






Learning Progressive Modality-Shared Transformers for Effective Visible-Infrared Person Re-identification
学习渐进式模态共享transformers用于有效的可见-红外人员再识别
会议:AAAI CCF-A
代码:https://github.com/hulu88/PMT
摘要:为了减少模态间隙的负面影响,我们首先将灰度图像作为辅助模态(去除可见图像的颜色信息),并提出一种渐进式学习策略。然后,我们提出了模态共享增强损失(MSEL)来指导模型从模态共享特征中探索更可靠的身份信息。最后,针对类内差异大、类间差异小的问题,我们提出了一种结合MSEL的判别中心损失算法(Discriminative Center Loss, DCL),进一步提高了可靠特征的判别能力。
网络结构:
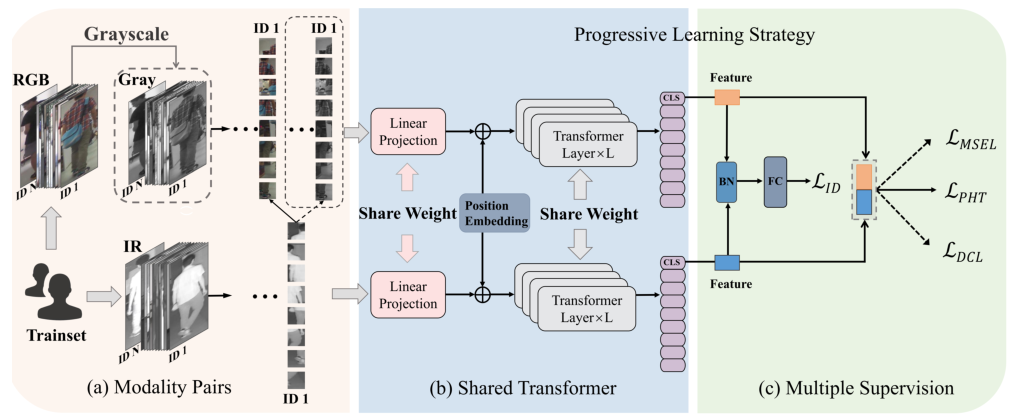
渐进式学习策略:1)第一阶段a->b,我们将灰度图像和红外图像输入到由LID和LPHT监督的权重共享Transformer中,进行模态无关的特征提取。2)在第二阶段c,我们利用视觉图像和红外图像来改进与LMSEL和LDCL的模态共享特征。
Progressive Learning Strategy
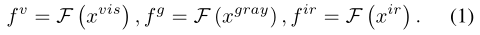
可见图像:
x
v
i
s
x^{vis}
xvis,对应灰度图像:
x
g
r
a
y
x^{gray}
xgray 红外图像:
x
i
r
x^{ir}
xir
PHT:在每个小批量中,随机选择P个身份,然后选择每个身份的K张可见光和K张红外图像, Progressive Hard Triplet Loss如下:
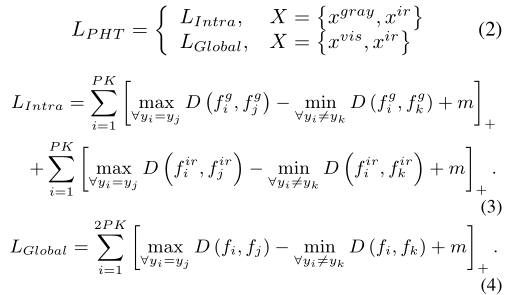
D(.,.)表示距离度量,yi第i个图像的身份标签,[z]+=max(z,0),m是边距
第一阶段取: x g r a y x^{gray} xgray, x i r x^{ir} xir作为输入,在每个模态内独立采样正负样本。使用LIntra,该框架主要侧重于学习模态独立的判别模式,从而有效缓解可见光和红外模态之间较大差距带来的负面影响。在第二阶段,我们用{ x v i s x^{vis} xvis, x i r x^{ir} xir}替换输入,以充分利用特定于模态的信息进行更细粒度的学习。使用LGlobal,框架将不再区分不同的模态,只根据特征距离选择正样本和负样本。这可以保留原始图像信息,并允许模型受益于特定于模式的信息。
Modality-Shared Enhancement Loss
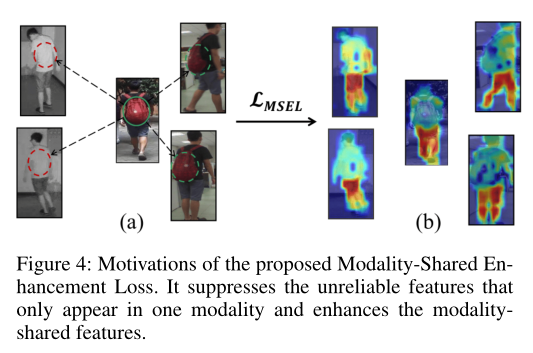
MSEL:抑制不可靠特征,提高可靠模态不变特征的利用率。例如,背包为不可靠特征。
从一个小批量的所有样本中探索潜在的信息。形式上,我们将红外和可见光模态的锚点特征分别表示为
f
i
r
f^{ir}
fira和
f
v
i
s
f^{vis}
fvisa。为了不失一般性,我们以
f
i
r
f^{ir}
fira为例。首先计算其在内模态和交叉模态下到其他正样本的平均距离,记为:
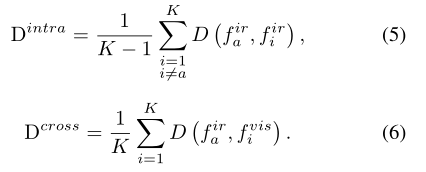
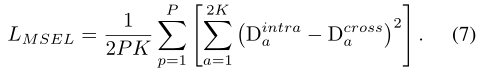
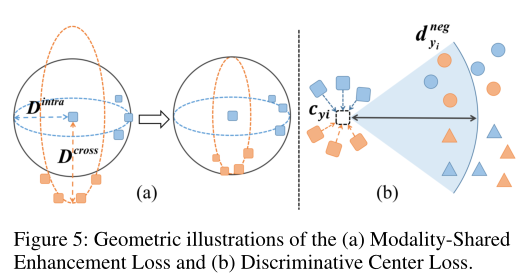
LMSEL惩罚了Dintra和cross之间的差异。当判别性特征只出现在一个模态中时,那么Dintra和cross之间的差异就会增大,这样的异常就会被LMSEL捕捉到。在Dintra和Dcross的双向优化过程中,只出现在一种模态的不可靠特征会被抑制,而同时出现在两种模态的更可靠特征会被增强,如图4 (b)所示。图5 (a)为MSEL的几何图解。它鼓励特征嵌入遵循球形分布。
Discriminative Center Loss
DCL:利用中心实例之间的示例关系,增强可靠模态共享特征的判别能力。
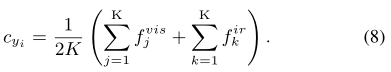
为了获得每个身份的鲁棒表示,我们计算两种模态下的特征中心,cyi代表
y
t
h
y^{th}
ythi恒等式的特征中心
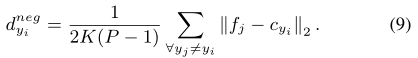
计算cyi到所有其他负样本的平均距离作为动态边界
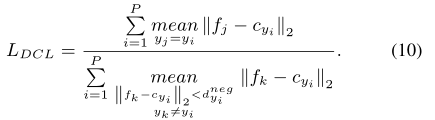
LDCL定义如上,最小化(10),可以提高类内紧性和类间可分性。图5 (b)显示了DCL的几何图示。
LDCL的利用有两个主要优点:1)它可以利用特定于模态的特征,并捕获比中心-中心解决方案更多的潜在关系。2)通过
d
n
e
g
d^{neg}
dnegyi进行动态采样可以有效地集中在相对困难的样例上。通过实验验证了该方法的有效性。
总体目标函数: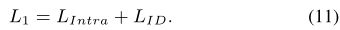
采用混合损失函数作为渐进式学习框架。在第一阶段,我们利用身份损失LID和LIntra来学习模态无关的特征。
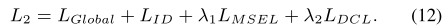
在第二阶段,我们进一步与LMSEL提取可靠的模态共享特征,并增强与LDCL的识别,损失函数如上,λ1和λ2分别用来平衡LMSEL和LDCL项
实验
数据集:
SYSU-MM01:有286,628张可见光图像和15,792张红外图像,包含491个不同的人身份。训练集包含395个人的22258张可见光图像和11909张红外图像,测试集包含另外96个不同身份的图像。
使用3803张红外图像作为查询query集,从其他可见图像中随机抽取301张图像作为图库galley集。此外,还有两种搜索模式。allsearch模式使用所有图像进行测试,而indoorsearch模式仅使用室内图像进行测试。
RegDB:总共包含412个不同的人身份。对于每个人,捕获10张可见光图像和10张红外图像。我们遵循(Ye et al . 2018)中的评估方案,随机选择206个身份的所有图像进行训练,其余206个身份进行测试。为了获得稳定的结果,我们将该数据集随机分成10次进行独立训练和测试。
实验细节:
方法是在Huawei-Mindspore工具箱的NVIDIA RTX3090 GPU实现,采用ViT-B/16 (Doso-vitskiy et al. 2020)在ImageNet (Deng et al.2009)预训练作为骨干,并将重叠步幅设置为12,以平衡速度和性能。所有人物图像都将调整为256×128,并使用水平翻转和随机擦除来增强数据。对于红外图像,彩色抖动color jitter和高斯模糊gaussian blur是额外的应用。批大小设置为64,总共包含8个不同的身份。对于每个身份,分别采样4张可见光图像和4张红外图像。我们采用AdamW优化器和余弦退火cosine annealing学习率调度器进行训练。基本学习率设置为3
e
−
4
e^{−4}
e−4,权值衰减设置为1
e
−
4
e^{−4}
e−4。我们为SYSU-MM01训练了24个epoch,为RegDB训练了36个epoch。
对于两个数据集,第一阶段的epoch t设置为6,权衡参数λ1和λ2设置为0.5,边际参数m设置为0.1。在BN层之后使用768维特征进行测试。
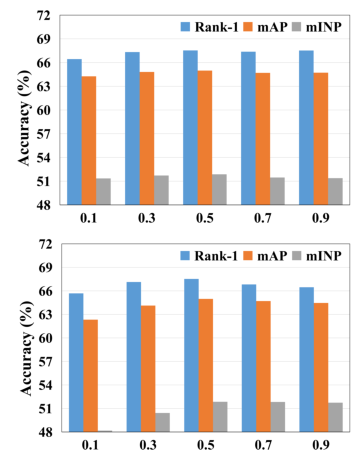
权衡参数λ1和λ2对性能的影响。在上面的子图中,λ2=0.5,λ1∈[0.1,0.9];在下面的子图中,λ1=0.5,λ2∈[0.1,0.9]















 2454
2454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









