









week 4
1 Movie rating data
1.1 Data precossing

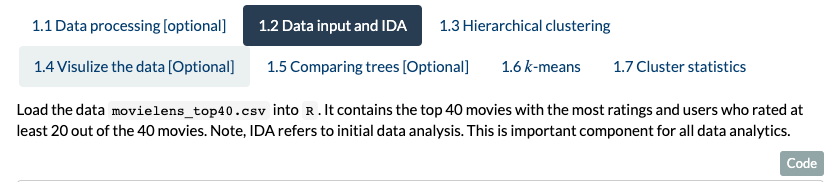
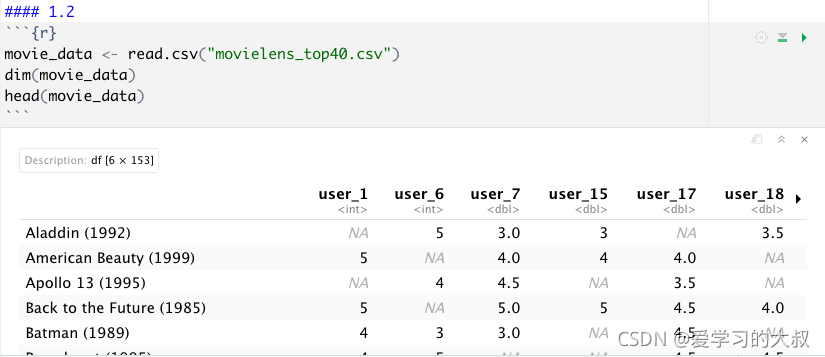
1.2 Data input and IDA
1.3 Hierarchical clustering
hclust(): Hierarchical 聚类,method分3种:complete,single,average



cutree(): 将tree型结构进行剪枝,k是按组的个数剪枝,h是按tree的高度剪枝。
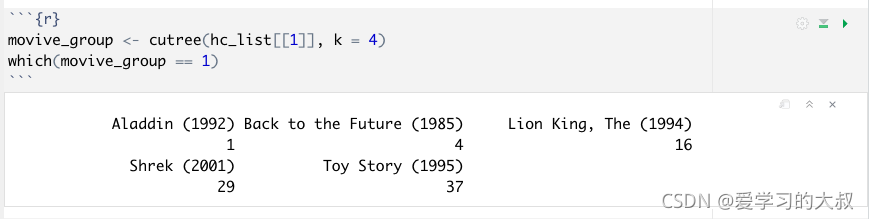

which如何赋值:
注意which赋值前,应该用as.matrix转换成matrix,再赋值

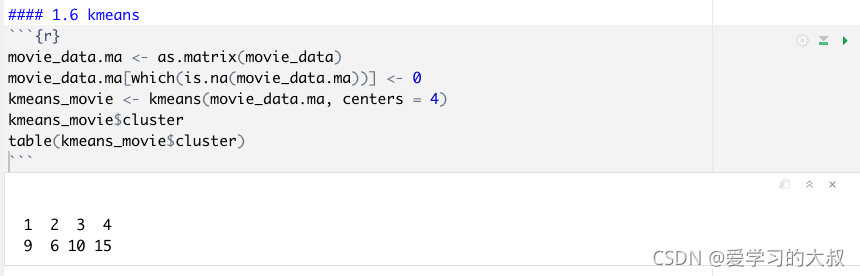
1.6 Kmeans

table(): 建立不同因子的个数统计值。
kmeans(): Kmeans聚类方法,centre可以是k,也可以是中心点。

prcomp(): pca的方法,注意scale=T
关于画图:
要画图,注意先转成dataframe
label这里要用factor
col不能放在外面,只有放在里面才会按label分类

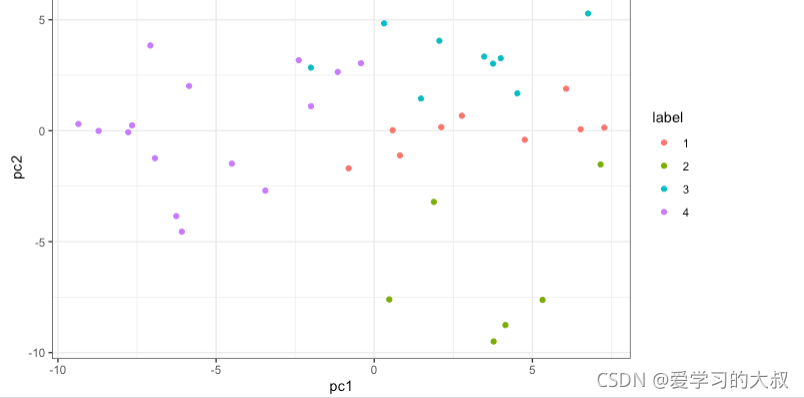
1.7 Cluster statistics

lapply和sapply的区别: sapply返回一个list,lapply返回一个2维list。
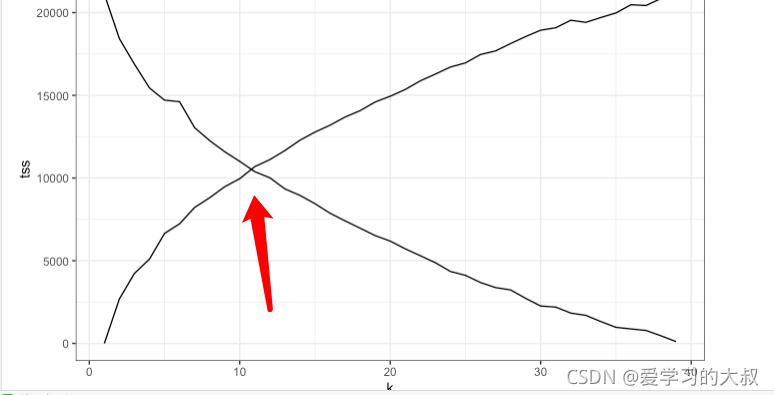
tot.withinss: 分组总和,sum(withinss)
betweenss: 组间的平方和,totss – tot.withinss
寻找他们两个的平衡点,应该是最好的k


2 Author by word count
2.1 Data Input

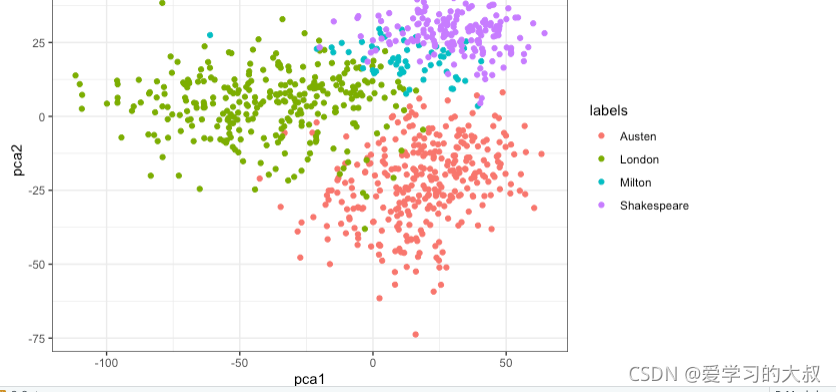
2.2 PCA

2.3 t-SNE

t-SNE t分布随机邻域嵌入是一种用于探索高维数据的非线性降维算法。
Rtsne: 注意里面的perplexity混乱程度,可以调,默认dims是2维。要取Y的值,才是取得pca。
要画图先转data frame
ggplot加标题是ggtitle。
一起画图是用的lapply函数

2.4 MDS

构建不同方法的distance

cmdscale(): 构建mds
这里主要要修改attr,方便之后的method绘图


2.5 Compare and contrast
















 1328
1328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









