






概要
BERT(Bidirectional Encoder Representations from Transformers)采用Transformer的编码器结构,迁移学习告诉我们可以将bert预训练模型微调来适应文本分类、多标签分类、阅读理解等任务。其中,Bert-base-chinese模型是一个在简体和繁体中文文本上训练得到的预训练模型。
训练流程
1.加载数据集
数据集采用用户观点数据集,数据中主题被分为10类,包括:动力、价格、内饰、配置、安全性、外观、操控、油耗、空间、舒适性。
from torch.utils.data import Dataset
import re
def split_labels(labels):
for idx, label in enumerate(labels):
labels[idx] = label.split('#')
labels = list(zip(*labels))
return labels[0], labels[1]
def get_query_and_labels(line):
clean_text = re.sub(r'\s', '', line)
labels = re.findall(r'(动力#-?\d+|价格#-?\d+|内饰#-?\d+|配置#-?\d+|安全性#-?\d+|外观#-?\d+|操控#-?\d+|油耗#-?\d+|空间#-?\d+|舒适性#-?\d+)', clean_text)
labels_text = ''.join(labels)
clean_text = clean_text.split(labels_text)[0]
theme_labels, emotion_labels = split_labels(labels)
return clean_text, theme_labels, emotion_labels
class UserView(Dataset):
def __init__(self, data_file):
self.data = self.load_data(data_file)
def load_data(self, data_file):
Data = {}
with open(data_file, 'rt', encoding='utf-8') as f:
for idx, line in enumerate(f):
line = line.strip()
items = get_query_and_labels(line)
assert len(items) == 3
Data[idx] = {
'text': items[0],
'theme_label': items[1],
'emotion_label': items[2]
}
return Data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
from torch.utils.data import random_split
train_data = UserView('datasets/train.txt')
train_data, valid_data = random_split(train_data, lengths=[0.9, 0.1])
print(f'train set size: {len(train_data)}')
print(f'valid set size: {len(valid_data)}')
test_data = UserView('datasets/test.txt')
print(f'test set size: {len(test_data)}')
print(next(iter(train_data)))2.数据预处理
label2idx = {
"动力": 0,
"价格": 1,
"内饰": 2,
"配置": 3,
"安全性": 4,
"外观": 5,
"操控": 6,
"油耗": 7,
"空间": 8,
"舒适性": 9
}
len_label = len(label2idx)
# jupyter notebook下载预训练bert模型
!git clone https://www.modelscope.cn/tiansz/bert-base-chinese.gitimport torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from torch.utils.data import DataLoader
tokenizer = AutoTokenizer.from_pretrained("./bert-base-chinese")
def collate_func(batch):
texts, labels = [], []
for item in batch:
texts.append(item['text'])
# label 全部转为 onehot
label_ids = [0] * len_label
for lab in item['theme_label']:
if lab in label2idx:
label_ids[label2idx[lab]] = 1
labels.append(label_ids)
inputs = tokenizer(texts, max_length=128, padding="max_length", truncation=True, return_tensors="pt")
inputs["labels"] = torch.tensor(labels)
return inputs
trainloader = DataLoader(train_data, batch_size=32, shuffle=True, collate_fn=collate_func)
validloader = DataLoader(valid_data, batch_size=64, shuffle=False, collate_fn=collate_func)
testloader = DataLoader(test_data, batch_size=64, shuffle=False, collate_fn=collate_func)
3.创建模型和优化器
local_model_path = "./bert-base-chinese"
model = AutoModelForSequenceClassification.from_pretrained(local_model_path, num_labels=len_label, problem_type="multi_label_classification")
if torch.cuda.is_available():
model.cuda()
from transformers import AdamW, get_linear_schedule_with_warmup
EPOCHS = 3
optimizer = AdamW(model.parameters(), lr=2e-5, eps=1e-8) # 优化器
total_steps = len(trainloader) * EPOCHS # 训练步数
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=len(trainloader)//2,
num_training_steps=total_steps) # 调度器4.构建评价指标(F1、recall、precise以及acc)
from sklearn.metrics import f1_score, precision_score, accuracy_score, recall_score
import torch
import numpy as np
threshold = 0.5
def preprocess(preds, labels):
if torch.is_tensor(preds):
predictions = preds.detach().cpu()
# first, apply sigmoid on predictions which are of shape (batch_size, num_labels)
sigmoid = torch.nn.Sigmoid()
probs = sigmoid(torch.Tensor(predictions))
# next, use threshold to turn them into integer predictions
y_pred = np.zeros(probs.shape)
y_pred[np.where(probs >= threshold)] = 1
if torch.is_tensor(labels):
y_true = labels.detach().cpu()
return y_pred, y_true
def multi_label_metrics(predictions, labels):
y_pred, y_true = preprocess(predictions, labels)
f1_macro_average = f1_score(y_true=y_true, y_pred=y_pred, average='macro')
precision = precision_score(y_true, y_pred, average='macro')
recall = recall_score(y_true=y_true, y_pred=y_pred, average='macro')
accuracy = accuracy_score(y_true, y_pred)
# return as dictionary
metrics = {'f1': f1_macro_average,
'precision': precision,
'recall': recall,
'accuracy': accuracy}
return metrics
5.训练(tensorboardX追踪)
def evaluate(model, datasets="val"):
# 第七步:模型测试,计算准确度,处理逻辑和训练差不多
device = "cuda" if torch.cuda.is_available() else "cpu"
model.eval()
total_loss = 0
preds = []
labels = []
loader = validloader
if datasets == "test":
loader = testloader
for batch in loader: # 加载测试集DataLoader
batch_data = {key: data.to(device) for key, data in batch.items()}
batch_data["labels"] = batch_data["labels"].to(torch.float)
with torch.no_grad():
outputs = model(**batch_data)
loss = outputs.loss
total_loss += loss.item()
logits = outputs.logits
preds.append(logits)
labels.append(batch_data["labels"])
# 将列表中的张量合并成一个大的张量
all_preds = torch.cat(preds, dim=0)
all_labels = torch.cat(labels, dim=0)
report = multi_label_metrics(all_preds, all_labels)
avg_loss = total_loss / len(loader)
report["loss"] = avg_loss
return reportfrom tensorboardX import SummaryWriter
best_model_path = './best_model' # 最优模型训练结果的保存路径
device = "cuda" if torch.cuda.is_available() else "cpu"
max_grad_normal = 1.0 # 最大标准化梯度
evaluate_steps = 20
global_steps = 0
metric_used_for_best = "f1"
best_mertics = {}
tensorboardx_witer = SummaryWriter(logdir="./tensor_board")
stop_flag = False # 记录是否效果提升
last_improve = 0 # 记录上次验证集loss下降的batch数
require_improvement = 1000
for epoch in range(EPOCHS):
print(f"Epoch: {epoch}")
model.train() # 第一步:将模型设置为训练模式
for step, batch in enumerate(trainloader): # 第二步:加载训练集DataLoader
batch_data = {key: data.to(device) for key, data in batch.items()}
batch_data["labels"] = batch_data["labels"].to(torch.float)
model.zero_grad()
outputs = model(**batch_data) # 第三步:将输入数据传递给模型,得到模型的输出
loss = outputs.loss # 第四步:提取出损失值,用于后续的反向传播
# total_train_loss += loss.item()
loss.backward() # 第五步:进行反向传播,计算梯度
torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_normal)
optimizer.step()
scheduler.step()
# 评估算法/打印日志/存储模型, 1个epoch/到达保存的步数
if (global_steps % evaluate_steps == 0) or (step == len(trainloader)-1):
# 是否早停
if global_steps - last_improve > require_improvement:
# 验证集loss超过1000batch没下降,结束训练
print("No optimization for a long time, auto-stopping...")
stop_flag = True
break
train_pred, train_true = preprocess(outputs.logits, batch_data["labels"])
train_acc = accuracy_score(train_true, train_pred)
report = evaluate(model)
print(f"Step: {step}")
msg = 'Global steps: {0:>6}, Train Loss: {1:>5.2}, Train Acc: {2:>6.2%}, Val Loss: {3:>5.2}, Val Acc: {4:>6.2%}'
print(msg.format(global_steps, loss.item(), train_acc, report["loss"], report["accuracy"]))
# loss,acc的曲线
tensorboardx_witer.add_scalar("train/loss", loss.item(), global_steps)
tensorboardx_witer.add_scalar("train/accuracy", train_acc, global_steps)
for k, v in report.items():
if k in ["accuracy", "loss"]:
tensorboardx_witer.add_scalar("val/" + k, v, global_steps)
if report[metric_used_for_best] > best_mertics.get(metric_used_for_best, 0):
best_mertics = report
last_improve = global_steps
# 保存模型
model.save_pretrained(best_model_path)
# 转回训练模式
model.train()
if stop_flag:
break
global_steps = global_steps + 1
6.查看测试集的表现
best_model_path = './best_model' # 最优模型训练结果的保存路径
best_model = AutoModelForSequenceClassification.from_pretrained(
best_model_path, num_labels=len_label, problem_type="multi_label_classification")
if torch.cuda.is_available():
best_model.cuda()
print(evaluate(best_model, "test"))理论解释
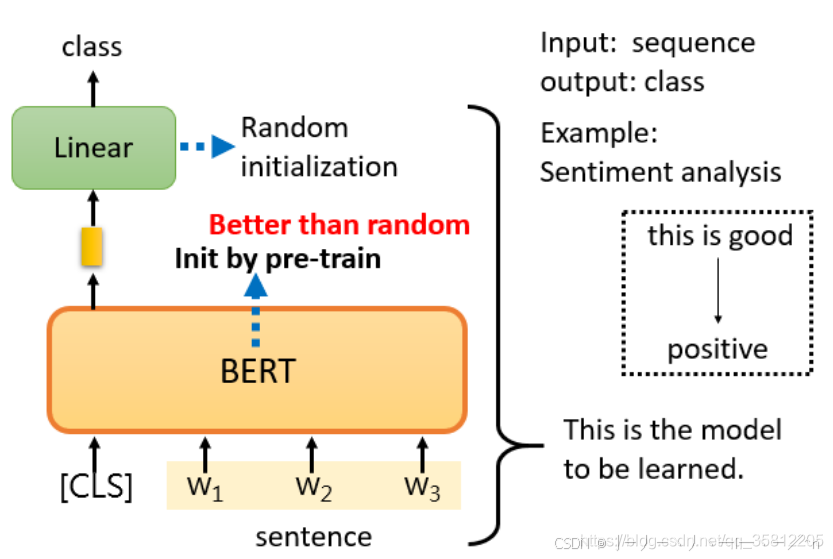
代码中定义包括linear层的头的预训练bert模型,其中bert部分用的是预训练的权重,分类头采用随机初始化。在数据集上微调分类层、bert层,由于是多标签分类(每个样本可能会有多个类别)采用BCEWithLogitsLoss。
小结
本文用训练bert实现了识别文本的多标签,指标采用macro平均的accuracy, precision, recall, F1。
喜欢这篇文章就点赞、关注和收藏吧!

















 3252
3252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









