







 本文探讨了Vision Transformer、Swin Transformer、Convolutional Vision Transformer以及Cross Attention Transformer的计算复杂度。在Vision Transformer中,计算复杂度主要由多头注意力机制决定;Swin Transformer通过窗口化注意力降低了复杂度;Convolutional Vision Transformer利用卷积降低计算量;而Cross Attention Transformer则结合了两种注意力机制,IPSA和CPSA,分别在patch内和通道间计算注意力,具有不同的复杂度特点。
本文探讨了Vision Transformer、Swin Transformer、Convolutional Vision Transformer以及Cross Attention Transformer的计算复杂度。在Vision Transformer中,计算复杂度主要由多头注意力机制决定;Swin Transformer通过窗口化注意力降低了复杂度;Convolutional Vision Transformer利用卷积降低计算量;而Cross Attention Transformer则结合了两种注意力机制,IPSA和CPSA,分别在patch内和通道间计算注意力,具有不同的复杂度特点。
文章目录
Vision transformer
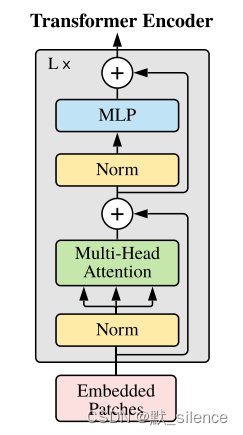
假设每个图像有 h ∗ w h*w h∗w 个patch,维度是 C C C
输入的图像 X X X ( 大小为 h w ∗ C hw* C hw∗C ),和三个系数矩阵相乘 ( 大小为 C ∗ C C*C C∗C ),得到 q k v qkv qkv 三个向量 ( h w ∗ C hw*C hw∗C ),复杂度为:
3 h w C 2 3hwC^2 3hwC2
q q q ( h w ∗ C hw*C hw∗C ) 和 k T k^T kT ( C ∗ h w C*hw C∗hw ) 相乘得到矩阵 A A A ( h w ∗ h w hw*hw hw∗hw ),复杂度为: ( h w ) 2 C (hw)^2C (hw)2C
A A A ( h w ∗ h w hw*hw hw∗hw ) 和 v v v ( h w ∗ C hw*C hw∗C )相乘,得到多头注意力的结果 ( h w ∗ C hw*C hw∗C ),复杂度为: ( h w ) 2 C (hw)^2C (hw)2C
经过MLP投影层 ( C ∗ C C*C C∗C ),得到 ( h w ∗ C hw*C hw∗C ),复杂度为:
h w C 2 hwC^2 hwC2
所以复杂度之和为: 4 h w C 2 + 2 ( h w ) 2 C 4hwC^2 + 2(hw)^2C 4hwC2+2(hw)2C</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2674
2674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









