







概要
lora全称LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS,即大语言模型的低秩适配器,被广泛用于大模型微调来适应私有数据。上篇文章大模型微调|从原理到实践之lora(一)-CSDN博客照本宣科得讲述了该方法的优点和基本思路,本篇文章重点介绍为何低秩适配行之有效?以及它行之有效的数学原理。
根据SVD理解矩阵的秩
SVD(奇异值分解)能够将矩阵 M表示为两个矩阵的乘积,以一种分解的方式表达 M的信息量。即使 M 是高秩的,仍然可以被两个相乘的低秩矩阵近似。
对于实对称矩阵(m×n),SVD能够将该矩阵分解为
其中 U 是 m 阶正交矩阵,V 是 n 阶正交矩阵, 是由降序排列的非负的对角线元素组成的 m × n 矩形对角矩阵。矩阵
的秩等于
对角线中非负元素的个数。
我们可以继续将上式等价变换为,令
、
,则
可以按下图理解该矩阵分解:
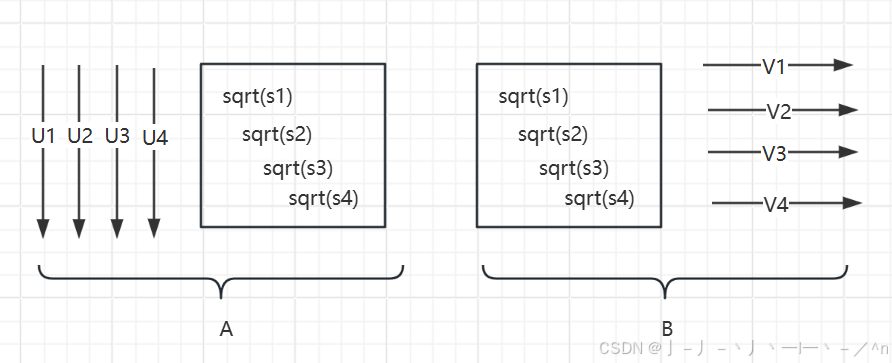
如下代码能够帮助你理解这种近似:
import torch
torch.manual_seed(13)
# Original matrix
M = torch.rand(4, 4)
# Perform Singular Value Decomposition
U, S, Vt = torch.svd(M)
print(f'矩阵M有{torch.count_nonzero(S)}个非负的奇异值')
print(f'矩阵M的秩为{torch.linalg.matrix_rank(M)}')以上代码输出

如下图所示
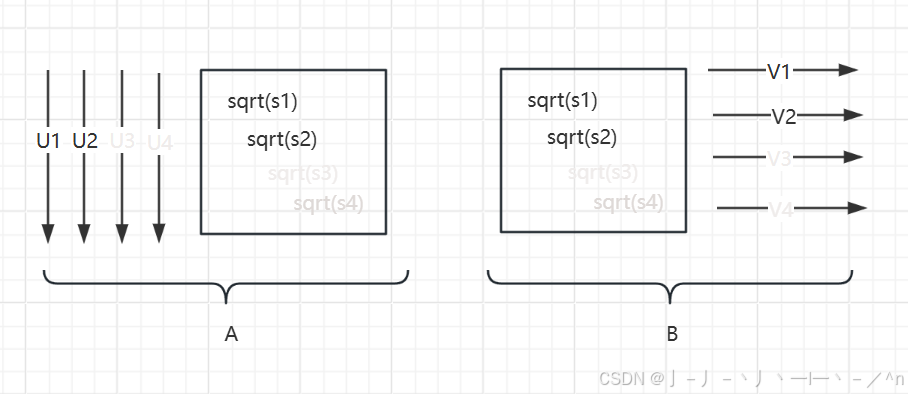
当我们选取矩阵中top2的对角元素时,对应的
、
以及
、
组成的部分
、部分
相乘得到的矩阵能够近似
矩阵。
# Rank r = 2 for low-rank approximation
# if we set r = 4, we reconstruct the same original matrix
r = 2
Ur = U[:, :r]
Sr = torch.diag(S[:r])
Vtr = Vt.t()[:r, :]
# Initialize A and B using the SVD components
A = torch.mm(Ur, torch.sqrt(Sr))
B = torch.mm(torch.sqrt(Sr), Vtr) #V transpose
# Approximate W from A and B
M_approx = torch.mm(A, B)
print("原始矩阵M:\n", M)
print("仅仅取top2方向的近似矩阵:\n", M_approx)
# print('原始矩阵和近似矩阵的差异\n', M-M_approx)
ok,现在我们有了一个认识,用的子矩阵和
的子矩阵能够对原始矩阵
近似表示。其中
的子矩阵和
的子矩阵仅仅对应了
矩阵部分奇异值(也就是部分秩),所以是对原始矩阵
近似表示。
低秩近似
低秩近似能够用两个低秩矩阵相乘来近似原矩阵。如下图所示,矩阵是M×K的size,
矩阵是K×N的size,其中
、
。
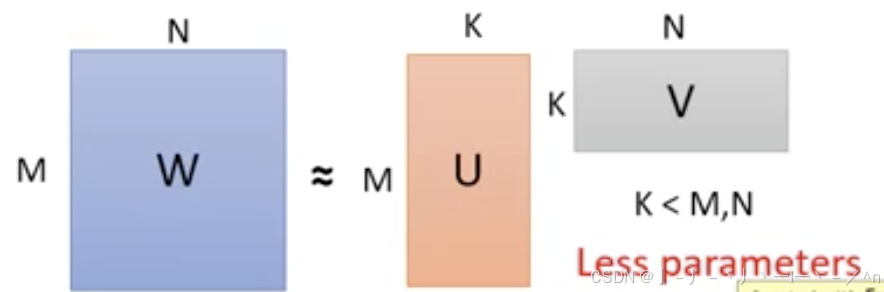
根据线性代数的定理rank(U)≤K,rank(V)≤K,rank(UV)≤min(rank(U),rank(V)),因此rank(UV)≤K。也就是说矩阵
矩阵相乘能够在部分秩的方向上实现对
矩阵的近似。
根据低秩近似理解lora
lora本质上是对深度学习中可训练的参数矩阵增加了一个adapter来拟合权重
:
=
由于lora的用途是微调大模型,真实的秩并不会很大。
当矩阵
矩阵的size的K值较小,
矩阵、
矩阵的秩则较小,参数矩阵
的秩必然较小,只考虑较小的方向来实现对真实
的有损近似,而不是直接更新参数量较大的
。
当然,低资源会在某种程度上降低了精度。所以设置合适的K值是lora比较重要的超参。
小结
本篇文章阐述了矩阵的秩本质上表达了矩阵的信息量分布在哪些方向,低秩矩阵相乘能够近似高秩矩阵以及低秩近似能够近似地表达lora适配器的权重从而达到低资源微调大模型的目的。
喜欢这篇博文就点赞、关注并收藏吧!下篇文章就开始实战啦!

















 2284
2284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









