







概要
transformer模型中分为encoder和decoder模块,encoder模块是由encoder block(或称encoder layer)堆叠而成,decoder模块是由decoder block堆叠而成。
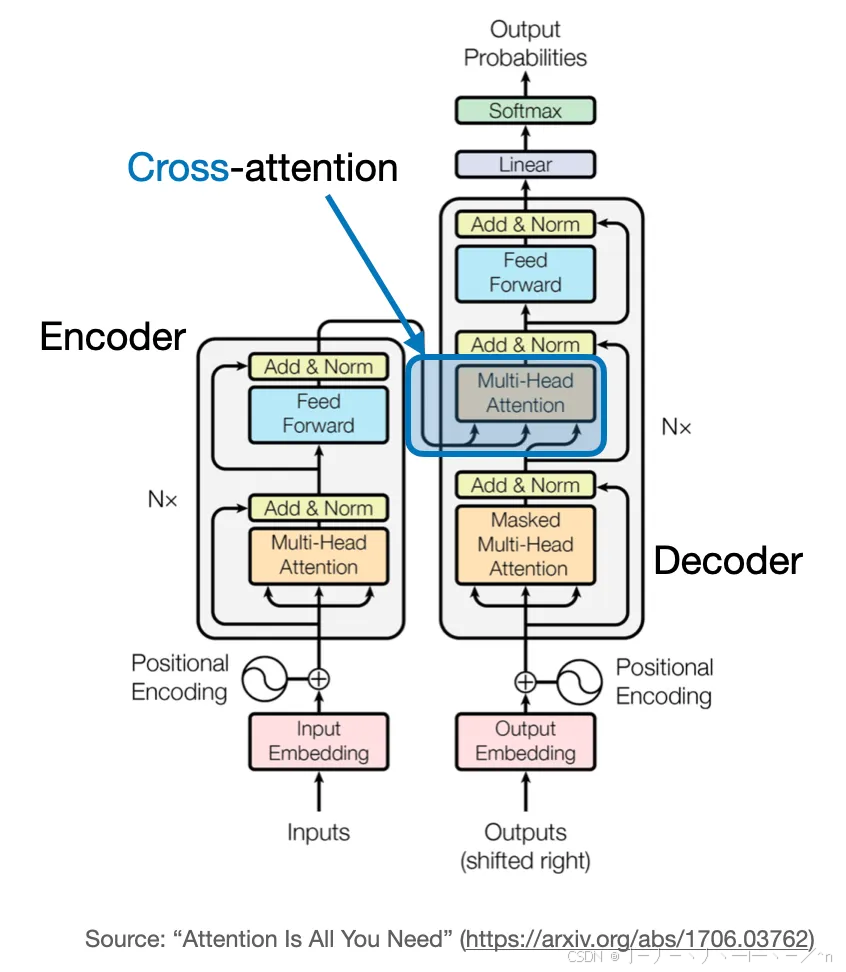
encoder block包含了 multi-head self-attention,而decoder block包含了masked multi-head self-attention以及cross-attention。本篇文章以代码的形式解读这三个attention的共性和区别。
encoder layer的self-attention
对于encoder layer的multi-head self attention和decoder layer的masked multi-head self attention,本质上都是multi-head self attention,区别是attention score中的mask的不同,encoder layer的self attention的mask是为了遮掩batch个encoder输入句子中的pad token,即padding mask。
也就是说,用于计算出self-attention的、
、
均来源于相同的序列embedding
。
如下图举例来说,encoder layer的multi-head self attention处理的序列输入是how are you。
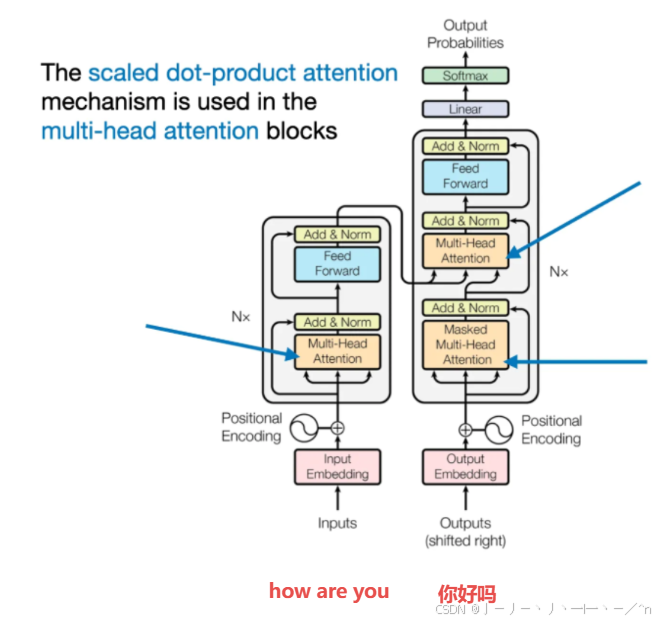
attention类似于bert的attention是双向的,mask是为了遮盖batch个句子中的key padding token。
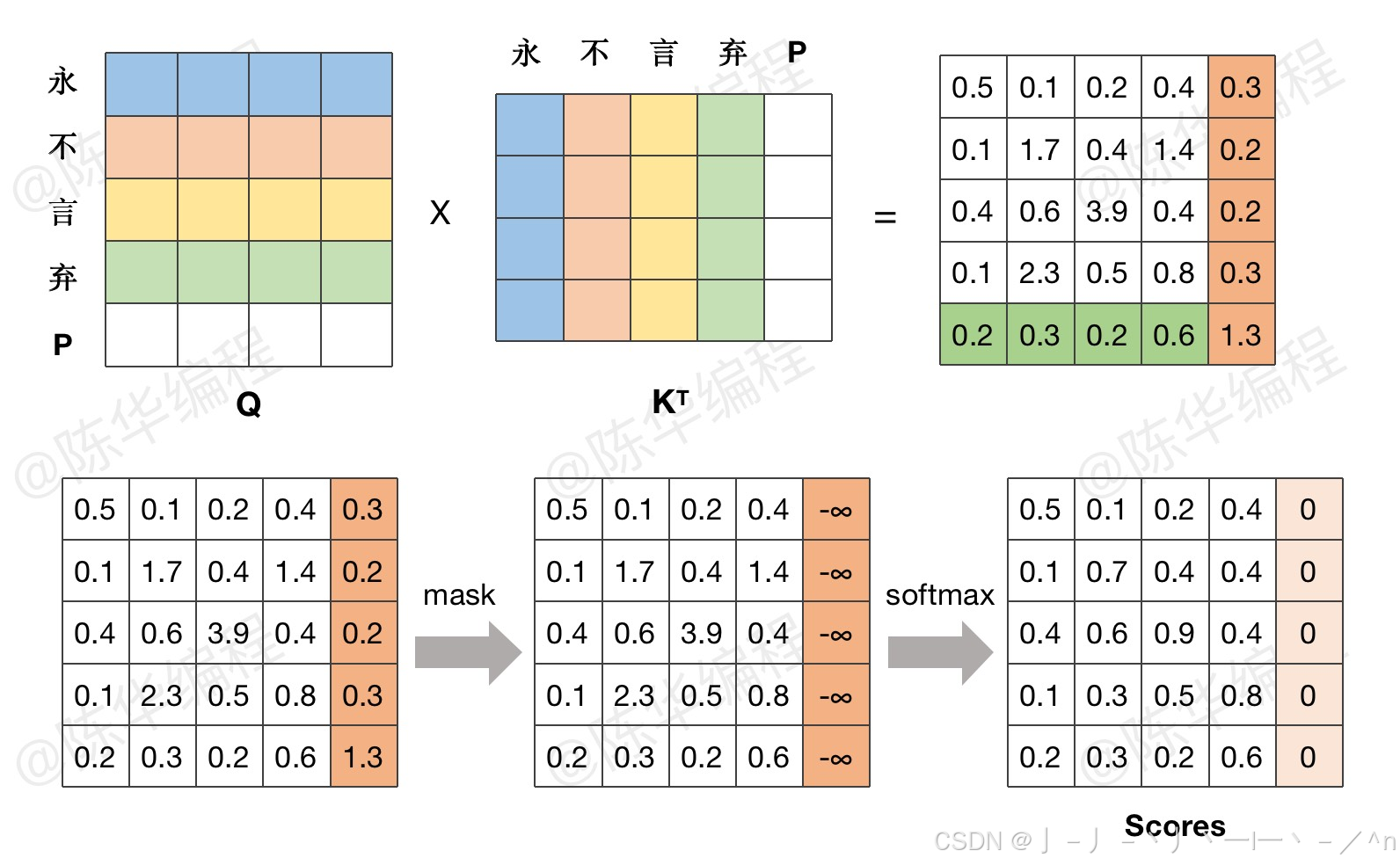
可以按照下图理解,引用自Transformer P8 Attention处理Key_Padding_Mask - 陈华编程
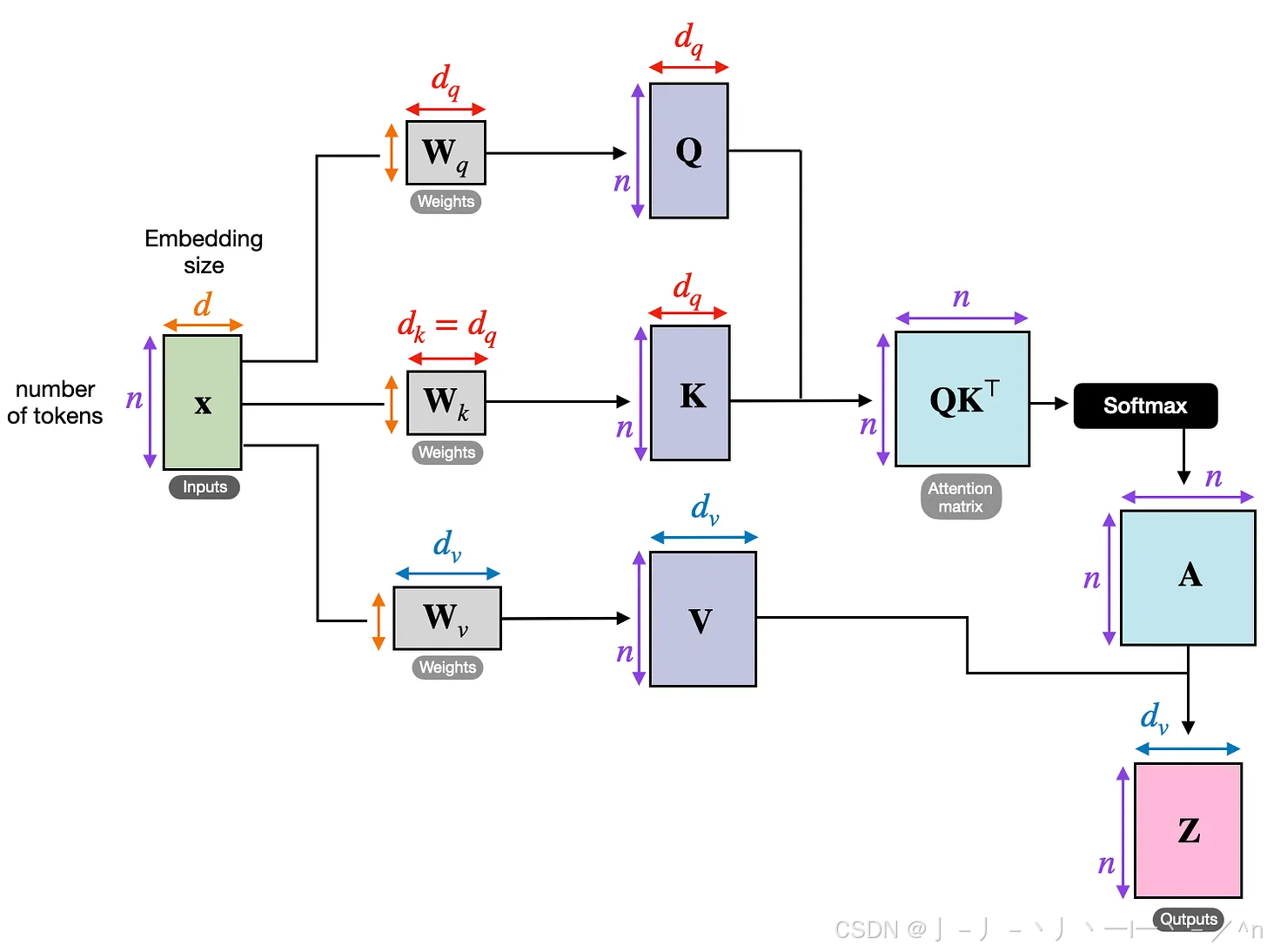
为了加强理解多头注意力,我们用pytorch代码实现一遍,并造数据实现一次正向传播。
import math
from random import randint
import torch
from torch import nn
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_head):
super().__init__()
assert d_model % n_head == 0
self.d_k = d_model // n_head
self.n_head = n_head
self.linears = nn.ModuleList(
[nn.Linear(d_model, d_model) for _ in range(4)]
)
def forward(self, x, mask):
'''
x: (batch_size, seq_len, d_model)
'''
batch_size = x.size()[0]
q, k, v = [l(x).view(
batch_size, -1, self.n_head, self.d_k).transpose(1, 2) for l in self.linears[:3]]
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_k)
if mask is not None:
if mask.dim() == 3:
mask = mask.unsequeeze(1)
if mask.dim() == 2:
mask = mask[:, None, None, :]
scores = scores.masked_fill(mask == 0, -1e9)
scores = torch.softmax(scores, dim=-1)
concat_multi_head_seq = torch.matmul(scores, v).transpose(
1, 2).contiguous().view(
batch_size, -1, self.n_head * self.d_k)
context_seq = self.linears[-1](concat_multi_head_seq)
return context_seq, scores正向传播如下:
max_seq_len = 5
num_head = 2
d_model = 4
vocab_size = 100
batch_size = 2
att = MultiHeadAttention(d_model, num_head)
# 造出batch_size个句子的序列embedding
x = torch.randn((batch_size, max_seq_len, d_model))
# 造出句子的token长度
sentences_lens = [randint(1, max_seq_len) for _ in range(batch_size)]
# 造出句子的mask
mask = torch.tensor([
[1 if i <= per_sentence_len else 0 for i in range(max_seq_len)]
for per_sentence_len in sentences_lens])
attention_context, attention_scores = att(x, mask)
print(attention_context.shape)
print(attention_scores.shape)decoder layer的self-attention
decoder layer的masked multi-head self attention的mask除了要遮掩住batch个decoder的输入句子中的pad token,还要避免看见处于当前token位置后面的token的attention score。
按上一节图举例来说, decoder layer的masked multi-head self attention处理的序列输入是你好吗,mask相比双向attention还增加了遮掩还未生成的token,即对于“你”这个token要遮盖它与“好”、“吗”之间的attention score。
可以参考下图理解,引用自Understanding and Coding Self-Attention, Multi-Head Attention, Cross-Attention, and Causal-Attention in LLMs
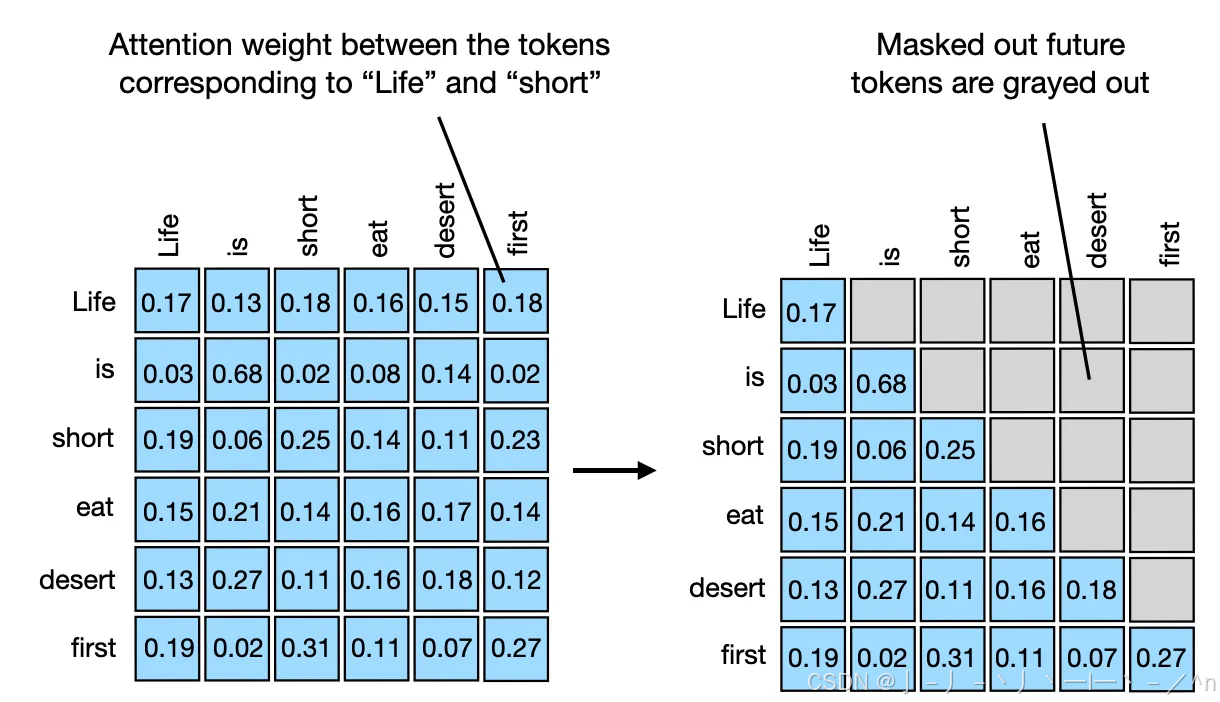
让我们实现一次同时具有pad mask和casual mask的正向传播。
masked_att = MultiHeadAttention(d_model, num_head)
# 造出batch_size个句子的序列embedding
x1 = torch.randn((batch_size, max_seq_len, d_model))
# 造出句子的token长度
sentences_lens1 = [randint(1, max_seq_len) for _ in range(batch_size)]
# 造出句子的mask
pad_mask = torch.tensor([
[1 if i <= per_sentence_len else 0 for i in range(max_seq_len)]
for per_sentence_len in sentences_lens1])
# 生成一个下三角矩阵作为掩码
triangular_mask = torch.tril(
torch.ones((max_seq_len, max_seq_len)).type_as(pad_mask))
# pad_mask位与casual_mask
mask1 = pad_mask.unsqueeze(1) & triangular_mask.unsqueeze(0)
attention_context1, attention_scores1 = masked_att(x1, mask1)小结
本文从理论和实践的角度解读了transformer模型中encoder和decoder的self-attention的区别,点赞,关注和收藏,下篇文章解读transformer中cross-attention相比self-attention的区别。

















 1295
1295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









