







**
SVO半直接视觉里程计 学习与归纳
**
前段时间在一篇文章中看到了关于“单目视觉惯性vio算法的比较与分析”
在最后的结论中提到,svo的算法具有很高的计算效率,并且svo算法具有较强的可拓展性,如下图所示,svo+gstam可以达到仅次于vins 的测量精度,同时还能保持很高的计算速度。
可以考虑将svo算法与其他算法结合进一步提高精度,可用作组合导航的前端部分。
因此近期,对svo从结构算法到程序实现,进行了较为详细的学习,对于一些不是很懂的地方也做了标注


svo采用了基于直接法的跟踪方法,根据灰度不变假设,通最小化像素点的灰度值误差,以实现位姿与三维空间点的优化。区别于特征点法,svo虽然也提取了特征点,但不需要进行描述子的计算,这能节省很大一部分的计算量,在SVO的实现中,混合使用了特征点与直接法:它跟踪了一些关键点(FAST角点)使用直接法,根据这些关键点周围区块(4*4)的信息,估计相机运动以及关键点的位置 。由于svo仅需要对图像中的特征块进行追踪,不像传统直接法那样需要对图像中的所有像素点进行跟踪,因此svo的方法也被称为稀疏直接法,特征块提供运动跟踪所需要的梯度 减少了很多不必要的计算,一定程度上提高了算法效率。
1. svo算法框架
整个框架可以分为追踪和建图两大块
-上半部分主要完成对当前帧的位姿估计:
- 对比当前帧与上一帧,获取粗略的位姿估计
- 根据粗略的位姿,将当前帧与地图进行比对,求得精确的位姿并对可观测到的地图点进行优化。
-下半部分为建图部分:
- 主要是对特征点的深度进行估计;
- “深度滤波器”:利用新来的帧信息去更新特征点的深度分布。当某点的深度收敛时,将其作为新的地图点,加入地图,用于追踪环节。

2. motion estimation thread
运动估计线程通过三个步骤,实现对位姿的精确估计以及地图点的优化:
■1 通过当前帧与上一帧的共视关系:最小化 重投影的光度误差 来优化位姿变量
■2 结合当前帧与地图中的共视点:追溯到特征点在最近一个关键帧中的像素值,经过仿射变换,最小化特征点光度误差优化像素位置
■3 Pose and Structure Refinement:利用优化后的特征点位置与预测值的位置差,反过来进一步优化相机位姿和特征点的三维空间坐标(x,y,z)


通过最小化相邻帧之间特征块的重投影光度误差,可以实现对相机位姿的初步估计,但由于初始位姿(以上一时刻的位姿作为初值)以及特征点深度都是不确定度很高的值,仅可以实现对位姿的粗略估计
- 在下一步骤,可通过建立好的地图来进一步约束当前帧的位置
在当前帧Ik中,可以观察到p1-p4地图点,如果在之前的关键帧Ir2、Ir1中也能看到同样的地图点,则关键帧与当前帧之间即存在共视关系。
对每个共视的地图点,选择与当前帧夹角最小的关键帧作为参考帧。



由于是当前帧与关键帧的特征块进行对比,并且3d点所在的关键帧可能与当前帧距离较远,因此需要对KF帧中的特征块进行旋转拉伸的仿射变(Affine Warp)之后才能和当前帧的特征块进行对比。当上式收敛后,即完成当前帧与关键帧上的共视点的特征匹配,优化的变量为当前帧下的特征点的像素坐标。

匹配完成后,得到当前帧上所有优化后的新的特征点 u’ ,这些点分别储存了各自的信息:包含像素坐标、图像层数,并指向对应的共视地图点
- 在第三步中,利用上一步得到的更加精确的特征点位置u’反过来进一步优化相机位姿和特征点的三维空间坐标
这一步骤包含了两个部分:
motion-only Bundle Adjustment
structure-only Bundle Adjustment
两个变量的优化分开进行,构造的误差函数相同,仅优化变量不同




3. mapping thread
通过上半部分的motion estimation thread,我们可以得到相机运动的姿态估计,以及三维空间地图点的世界坐标,但是由于单目相机的尺度不确定性,要想恢复地图点在真实场景中的位置,需要对有效深度进行测量
建图线程主要工作是计算地图点的深度,由深度滤波器depth-filter完成,将所有具有深度的地图点信息结合拼在一起就构成了环境的三维地图
depth-filter工作方式:
1.提取关键帧上的特征点,每个特征点都对应一个不确定度很高的深度估计初值
2.对后续进来的普通帧,利用可观测的共视点信息,更新种子点的深度概率分布
3.若种子点的深度分布已收敛,放入地图,供追踪线程使用
3.1初始化种子点
——用以建图的点都是来自于关键帧上的特征点
svo仅在这一步用到了特征提取的方法:对关键帧上的点进行特征提取,提取fast角点,并用shi-Tomasi的角点计算方法求值,保留超过阈值的点作为挑选出来的特征点。
——将所有新选的特征点作为深度待估计的种子点seed
对seed点进行初始化,用高斯分布表示逆深度,深度范围取当前帧最小深度的倒数,高斯分布的标准差取1/6*depth_min,初值取当前帧的平均深度
3.2极线搜索寻找seed的匹配点
——初始化的seed深度具有极大地不确定性,随着后续不断添加进入新的普通帧,新的普通帧中同样可以观测到部分seed点,对于关键帧中深度还不确定的seed点,通过当前帧与关键帧之间的位姿变换,将seed点深度射线上最短min到最长max范围的深度 映射到当前帧的单位深度平面上,从而得到单位平面上的极线线段(???这里不太明白单位平面的具体作用)
——在极线上搜索当前帧中与关键帧seed的最佳匹配点,使二者最相似(即 特征块的光度差最小),进行匹配时,同样要对seed所在的特征块进行仿射变换后,再与当前帧下的图块进行对比。
——在极线上确定了最佳匹配的图块后,将这两个匹配点通过三角测量计算seed的深度值
3.3更新种子点
——使用深度滤波器,将最新时刻求得的深度观测值,与上一时刻的深度估计值融合,直到seed深度收敛。

深度测量的模型可理解为高斯+均匀分布的混合模型
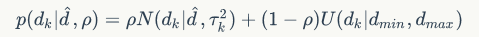
有效的深度测量值在真实深度值附近呈现高斯分布,
离群测量值在最大最小深度区间内服从均匀分布,并且 有效测量的概率 与 真实深度值 是独立分布的
在一些csdn中有关于深度估计概率模型的具体推导过程,不够有点没太看明白??????????????????
(尤其是怎么从均匀分布变到Beta分布的那部分,麻烦哪位同学有空帮我解答一下!!!!!)
总之,这个很厉害的深度滤波器能够在每加入一个新的深度测量值之后,就迅速调整概率分布,迭代出一个最佳的深度估计值,直到深度的方差收敛到给定的阈值,或者是该seed点被判断为离群点发散,才停止更新。
得到收敛的深度值之后,结合seed点的三维空间坐标,将其作为地图点,保存到地图中。
这就是建图线程大致要做的工作。
小结
博客是依据我个人对svo的理解并且结合已有的一些解析svo的博客内容写的,对svo的大致工作流程都已提及,有些细节部分的内容,还需继续学习。可能会存在一些理解不对或有误的地方,欢迎指出。
后续工作
关于后续学习方向,我想在深入理解svo的各个模块的工作机理的前提下,通过某些方法将imu的测量数据与svo的视觉里程计结合起来,实现更加鲁棒的视觉惯性测量。
个人认为svo是一个很好的组合导航的基础算法,可以在其基础上不断添加新的内容















 1491
1491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









