







概要
作为开源可商用的大语言模型LLaMA 2.0,它在学术基准上超过了其他同尺寸的开源模型。你一定想知道是什么模型结构使得它取得了较好的表现?
如图一所示,相比于transformer的decoder,LLaMA 2.0在模型架构中引入了: group query attention、SwiGLU 激活函数、旋转位置嵌入、均方根层归一化。本系列文章将先后带你介绍这些模块,让我们开始吧。
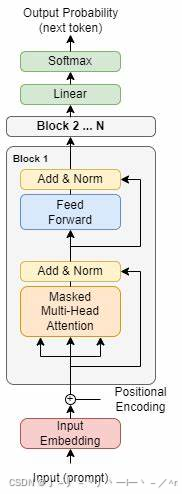
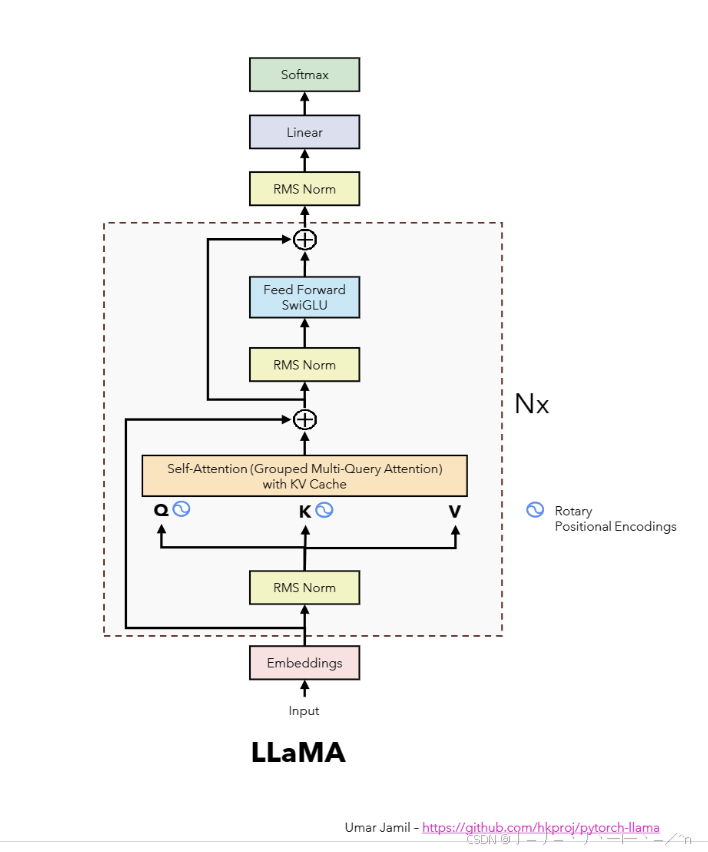
图一
group query attention是什么
我们注意到transformer decoder中使用的是multi-head attention,而llama2模型使用的是group query attention。
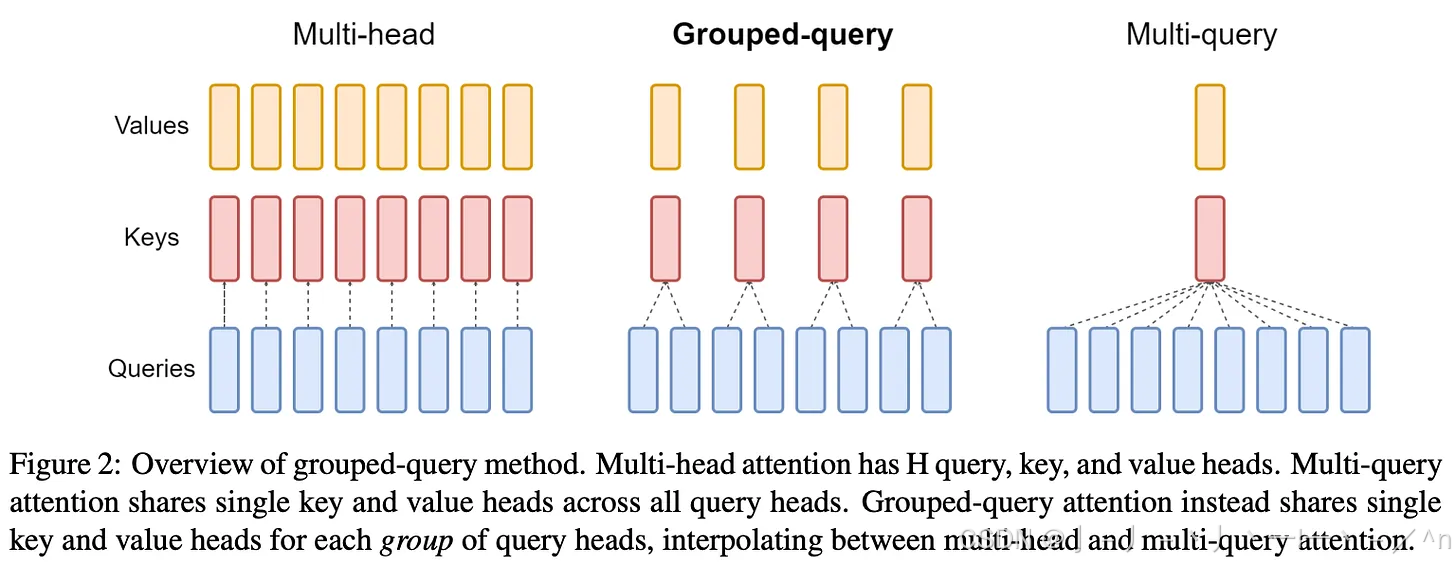
multi-head attention(上图左一)指的是用N个self-attention来计算出参考上下文的token embedding,具体来说,对于每个token计算出N个q向量,N个k、v向量,其中第i个attention用第i个q向量、第i个k、v向量计算出来。
同样是计算N个self-attention,multi-query attention(上图右一)对于每个token计算出N个不同q向量,1个k、v向量,其中第i个attention用第i个q向量、同一个k、v向量计算出来。
而group query attention(上图中间),将N个attention分为G个组,每个组共用相同的k、v向量。每个token计算出N个不同q向量,第i个attention用第i个q向量、i所属组的k、v向量计算出来。
group query attention的意义
- 从gpu内存的角度
以前的文章概念|如何根据大模型api服务定价推测云厂商让利程度?-CSDN博客提到过,大模型的推理用kv cache空间换时间,multi-head attention每推理输出一个token都要加载已经缓存的N个头的kv cache,而GQA的分组使得只需缓存G个kv cache,也就是说kv cache的memory从block的数目*推理样本数目*N*sequence_length*attention的head的维度*2变为block的数目*推理样本数目*G*sequence_length*attention的head的维度*2。因此大模型推理服务可以同时处理更多的请求,吞吐量就变大。
- 从通信的角度
大模型的推理每推理出下一个token时都需要加载前序所有token的kv cache,带宽的限制了推理的速度,group query attention的kv cache的size更小,相比于multi-head attention减少了加载和更新kv cache的时间,所以group query attention推理速度势必更快。
- 从模型质量的角度
multi-query attention相比于multi-head attention减少了用于计算出K 、V矩阵的数目,随着模型参数数量的减少,从标准的multi-head attention到multi-query attention的转变会导致模型性能的下降。group query attention这种折中的方式,不仅能在模型质量上与multi-head attention差别不大,还能相比于multi-head attention推理快。
小结
本文对比分析了GQA 与MHA和MQA,从多角度给出了llama2模型中GQA的含义和意义。
喜欢这篇博文就关注、点赞和收藏吧!

















 3982
3982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









