







论文:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks(NIPS 2015)
代码:chenyuntc/simple-faster-rcnn-pytorch
Jupyter 代码梳理笔记:Faster RCNN
模型架构

- Dataset:提供图片、图片目标的类别和位置标签。
- Extractor: 用VGG16提取图片特征feature map(其它如:残差网络等都可以)
- RPN(Region Proposal Network):负责提供候选区域rois(一般还会把标签框也加进去,标签框也是很好的正样本),代替selective search方法,突破产生候选框带来的计算瓶颈
- RoIHead: 对rois分类和微调。判断它是否包含目标,并修正框的位置和座标

Faster RCNN把步骤都整合到一个模型中

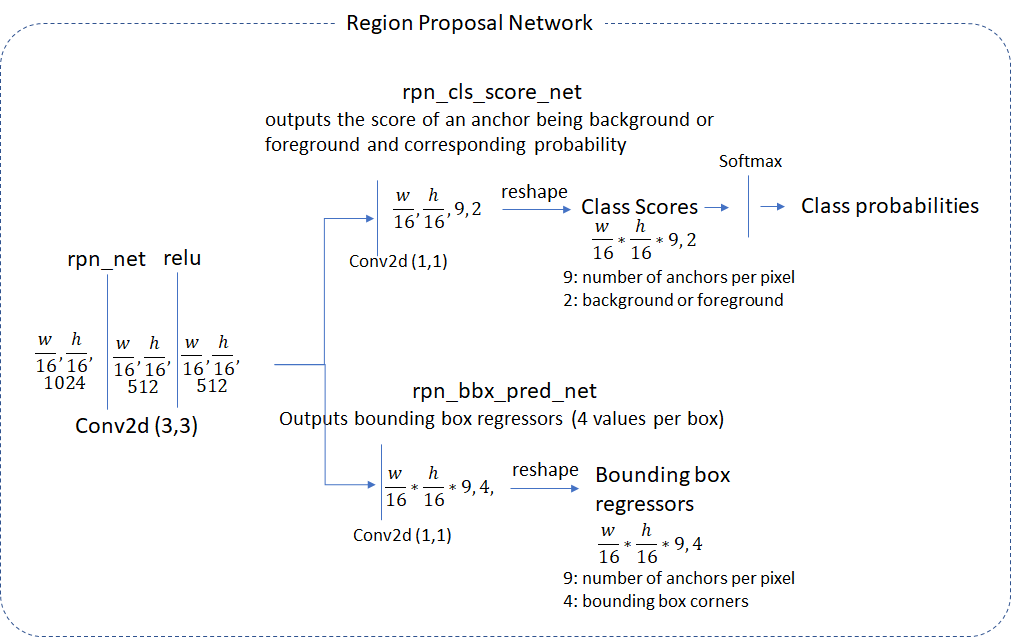
RPN
RPN的任务是预测有没有目标、在哪(不需要知道具体类别),然后将预测的区域(rois)给ROIHEAD训练,当然RPN还需要训练自身
RPN的3*3卷积层使提取出来的feature更鲁棒?
RPN需要进行分类和回归位置,训练自身
为什么不直接回归坐标差,而编码成变换系数进行学习?
【
18
】
^{【18】}
【18】
t
x
=
(
x
−
x
a
)
/
w
a
t
y
=
(
y
−
y
a
)
/
h
a
t
w
=
log
(
w
/
w
a
)
t
h
=
log
(
h
/
h
a
)
\begin{matrix} &t_{x} = (x - x_{a})/w_{a} &t_{y} = (y - y_{a})/h_{a}\\ &t_{w} = \log(w/ w_a) &t_{h} = \log(h/ h_a) \end{matrix}
tx=(x−xa)/watw=log(w/wa)ty=(y−ya)/hath=log(h/ha)
1)
log
/
exp
\log/\exp
log/exp变换防止出现负数,网络学习的是 proposal box 和 gt box 的变换系数
2)直接学习真实坐标,loss并不能很好地反映预测准确性,因为大目标即使预测得很准也可能比预测较差的小目标loss大得多,因此直接预测真实坐标所产生的loss并不能很好地反映预测框的好坏(yolo v1对w, h取了平方根,可以有效缓解这个问题,但是并不能解决这个问题)
给anchor分配标签和位置
a)与ground-truth-box IoU最大的anchor标记为正标签1
b)与ground-truth-box IoU大于0.7的anchor标记为正标签1
c)与ground-truth-box IoU小于0.3的anchor标记为负标签0
d)其余anchor既不是正样本的也不是负样本,对训练没有帮助-1
注意:单个ground-truth对象可以为多个anchor分配正标签
通过如下方式对anchor boxes分配标签和位置:
1、找到有效的anchor boxes的索引,并且生成索引数组,生成标签数组其形状索引数组填充-1
2、检查是否满足以上a、b、c条件中的一条,并相应填写标签。如果是正anchor box(标签为1),注意哪个ground-truth目标可以得到这个结果。
3、计算与anchor box相关的ground-truth的位置(loc)。
4、通过为所有无效的anchor box填充-1和为所有有效Anchor计算具体值,重新组织所有anchor box。
5、输出(N, 1)标签和(N, 4)的locs。
6、找到所有有效anchor boxes的索引
7、从正标签和负标签中分别随机取样,以获得较为理想的正负样本比例(1:1)进行训练,其余的则忽略,若某张图片中正样本的数量太少,用负样本填充mini-batch(256),用于RPN的训练
RoIHead
ROIHEAD的任务:什么类别的目标,在什么地方

- 正样本取RoIs和gt_bboxes IoU大于0.5的(随机取32个,不够用负样本补上),gt_bboxes 本身也是很好地正样本
- 负样本取RoIs和gt_bboxes的IoU小于等于0(或者0.1)的(随机取96个)
流程
训练Faster RCNN大致流程梳理
1、构建特征提取网络(VGG16去掉后面分类层),从图像中提取特征图
2、根据特征图生成Anchor(三种尺度
×
\times
×三种形状)
3、Anchor根据标签框筛选、转换得到RPN网络的训练标签(256个,正负样本比例 1:1)
4、构建RPN网络得到预测框位置和正负样本得分
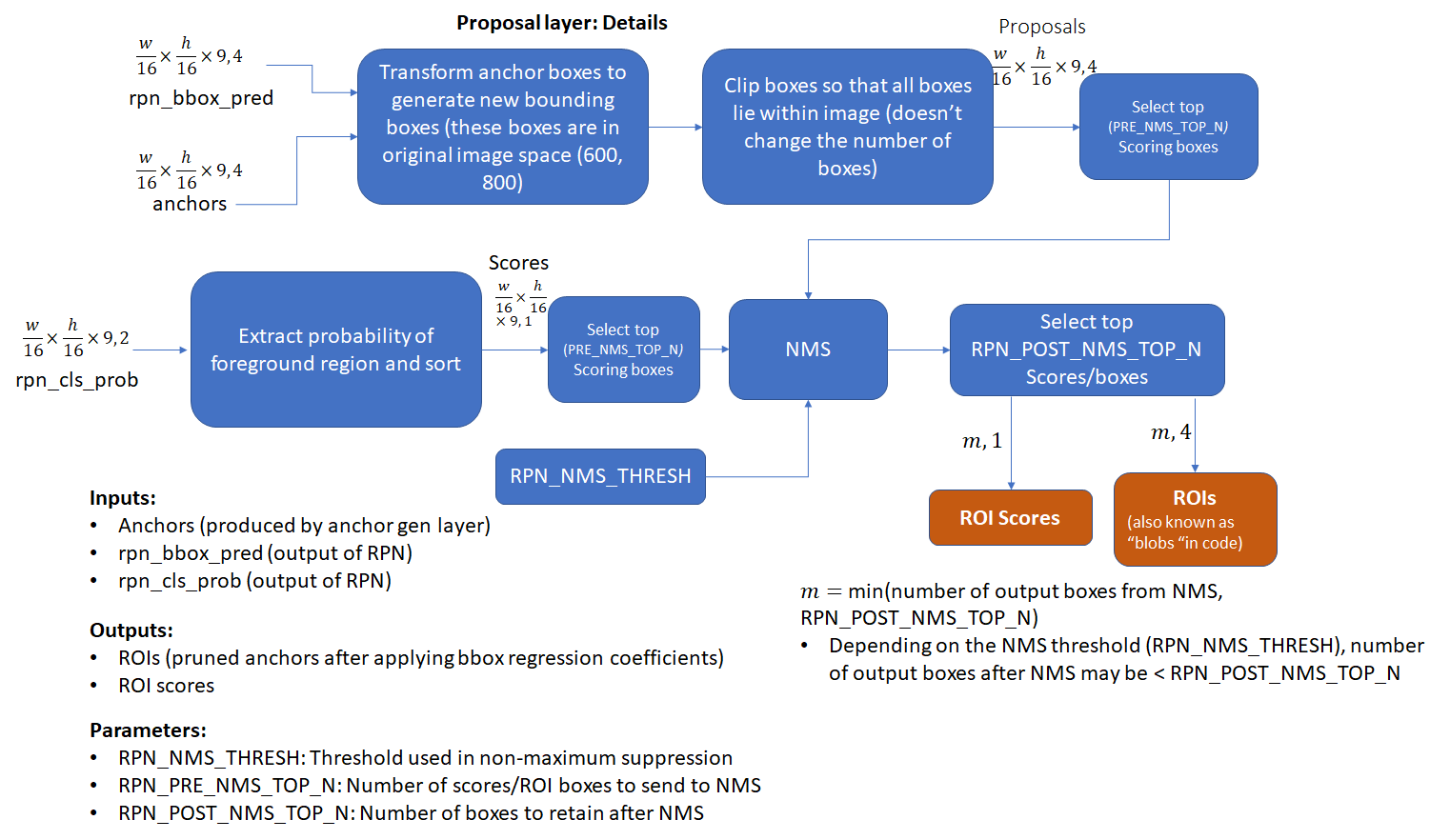
5、取前N(训练:12000)预测框,经过NMS得到大约2000个建议框
6、从proposals中挑选出n(128,正负样本比例:1:3)个rois(感兴趣区域),分配类别和位置 ,得到rois标签
7、在特征图谱截取得到rois对应的特征图谱,并输入到RoI Pooling中(
7
×
7
7\times7
7×7),得到相同大小的特征图
8、构建Fast RCNN网络(分类和回归部分),并输入7中得到的特征图,得到预测的分类得分和目标框
9、根据3中的RPN标签和4的RPN预测计算rpn_cls_loss和rpn_reg_loss
10、根据6中的rois标签和8中的最终预测计算roi_cls_loss和roi_reg_loss
11、根据9、10计算得到总损失
注意: RPN和ROIHEAD任务不一样,所以RPN标签 和 rois标签 是不一样的
训练流程代码梳理笔记:Faster RCNN.ipynb(Google Colab)
补充

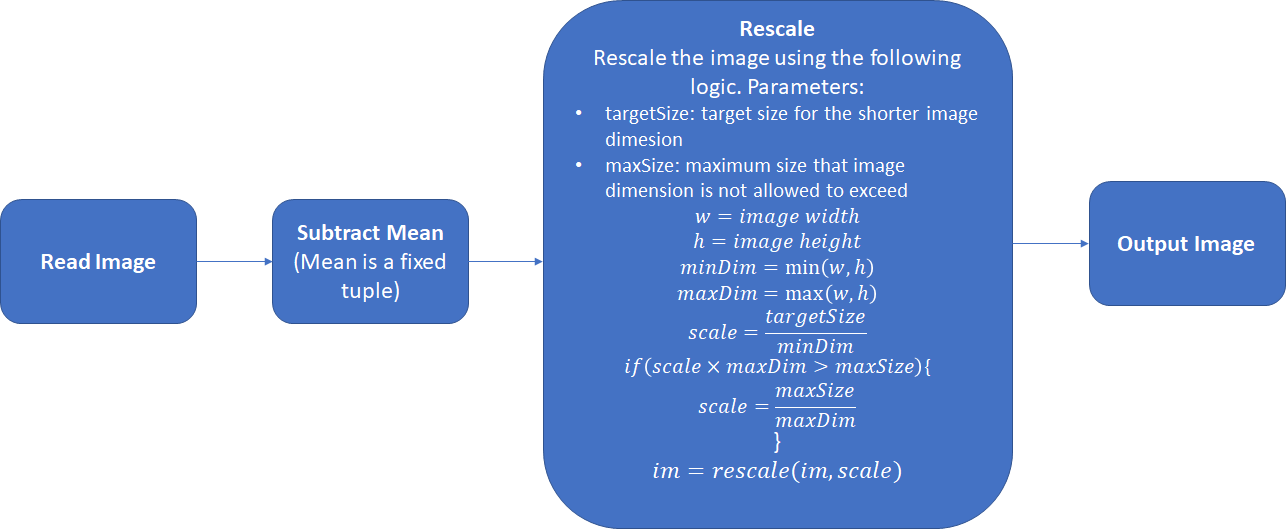
-
使用Imagenet数据集的均值:image_mean=[0.485,0.456,0.406]和标准差:image_std=[0.229,0.224,0.225]进行归一化,如果要在自己的数据集上从头开始训练,则可以计算新的均值和标准差
-
在inference的时候,为了提高处理速度,12000和2000分别变为6000和300.
-
在RPN的时候,已经对anchor做了一遍NMS,在RCNN测试的时候,还要再做一遍;在RPN的时候,已经对anchor的位置做了回归调整,在RCNN阶段还要对RoI再做一遍;在RPN阶段分类是二分类,而Fast RCNN阶段是21分类
-
Anchor超出图片边界要进行裁剪
-
rpn的正负样本256个只在计算loss时使用,不会传入到rcnn阶段,传入到rcnn阶段的是rpn产生的2000个proposal
-
每个proposal都和一个anchor对应,所以anchor和proposal的数量是一样的
-
只有标签是1或0的anchor才会参与分类的损失传递和梯度更新,anchor一共有3种标签:-1、0、1,分别表示无效、背景、目标,只有标签是1的anchor才会参与坐标回归的损失传递和梯度更新
-
虽然ROI Pooling可以输入任意大小的图片,但实际训练时一般还是要进行resizing,因为不同大小的图片难以作为一个batch进行训练
参考文献
【1】Faster R-CNN:利用区域提案网络实现实时目标检测 论文翻译
【2】Faster-RCNN算法精读
【3】RPN网络通俗理解
【4】RPN (区域候选网络)
【4】Faster R-CNN学习笔记
【5】Faster R-CNN 源码解析(Tensorflow版)
【6】faster-RCNN的关键点(区域推荐网络RPN)
【7】Faster R-CNN的训练过程的理解
【8】Tensorflow 版本 Faster RCNN 代码解读(含流程图)
【9】一文读懂Faster RCNN
【10】Faster RCNN代码详解
【11】Guide to build Faster RCNN in PyTorch
【12】Object Detection and Classification using R-CNNs
【13】从编程实现角度学习Faster R-CNN(附极简实现)
【14】一文教你如何用PyTorch构建 Faster RCNN
【15】Faster RCNN简介与代码注释(附github代码—已跑通)
【16】RCNN, Fast R-CNN 与 Faster RCNN理解及改进方法
【17】从编程实现角度学习 Faster R-CNN(附极简实现)
【18】One Stage目标检测算法可以直接回归目标的坐标是什么原理?
【19】PyTorch-faster-rcnn之一源码解读三model
【20】Precise RoI Pooling(PrRoI Pooling)笔记
【21】RoI Pooling与RoIWrap Pooling与RoIAlign Pooling与Precise RoI Pooling















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









