







 DyCo3D是2021年CVPR上提出的一种3D点云实例分割方法,它优于现有的bottom-up策略,通过动态卷积实现更高效率和准确性。该方法不依赖于提案,使用轻量级Transformer扩大感受野,捕获非局部依赖。实验显示,DyCo3D在3D点云实例分割任务上达到最先进的性能,同时具有更好的鲁棒性和更快的推断速度。
DyCo3D是2021年CVPR上提出的一种3D点云实例分割方法,它优于现有的bottom-up策略,通过动态卷积实现更高效率和准确性。该方法不依赖于提案,使用轻量级Transformer扩大感受野,捕获非局部依赖。实验显示,DyCo3D在3D点云实例分割任务上达到最先进的性能,同时具有更好的鲁棒性和更快的推断速度。

1. Motivation
- Previous top-performing approaches for point cloud instance segmentation involve a bottom-up strategy, which often includes inefficient operations or complex pipelines, such as grouping over-segmented components, introducing additional steps for refining, or designing complicated loss functions.
- The inevitable variation in the instance scales can lead bottom-up methods to become particularly sensitive to hyper-parameter values.
- Instance segmentation of3D point clouds has proven far more challenging.
- This is partly due to the inherent irregularity and sparsity of the data, but also due to the diversity of the scene.
之前相关的3D 点云实例分割的研究:
- 3D-MPA
- PointGroup(全文看下本文很多设定模仿这篇文章)
具体来说,之前bottom-up methods的缺点:
- the performance is sensitive to values of the pre-defined hyper-parameters, which require manual tuning.
- they incorporate either complex post-processing steps or training pipelines, rendering them unsuitable for real-time applications such as robotics and driverless cars.
- they are heavily reliant on the quality of the proposals, which limits their robustness and can lead to joint/fragmented instances in practice.
2. Contribution
- A novel method for 3D point cloud instance segmen- tation based on dynamic convolution that outperforms previous methods in both efficiency and effectiveness.
- A proposal-free instance segmentation approach that is more robust than bottom-up strategies.
- A light-weight transformer that enlarges the receptive field and captures non-local dependencies.
- Comprehensive experiments demonstrating that the proposed method achieves state-of-the-art results, with improved robustness, and an inference speed superior to that of its comparators.
3. Related Work
3.1 Deep Learning for 3D Point Cloud
- The most prevalent existing approaches can be roughly categorised as: point-based [29, 31], voxel-based [23, 40, 13, 6], and multiview-based [35, 30, 8].
- Multi- view solutions often involve view projection to utilize well-explored 2D techniques.
- Voxel-based methods first transfer 3D points into rasterized voxels and apply convolution operations for feature extraction.
3.2 Instance Segmentation of 3D Point Cloud
- As in the 2D image domain, 3D instance segmentation approaches can be broadly divided into two groups: top-down and bottom-up.
- Top-down methods often use a detect-then-segment approach, which first detects 3D bounding boxes of the instances and then predicts foreground points.
- Bottom-up methods, in contrast, group sub-components into instances. Methods ap- plying this approach have dominated the leaderboard of the ScanNet dataset,
3.3 Dynamic Convolution
- However, our experiments demonstrate that it performs poorly when applied directly to 3D point clouds.
- It introduces a large amount of computation, resulting in optimization difficulties.
- The performance is constrained by the limited receptive field and representation capability due to the sparse convolution.
4. Methods
4.1. Overall Architecture
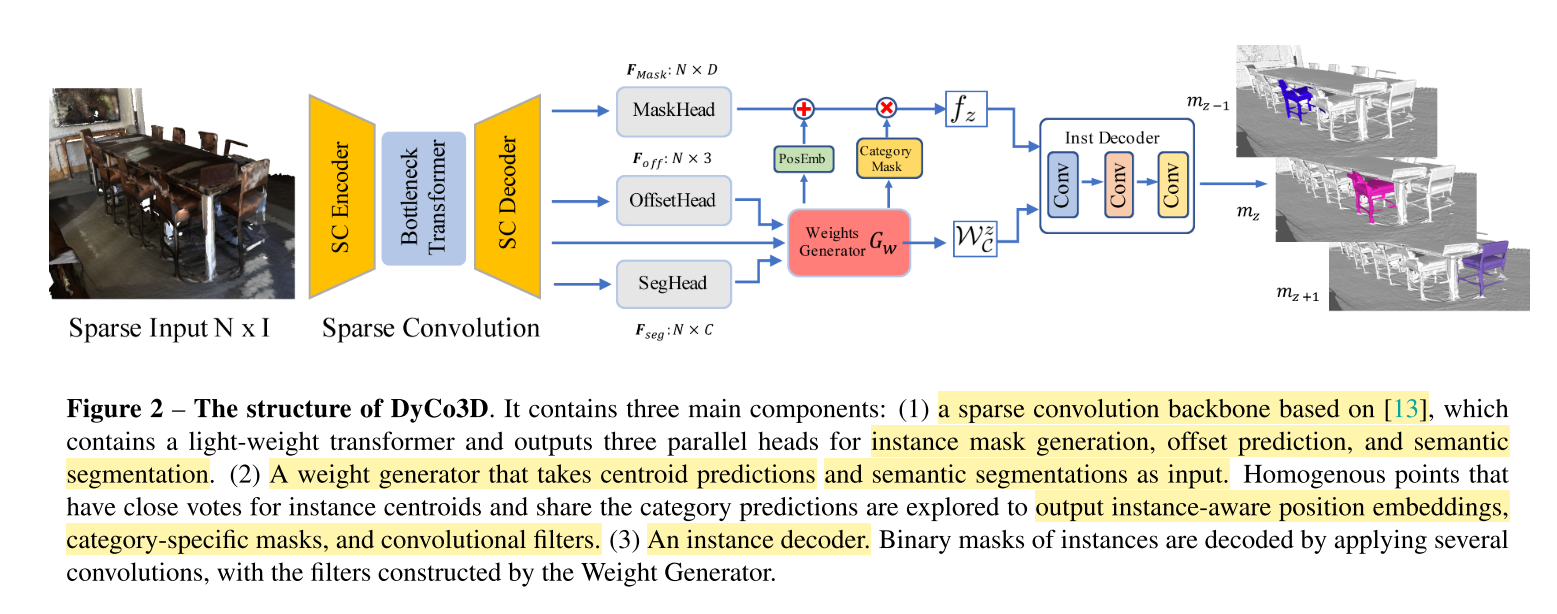
网络输入为 P ∈ N × I P \in N \times I P∈N×I,N个clound point。DyCo3D有三个部分:
- sparse convolution backbone,其中包含了light-weight transformer(位置编码与传统的transformer不同)
- weight generator,其中包含了MaskHead,OffsetHead,SegHead。
- instance decoder,动态卷积。
DyCo3D是一种proposal-free(可以类比为anchor-free)的检测器。
4.2 Backbone Network
4.2.1 Semantic Segmentation
F s e g ∈ R N × C F_{seg} \in R^{N \times C} Fseg∈RN×C,使用交叉熵计算point-wise所属于的标签分类的loss,Seg Head得到的是prediction of category label { l s e g i } i = 1 N \{l^i_{seg} \}^N_{i=1} { lsegi}i=1N。
4.2.2 Centroid Offset
Offset head分支得到的输出是 O o f f ∈ R N × 3 O_{off} \in R^{N \times 3} Ooff∈R
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 286
286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









