







2.6 Model Ensembling
Bagging reduces variance
Boosting reduces bias
决策树最明显的缺点是,它们容易过拟合:如果深度较低,逼近能力就较低,但当深度较大时,数据往往会过度拟合。 图2.7给出了一个说明。

然而,有一类方法极大地克服了这一缺点,它们使决策树的应用更加广泛。 这些方法被称为 集成方法 ,我们将一组弱学习器 weak learners (来自小假设空间的模型)组合起来,形成一个具有良好近似和泛化特性的强学习器 strong learner。 弱学习器的角色通常由决策树来扮演。 不过,我们可以针对一般的弱学习器讨论这些方法。 我们将介绍两种不同的方法来 组合模型 ,即装袋和增压 bagging and boosting 。
2.6.1 Bagging 装袋
我们讨论的第一种组合模型的方法可能也是最明显的:我们将基于 训练集 ,根据在不同子样本上训练的得到的模型集合,对预测进行聚合——对于回归问题,我们简单地取它们的 平均预测 ;对于分类问题,我们采用 多数投票法 进行模态预测。

这被广泛地称为引导聚合 bootstrap aggregating 或bagging方法。 回归案例总结在算法1中。 分类案例类似。
-
Algorithm 1: Bootstrap aggregating / Bagging
Data : D = { x i , y i } i = 1 N \mathcal{D}=\{x_i,y_i\}^N_{i=1} D={xi,yi}i=1N
for j = 1 , . . . , m j=1,...,m j=1,...,m do
| 组一个随机,独立的、大小为 N ′ N' N′ 的数据子集 D j \mathcal{D}_j Dj,在放回的条件下
| 在 D j \mathcal{D}_j Dj 上,从经验风险最小化得到 f j f_j fj
end
return f ˉ ( x ) = 1 m ∑ j = 1 m f j ( x ) \bar f(x)=\frac 1m\sum^m_{j=1}f_j(x) fˉ(x)=m1∑j=1mfj(x)

装袋的目的是什么? 为了看到这一点,我们可以考虑一个简单的套袋回归模型。 假设我们有一组来自固定的假设空间 H \mathcal{H} H 的训练过的模型 { f i } i = 1 m \{f_i\}^m_{i=1} {fi}i=1m。我们假设每个 f i f_i fi 都是oracle函数 f ∗ f^* f∗ 的随机近似,即:
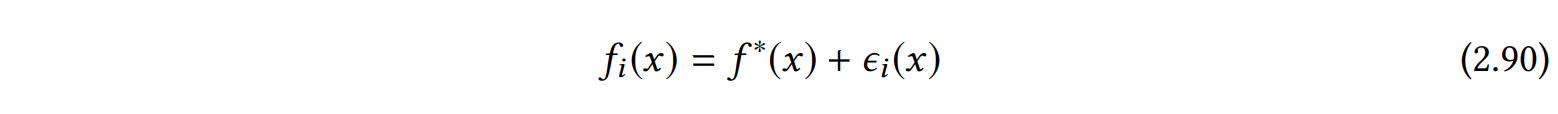
其中, ϵ i \epsilon _i ϵi 为 均值为0方差为 σ 2 \sigma ^2 σ2 的随机方程。
聚合预测函数为:

现在我们将证明,在假设 i ≠ j i\ne j i=j, ϵ i \epsilon _i ϵi 和 ϵ j \epsilon _j ϵj 是不相关函数的情况下,聚合函数__减少了均方误差__。要看到这一点,请注意每个 f i f_i fi 预测的均方误差为:

另一方面,聚合预测的平方误差为:

显然,减少了。

如果存在偏差,每个 E ϵ i ( x ) = b ( x ) ≠ 0 \mathbb{E}ϵ_i(x) = b(x) \ne 0 Eϵi(x)=b(x)=0 ,会发生什么?
可以看出, E f ˉ = E f i = b \mathbb{E}\bar f = \mathbb{E}f_i = b Efˉ=Efi=b,即,聚合模型没有改变偏差。然而,一个类似于上面的计算表明,它将方差减少了m倍。更一般地,这个结果可以由中心极限定理或浓度/大偏差估计 the central limit theorem, or concentration/large-deviation estimates 推导出来。

在实践中,很少观察到明显显著性方差减少。 这是因为误差 ϵ i ϵ_i ϵi 是通过对训练数据集进行子抽样而形成的:
- 如果样本数量较少,则方差 σ 2 σ^2 σ2 较大;
- 如果取了大量的样本,那么不同的模型就会变得高度相关。
- 更重要的是,套袋并不能有效地减少模型的偏差。 换句话说,它并没有提高潜在假设空间的逼近能力。
下面,我们将介绍另一种结合模型的方法,它实际上增加了 近似能力 。
2.6.2 Boosting
与 并行 组合模型的套袋不同,Boosting 组合模型是 按顺序进行 的。 最基本的助推形式是自适应助推,或AdaBoost 。 AdaBoost的主要思想是在对每个弱学习器进行训练后,自适应地重新 加权训练 样本,使下一个弱学习器可以集中精力纠正前一个学习者所犯的错误。 最后,对弱学习器进行适当的权值组合,以减少整体误差。 Adaboost算法在算法2中给出。
-
Algorithm 2: AdaBoost

-
在所有训练样本中使用统一权重进行初始化
-
训练一个分类器/回归器 f 1 f_1 f1
-
识别 f 1 f_1 f1 出错(分类)或有较大误差(回归)的样本
-
对这些样本进行更大的权重,并在这个重新加权的数据集上训练 f 2 f_2 f2
-
重复步骤3 - 5
从算法2中,我们观察到 f 1 f_1 f1 是用 w i = 1 / N w_i = 1/N wi=1/N 的均匀权值进行训练的,即按照通常的方式。 随后,对错误分类的点增加权重,对正确分类的点减少权重。 因此,鼓励后续学习器关注这些错误分类的要点。 加权系数 α j α_j αj 赋予更精确的分类器更大的权重,从而提高总体分类精度。
手写笔记





















 353
353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









