







3. 贝叶斯和朴素贝叶斯
贝叶斯和朴素贝叶斯的区别
朴素贝叶斯的假设前提有两个:
- 各特征彼此独立
- 各特征对被解释变量的影响一致,不能进行变量筛选
但是很多情况无法达到这个条件,比如:解决文本分类问题,相邻词关系,近义词关系等等。
彼此不独立的特征之间的关系,没办法通过朴素贝叶分类器训练得到,同时这种不独立性也给问题的解决方案引入了更多的复杂性。
此时,更具普遍意义的贝叶斯网络在特征彼此不独立的情况下,可进行建模。但是,贝叶斯网络并不放宽第二个假设,故不能对变量进行筛选,因为需要各特征对被解释变量的影响一致。
贝叶斯分类方法,是一种展现已知数据集属性分布的方法,其最终计算结果完全依赖于训练样本中类别和特征分布。与SVM等分类方法不同,它只是对事实进行展现。
| 类型 | 贝叶斯网络 | 朴素贝叶斯 |
|---|---|---|
| 假设前提 | 各变量都是离散型的 各特征都有依赖(不确定的因果推理)关系(变量无关) 每一个节点在其直接前驱节点的值制定后,这个节点条件独立于其所有非直接前驱前辈节点 P ( v ∣ p a r ( v ) , x 1 , x 2 , ⋯ , x n ) = P ( v ∣ p a r ( v ) ) P(v|par(v), x_1, x_2, \cdots, x_n) = P(v|par(v)) P(v∣par(v),x1,x2,⋯,xn)=P(v∣par(v)) 贝叶斯网络放宽了每个变量独立的假设 | 个特征彼此独立 朴素贝叶斯对于若干条件概率值不存在的问题,一般通过将所有概率值加一来解决 且对被解释变量的影响一致,不能进行变量筛选 |
| 应用案例 | 在信息不完备的情况下,通过可以观察随机变量推断不可观察的随机变量 解决文本分类问题时,相邻词的关系、近义词的关系 | 分类 |
| 缺点 | 不能对变量进行筛选,因为不能放宽对被解释变量影响一致的假设 | 彼此不独立的特征之间建立朴素贝叶斯,反而加大了模型复杂性 |
| 优点 | 贝叶斯原理和图论相结合,建立起一种基于概率推理的数学模型,对于解决复杂的不确定性和关联性问题,有很强的优势 * 对缺失数据不敏感 * 可以学习因果关系,加深对数据的理解 * 能将先验知识融入建模 * 避免了过度拟合问题,不需要保留数据进行检验 | * 算法逻辑简单,易于实现 * 分类过程中,时空开销小 |
贝叶斯网络的概念
贝叶斯网络基本概念有两个:
- 引入了一个有向无环图(Directed Acyclic Graph)
- 一个条件概率表集合(不独立)
DAG: DAG的节点 V V V包括随机变量(类别和特征),有向连接 E ( A — > B ) E(A—>B) E(A—>B)表示结点 A A A是结点 B B B的parent,且 B B B与 A A A是有依赖关系的(不独立)
条件概率表集合: 同时引入了一个条件性独立概念:即图中任意结点 v v v在给定 v v v的parent结点的情况下,与图中其他结点都是独立的,也就是说 P ( v ∣ p a r ( v ) , x 1 , x 2 , ⋯ , x n ) = P ( v ∣ p a r ( v ) ) P(v|par(v), x_1, x_2, \cdots, x_n) = P(v|par(v)) P(v∣par(v),x1,x2,⋯,xn)=P(v∣par(v))。这里的 p a r ( v ) par(v) par(v)表示v的parent结点集, x 1 , x 2 , ⋯ , x n x_1, x_2, \cdots, x_n x1,x2,⋯,xn表示图中其他结点。
如果已知所有联合概率值,那么任何形式的概率问题都可以迎刃而解。而现实是当特征集合过大(>10)时,几乎无法通过统计得到。而特征集合的大小在一定程度上,与最终的分类效果是一个正反馈关系。
所以这种问题的解决就是:通过条件独立的概念,来对各条件概率值进行优化。 bayesian net的tutorial对该问题进行了阐述。
贝叶斯网络中连线是如何产生的?
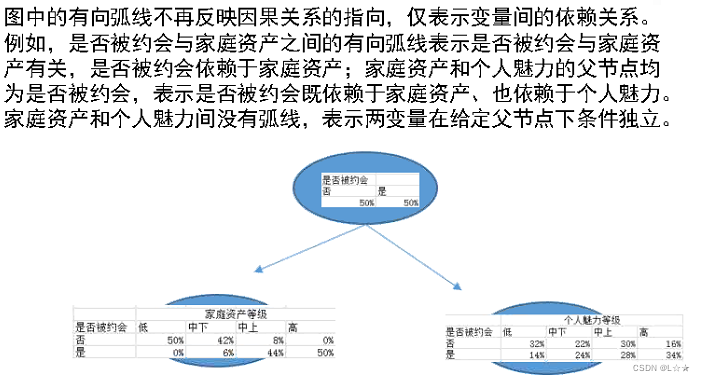
贝叶斯网络,不再表示因果关系,而是变量之间的相关依赖关系。
x , y x, y x,y之间线代表的就是条件概率, p ( y ︱ x 1 ) ︱ x 2 , x 3 , ⋯ , x n ) = p ( y ) p(y︱x_1)︱x_2, x_3, \cdots, x_n) =p(y) p(y︱x1)︱x2,x3,⋯,xn)=p(y),
- 等于则不连线
- 不等于,说明在控制了 x 2 x_2 x2下,两者不是独立,而是相关的,则会连线。
朴素贝叶斯的概念
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。
朴素贝叶斯分类的数学原理
朴素贝叶斯分类算法的核心算法: 贝叶斯公式
P ( B ∣ A ) = P ( A ∣ B ) P ( B ) P ( A ) P(B|A)=\frac{P(A|B)P(B)}{P(A)} P(B∣A)=P(A)P(A∣B)P(B)
其中,
A A A——特征
B B B——类别
即:
P ( 类 别 ∣ 特 征 ) = P ( 特 征 ∣ 类 型 ) P ( 类 型 ) P ( 特 征 ) P(类别|特征)=\frac{P(特征|类型)P(类型)}{P(特征)} P(类别∣特征)=P(特征)P(特征∣类型)P(类型)
最终我们求得 P ( 类 别 ∣ 特 征 ) P(类别|特征) P(类别∣特征)即可。
朴素贝叶斯的优缺点
优点:
- 算法逻辑简单,易于实现
- 分类过程中,时空开销小
缺点:
理论上,朴素贝叶斯模型与其他分类方法相比,具有最小的误差率。
但是实际上并非总是如此。这是因为朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多(>10),或者属性之间相关性比较大时,分类效果不好。
而在属性相关性比较小时,朴素贝叶斯分类性能最为良好。对于这一点,有半朴素贝叶斯之类的算法,通过考虑部分关联性适度改进。
















 806
806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











