
}
}
int main()
{
CMutexTest my_test;
thread recv_thread(&CMutexTest::recv_msg, &my_test); //接收线程
thread read_thread(&CMutexTest::read_msg, &my_test); //处理线程
recv_thread.join();
read_thread.join();
}
17.multiple definition of xxxx问题解决及其原理
有时候明明使用了条件编译#ifndef和#pragmaonce,还是提示重复定义。。。
17.1 在头文件内定义变量
在一个.h文件中定义了一个变量,而这个.h文件被多个文件包含 ,单独编译都没有问题,但是到链接的时候就出现问题了。一般在.h文件中定义一个变量声明时,在其他文件中只要包含了这个.h文件,编译的时候就会独立被编译器解释,然后每个.C文件会生成独立的标识符和符号表,所以上述代码在单独编译的时候并不会报错,语法是合法的。但是,最后在编译器链接的时候,就会将工程中所有的符号整合在一起,由于文件中有重复的变量,于是就会出现重复定义的错误,系统就是提示你“multiple definition of xxx”。
详解:https://blog.csdn.net/mantis_1984/article/details/53571758
17.2 在头文件内实现函数
如果头文件中有函数的定义,那么不同cpp文件都包含这个头文件,在汇编成.o文件后,不同的.o文件中都含有头文件中函数的定义,链接阶段就会出现重定义的问题。
如果出现这种错误,找到提示信息中函数所在的头文件,在头文件中保留函数的声明,把函数的实现都删掉,放在一个单独的cpp文件中。
17.3 函数的多重定义
为图方便在.h里直接定义的函数,这种直接在函数声明前+“inline”关键词。如 inline void GetParsingData();
18.虚函数编译提示undefined reference to ‘vtable‘
虚函数需要在父类中对其进行预定义,可以什么都不实现只加上{}号。也可在函数声明后面加上 = 0,使其变成纯虚函数。
19.数据类型与其大小简单一览表
19.1 int*_t类型
为了避免由于依赖“典型”大小和不同编译器设置带来的奇怪 行为, ISO C99 引人了一类数据类型 , 其数据大小是固定的 ,不随编译器和机器设置而变化。
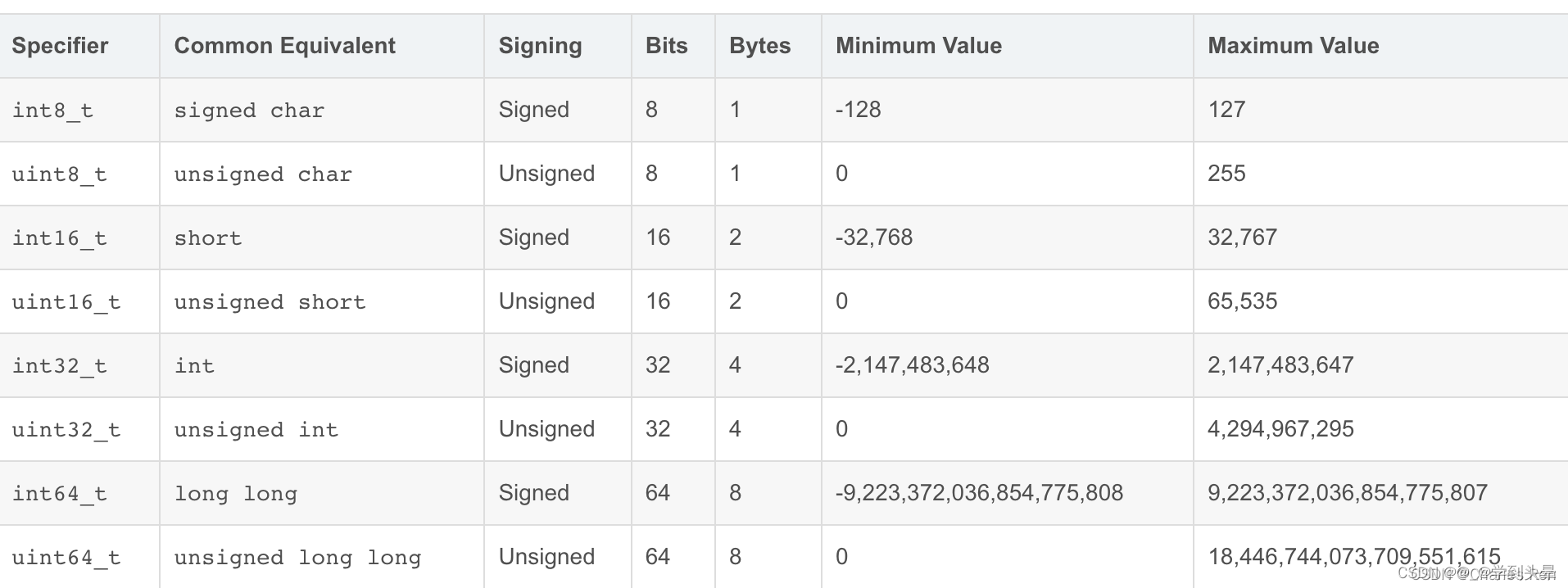
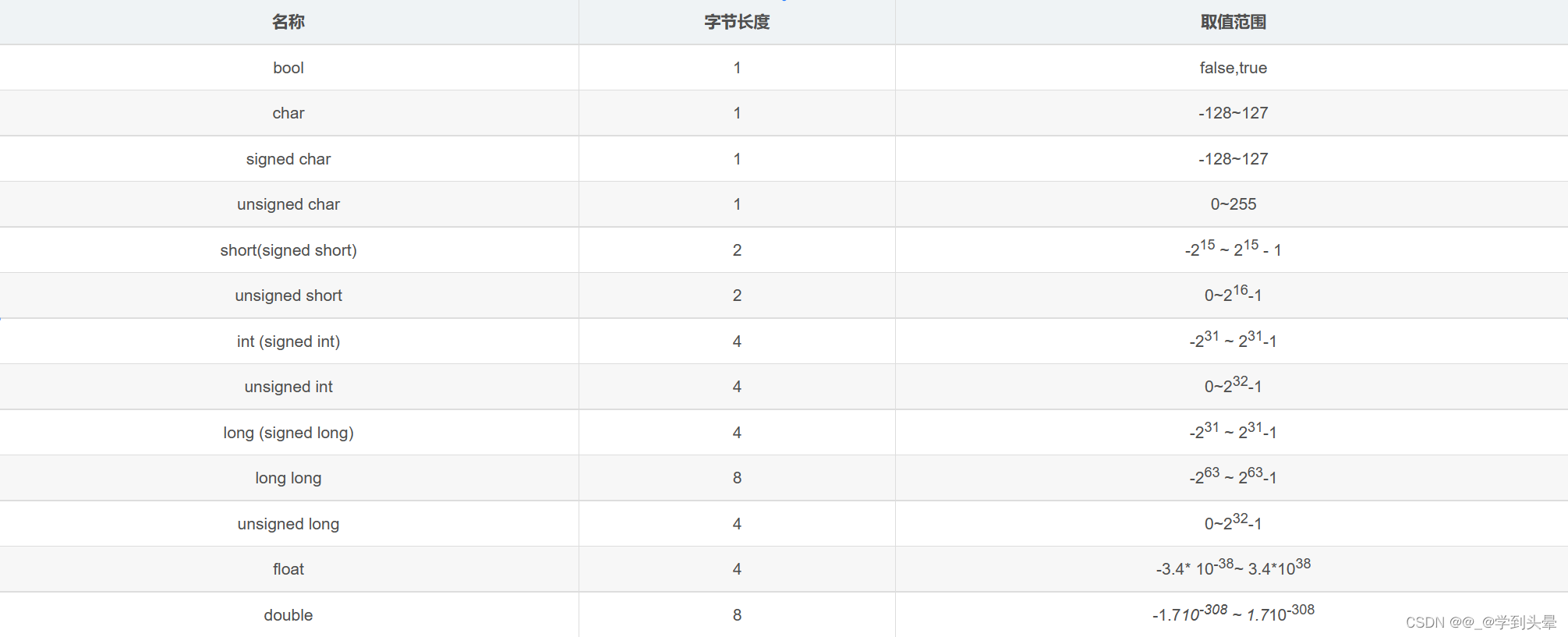
19.2 基本数据类型
20.编译报错undefind reference to ‘pthread_create’
Cmakelists.txt文件中添加链接库:
target_link_libraries(main pthread)
21.emplace_back与push_back
两者都用于将元素添加进容器中。
emplace_back函数的作用是减少对象拷贝和构造次数,是C++11中的新特性,主要适用于对临时对象的赋值。
在使用push_back函数往容器中增加新元素时,必须要有一个该对象的实例才行,而emplace_back可以不用,它可以直接传入对象的构造函数参数直接进行构造,减少一次拷贝和赋值操作。
22.double类型隐式转换int
double型可以强制转换成int型,即使不加强制转换,也会隐式转换,只是转换结果会丢弃小数部分,如:
double d=1.6;
int i;
i=d ; //隐式转换,i结果为1
i=(int)d ; //强制转换,i结果为1
但,如果double变量数据,超过整形数据的表示范围,(一般整数占四个字节,有符号数表示范围为:-2^31 ~ 2^31-1 ),则转换后的结果会是错误的。
向上转换一般不会有太大问题,如int转long;但向下转换则很可能会导致数据丢失,应尽量避免。
23.std::system_error
在退出线程的时候,C++抛出异常,程序中止:
terminate called after throwing an instance of ‘std::system_error’
what(): Invalid argument
异常抛出代码如下:
void CanReader::Stop()
{
if (IsRunning())
{
is_running_.exchange(false);
// 关闭线程
}
else
{
cout << "Can Reader 不在运行中" << endl;
}
cout << "Can Reader 已关闭" << endl;
};
问题原因:
这个问题主要是我对于join和detach的不理解导致的。在上述函数中,is_running_.exchange(false)让子线程死循环中止,但由于我已经在线程开始之后(程序其他位置)调用了detach,子程序退出后导致std::thread对象失去了与之相关联的线程对象,所以现在的std::thread对象已经不可join,导致了程序发生了中断。
因此要么直接删掉join操作,要么在线程退出时添加判断作为常规操作是必要的:
void CanReader::Stop()
{
if (IsRunning())
{
is_running_.exchange(false);
// 关闭线程
if (read_thread_.joinable())
{
read_thread_.join();
}
}
else
{
cout << "Can Reader 不在运行中" << endl;
}
cout << "Can Reader 已关闭" << endl;
};
joinable()函数是一个布尔类型的函数,他会返回一个布尔值来表示当前的线程是否是可执行线程(能被join或者detach),因为相同的线程不能join两次,也不能join完再detach,同理也不能detach,所以joinable函数就是用来判断当前这个线程是否可以joinable的。通常不能被joinable有以下几种情况:
1)由thread的缺省构造函数而造成的(thread()没有参数)。
2)该thread被move过(包括move构造和move赋值)。
3)该线程被join或者detach过。
24.python调用dll函数,参数报错,提示类型未知
报错如下:
ctypes.ArgumentError: argument 2: <class ‘TypeError’>: Don’t know how to convert parameter 2
原因是ctypes模块在连接python和c/c++时数据类型存在一个映射关系。python并不会直接读取到dll的源文件,在使用dll的函数前我们需要对传入的参数进行一个声明,告诉python函数需要声明类型的参数。
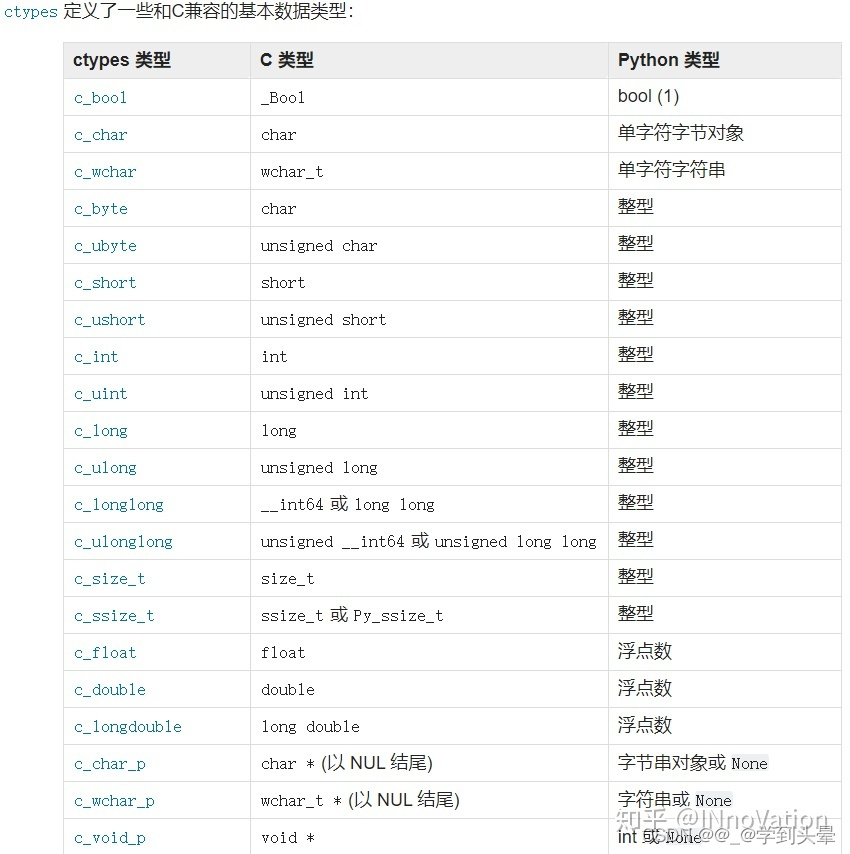
使用如下:
# -*- coding: utf-8 -*-
from ctypes import *
# 字符,仅接受one character bytes, bytearray or integer
char_type = c_char(b"a")
# 字节
byte_type = c_char(1)
# 字符串
string_type = c_wchar_p("abc")
# 整型
int_type = c_int(2)
# 直接打印输出的是对象信息,获取值需要使用value方法
print(char_type, byte_type, int_type)
print(char_type.value, byte_type.value, string_type.value, int_type.value)
输出:
c_char(b’a’) c_char(b’\x01’) c_int(2)
b’a’ b’\x01’ abc 2
24.2 数组类型
数组的创建与上面类似,给定数据类型和长度即可,如下:
# 数组
# 定义类型
char_array = c_char * 3
# 初始化
char_array_obj = char_array(b"a", b"b", 2)
# 打印只能打印数组对象的信息
print(char_array_obj)
# 打印值通过value方法
print(char_array_obj.value)
输出:
< main .c_char_Array_3 object at 0x7f2252e6dc20>
b’ab\x02’
24.3 函数的进出参数提前定义
也可以在调用c方法前可以指定传入参数的类型和返回参数的类型。
- argtypes
fuction.argtypes = [c_char_p,c_int]
这样,在后面你使用fuction时python会自动处理你的参数,从而达到像调用python参数一样。
- restype
和上面一个一样,python不仅看不到函数要什么,也看不到函数返回什么。默认情况下,python认为函数返回了一个C中的int类型。然而如果我们的函数返回别的类型,就需要用到restype命令。
function.restype = c_char_p
指定了fuction这个函数的返回值是c_char_p的,从而让python在处理时按照我们希望的那样处理。
我们甚至可以设置函数的返回值为一个python对象(比如函数),目标函数执行后返回int并用该int直接调用该python对象。
25.编译后运行时出现的问题:无法定位程序输入点__gxx_personality_v0
写好的程序可以编译,一点问题也没有,但是就是没法运行,会弹出无法定位程序输入点__gxx_personality_v0的错误。
解决办法:复制 libstdc++-6.dll文件(在mingw64/bin目录下)到 C:\Windows\System32或者 C:\Windows\SysWOW64中,重新编译程序运行。
26.Python x64下ctypes动态链接库出现access violation
Traceback (most recent call last):
File “test.py”, line 28, in<module>
lib.CanReader_Init(can_reader,can_client,hg_message)
OSError: exception: access violation reading 0x000000006B1B2359
提示访问非法内存地址!但是地址是由API直接返回的怎么会出错呢?并且在使用32位python情况下没有出现该问题。
32位python转用64位python出现此错误情况,因此可以大致确定是兼容性问题,代码如下:
from ctypes import *
if __name__ == '__main__':
lib = WinDLL('./libCan_drive.dll', winmode=0)
## 生成对象 ##
can_client = lib.CanClient_new()
## 初始化 ##
# 出现错误的位置:
if (lib.CanClient_SetBaudrate(can_client, 10)):
lib.CanClient_Init(can_client, 4, 0, 0)
判断可能是调用API获取对象指针出现了 数据转换问题导致指针地址发生改变或者 对象指针传入API后被转换发生改变。由于两个API我都没有声明参数与返回类型(32位情况下没声明运行正常),通过24.所说对传入参数与返回类型进行提前声明(python下默认的返回值类型都是int),因为64位下内存地址为64位无符号型整数,因此设置为 ctypes.c_uint64,代码如下,成功运行:
from ctypes import *
def DllFuncInit():
lib.CanClient_SetBaudrate.argtypes = [c_uint64, c_int] # 声明传入参数类型
lib.CanClient_new.restype = c_uint64 # 声明返回类型
if __name__ == '__main__':
lib = WinDLL('./libCan_drive.dll', winmode=0)
DllFuncInit()
## 生成对象 ##
can_client = lib.CanClient_new()
## 初始化 ##
if (lib.CanClient_SetBaudrate(can_client, 10)):
lib.CanClient_Init(can_client, 4, 0, 0)
更新:ctypes.c_uint64可以改成ctypes.c_void_p,自动兼容64位和32位。















 3975
3975











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









