







文章目录
-
- 概要
- lora原理
- 细节
概要
大模型颠覆了nlp领域,通过与大模型对话就可以帮助我们解决文本任务,比如文本总结、写报告、写代码以及解答疑问等。
其中向大模型的提问就是编写prompt,但是在实际使用过程中往往会发现即使我们编写的prompt拥有了专有知识,比如说问答对、领域知识、示例sql查询等,大模型不一定会按照我们的预期做出回答。即使逐字调整的prompt临时取得了较好的效果,隔一天测试发现还是有偏差。为了实现大模型稳定地输出正确结果,可以使用私有数据微调大模型。
不同于得到预训练模型,微调是以预训练模型为基础,运用私有数据仅仅训练少量参数,即可适配不同的下游任务,主要流派分为基于adapter、基于selective、基于prompt、基于reparameter的几种。其中,lora作为reparameter流派,适用于NLG任务,具有低资源(算力、存储)、可插拔以及没有推理延迟的特点。
本系列文章围绕lora先后介绍:lora的原理、如何根据私有数据构建微调数据集、lora微调的过程以及微调效果不好可能的原因。
lora原理
下图是简化版的大语言模型的拓扑结构,结构中各个block的embedding、attention以及feedforward等模块蕴含着大量可训练的参数。
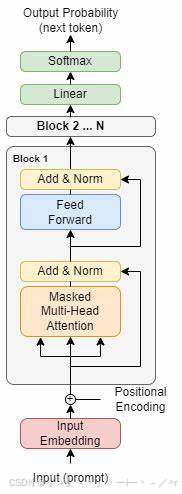
图1
lora的思想是当微调训练时,在预训练模型的参数W基础上加上ΔW旁路作为前向计算的参数,但是保持预训练模型的参数W不变,仅仅反向梯度更新ΔW的参数。
此外假定ΔW旁路由B、A两个低秩矩阵相乘得到。其中矩阵B、A的维度分别为(r×d)和(d×r),且r的值远远小于d,那么相较于优化器直接梯度更新d×d的参数,lora仅仅需要(r×d)+(d×r)旁路参数,大大减少了所需要优化的参数、实现了相较于全参数低资源微调大模型的效果。
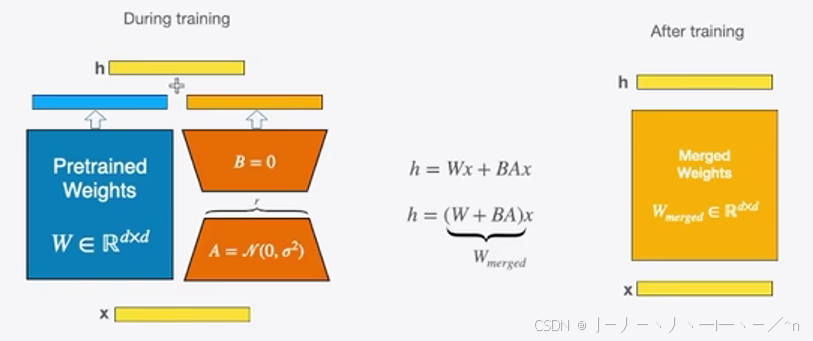
图2
细节
需要注意的是,旁路参数可以作为可插拔的部分存储,也就是说,对于不同数据集或不同下游任务,使用lora方法能做到保存各自的微调参数,推理时只需将该旁路合并到原始预训练模型中即可。
一般来说,微调针对的是multi-head attention模块中的Wq,Wk,Wv,Wo四个矩阵添加旁路,并且ΔW低秩分解中的r为需要调整的超参。
ref:
(1)Hu, J.E., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., & Chen, W. (2021). LoRA: Low-Rank Adaptation of Large Language Models. ArXiv, abs/2106.09685.
(2)https://ai.stackexchange.com/questions/40179/how-does-the-decoder-only-transformer-architecture-work


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









