







概要
大语言模型本质上是一个深度学习模型,而深度学习的思路是迭代优化数据集前向传播值与真实值之间的损失函数。对于decoder-only大语言模型,预训练阶段的损失函数是什么呢?本文以概率论和代码的视角给出解读。
前置知识
机器学习中,分类问题的损失函数是模型预测值与真实标签之间的交叉熵。因为以概率论角度,交叉熵衡量了两个随机变量分布的差异。
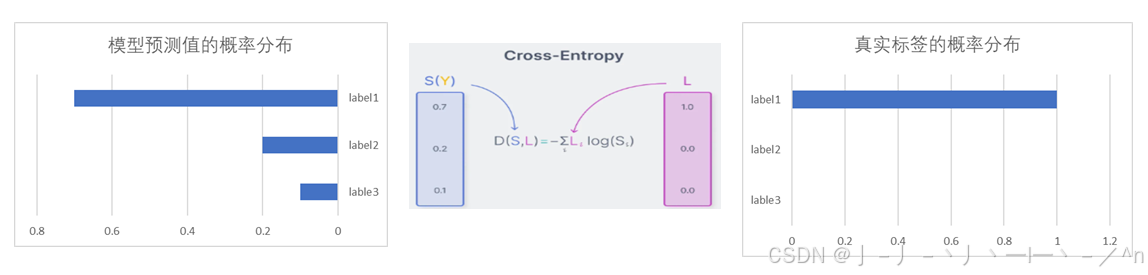
上图为交叉熵的表达式,其中L为某样本的true label的分布,S为某个样本经模型前向计算得到的预测值的分布。图中的交叉熵
也就是说,分类问题的深度学习模型期望通过训练最小化损失函数
其中为模型预测值;
为当input为
时,模型预测值
取不同label时的条件概率。
大模型预训练时的损失函数
对于decoder-only大语言模型,预训练思路都是期望一个token输入进去decoder model后输出后一个token,其本质是分类问题,损失函数自然也是交叉熵。
不同的是,预训练阶段对于每条数据(一个句子)中的每个token都要计算交叉熵损失。拿下图举例来说:
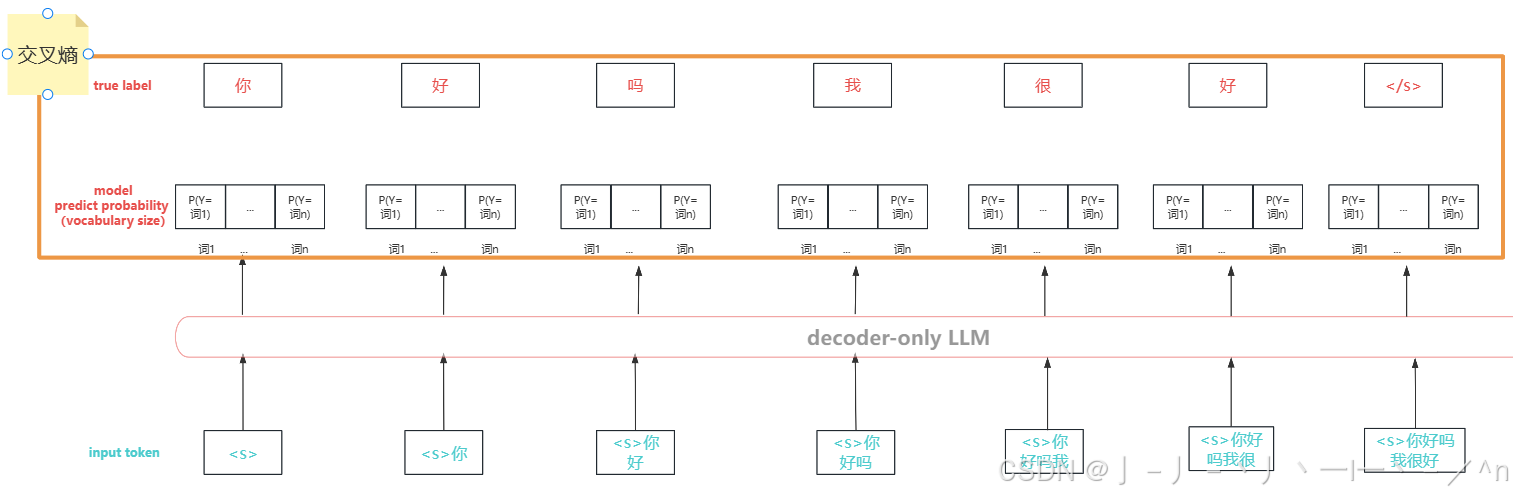
对于“你好吗我很好”这个句子,tokenizer切分后的token,作为decoder-only LLM的输入,input token期望预测出的下一个token为真实token的平均交叉熵最小,即下式:
((
(Y=你|<s>)
(Y=好|<s>你)
(Y=吗|<s>你好)
(Y=我|<s>你好吗)
(Y=很|<s>你好吗我)
(Y=好|<s>你好吗我很)
(Y=</s>|<s>你好吗我很好))*(1/6))
注意由于数据集中每个句子的sequence length不一定相同,所以每个句子的损失函数将所有input token的交叉熵求和后需要取平均值。
代码体验
利用transformers手搓下llama模型的损失函数来加强理解吧!
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from torch.nn import CrossEntropyLoss
cache_dir_local = "./models/"# dir for cache
BASE_MODEL = "./models/"
# initialise tokenizer
llama2_tokenizer = \
AutoTokenizer.\
from_pretrained(BASE_MODEL,
padding_side="left")
# initialise model
llama2_model = \
AutoModelForCausalLM.from_pretrained(
BASE_MODEL,
use_cache=True,
device_map="cuda",
cache_dir=cache_dir_local,
torch_dtype=torch.float16
)
# example input text
text_input = '你好吗我很好'
toks = llama2_tokenizer(text_input, return_tensors='pt').to(llama2_model.device)
# labels of CLM can be taken as inputs, huggingface will handle the shifting of the labels as mentioned above.
toks['labels'] = toks['input_ids']
out = llama2_model(**toks, output_hidden_states=True, return_dict=True)
print(out['loss'])输出
![]()
# 取出0-11的input token的umembedding向量
logits = out['logits']
shift_logits = logits[..., :-1, :].contiguous()
# 取出1-12的input token的真实token,这里体现了向后一位token预测的思想
labels = toks['labels']
shift_labels = labels[..., 1:].contiguous()
# flatten batch
shift_logits = shift_logits.view(-1, 32000)
shift_labels = shift_labels.view(-1)# 取出0-11的input token的llama模型的预测概率P(output token=真实token|input token)
softmax_prob_at_label_tokidx = torch.nn.Softmax()(shift_logits)[torch.arange(shift_labels.size(-1)), shift_labels]
#print(softmax_prob_at_label_tokidx)
loss = (softmax_prob_at_label_tokidx.log() * -1).mean()
print(loss)![]()
这个结果与out['loss']相同验证了我们的思想。
小结
本文从概率论和代码的角度分析了大模型预训练的本质是优化一个用于分类的深度学习模型,因此预训练时候的损失函数本质为输入token的平均交叉熵。
点赞,关注和收藏,祝你的代码永无bug!!!

















 520
520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









